

python网络数据采集笔记(二)
第五章
•媒体文件
在 Python 3.x 版本中, urllib.request.urlretrieve 可以根据文件的 URL 下载文件:
1 import os 2 from urllib.request import urlretrieve 3 from urllib.request import urlopen 4 from bs4 import BeautifulSoup 5 downloadDirectory = "downloaded" 6 baseUrl = "http://pythonscraping.com" 7 def getAbsoluteURL(baseUrl, source): 8 if source.startswith("http://www."): 9 url = "http://"+source[11:] 10 elif source.startswith("http://"): 11 url = source 12 elif source.startswith("www."): 13 url = source[4:] 14 url = "http://" + source 15 else: 16 url = baseUrl + "/" + source 17 if baseUrl not in url: 18 return None 19 return url 20 21 def getDownloadPath(baseUrl, absoluteUrl, downloadDirectory): 22 path = absoluteUrl.replace("www.", "") 23 24 path = path.replace(baseUrl, "") 25 path = downloadDirectory + path 26 directory = os.path.dirname(path) 27 if not os.path.exists(directory): 28 os.makedirs(directory) 29 return path 30 31 html = urlopen("http://www.pythonscraping.com") 32 bsObj = BeautifulSoup(html, "lxml") 33 downloadList = bsObj.findAll(src=True) 34 for download in downloadList: 35 fileUrl = getAbsoluteURL(baseUrl, download["src"]) 36 if fileUrl is not None: 37 print(fileUrl) 38 urlretrieve(fileUrl, getDownloadPath(baseUrl, fileUrl, downloadDirectory))
Output:
1 http://pythonscraping.com/misc/jquery.js?v=1.4.4 2 http://pythonscraping.com/misc/jquery.once.js?v=1.2 3 http://pythonscraping.com/misc/drupal.js?pa2nir 4 http://pythonscraping.com/sites/all/themes/skeletontheme/js/jquery.mobilemenu.js?pa2nir 5 http://pythonscraping.com/sites/all/modules/google_analytics/googleanalytics.js?pa2nir 6 http://pythonscraping.com/sites/default/files/lrg_0.jpg 7 http://pythonscraping.com/img/lrg%20(1).jpg
说明:其实这里只下载了最后一个链接的内容。将
urlretrieve(fileUrl, getDownloadPath(baseUrl, fileUrl, downloadDirectory))缩进进入for循环。
会显示错误
1 tfp = open(filename, 'wb') 2 OSError: [Errno 22] Invalid argument: 'downloaded/misc/jquery.js?v=1.4.4'
这里是为什么?先记录一下。
初步判断应该是未指明文件类型,比如
lrg%20(1).jpg之类的,txt,html...
•将HTML表格数据存储到CSV
CSV(Comma-Separated Values,逗号分隔值)是存储表格数据的常用文件格式。
每一行都用一个换行符分隔,列与列之间用逗号分隔(因此也叫“逗号分隔值”)。 CSV 文件还可以用 Tab 字符或其他字符分隔行,但是不太常见,用得不多。 Python 的 csv 库可以非常简单地修改 CSV 文件,甚至从零开始创建一个 CSV 文件:
1 import csv 2 csvFile = open("C:\\Users\dell\\PycharmProjects\\untitled1\\0628\\csv_test", 'w+') 3 try: 4 writer = csv.writer(csvFile) 5 writer.writerow(('number', 'number plus 2', 'number times 3')) 6 for i in range(10): 7 writer.writerow((i, i+2, i*2)) 8 finally: 9 csvFile.close()
Output:
number,number plus 2,number times 3 0,2,0 1,3,2 2,4,4
网络数据采集的一个常用功能就是获取 HTML 表格并写入 CSV 文件。
采集https://www.runoob.com/html/html-tables.html的第一个表格。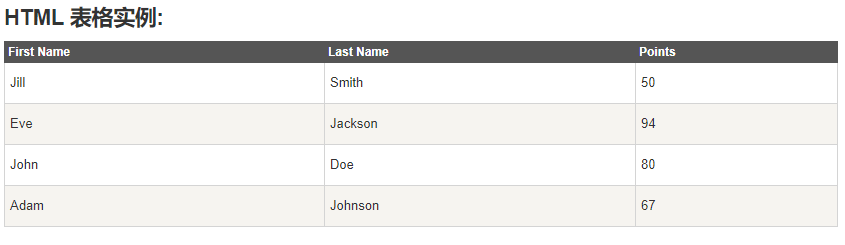
其网页源码如图:

上代码
1 import csv 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 5 html = urlopen('https://www.runoob.com/html/html-tables.html') 6 bs = BeautifulSoup(html, 'html.parser') 7 8 table = bs.findAll('table',{'class':'reference'})[0] 9 rows = table.findAll('tr') 10 11 csvFile = open('C:\\Users\dell\\PycharmProjects\\untitled1\\0628\\csv_test1', 'wt+') 12 writer = csv.writer(csvFile) 13 try: 14 for row in rows: 15 csvRow = [] 16 for cell in row.findAll(['td', 'th']): 17 csvRow.append(cell.get_text()) 18 writer.writerow(csvRow) 19 finally: 20 csvFile.close()
Output:
First Name,Last Name,Points Jill,Smith,50 Eve,Jackson,94 John,Doe,80 Adam,Johnson,67
优美胜于丑陋(Python 以编写优美的代码为目标)//
明了胜于晦涩(优美的代码应当是明了的,命名规范,风格相似)//
简洁胜于复杂(优美的代码应当是简洁的,不要有复杂的内部实现)//
复杂胜于凌乱(如果复杂不可避免,那代码间也不能有难懂的关系,要保持接口简洁)//
扁平胜于嵌套(优美的代码应当是扁平的,不能有太多的嵌套)//
间隔胜于紧凑(优美的代码有适当的间隔,不要奢望一行代码解决问题)//
可读性很重要(优美的代码是可读的)//
即便假借特例的实用性之名,也不可违背这些规则(这些规则至高无上)//
不要包容所有错误,除非你确定需要这样做(精准地捕获异常,不写 except:pass 风格的代码)//
当存在多种可能,不要尝试去猜测‘而是尽量找一种,最好是唯一一种明显的解决方案(如果不确定,就用穷举法)。虽然这并不容易,因为你不是 Python 之父(这里的 Dutch 是指 Guido )//
做也许好过不做,但不假思索就动手还不如不做(动手之前要细思量)//
如果你无法向人描述你的方案,那肯定不是一个好方案;反之亦然(方案测评标准)//
命名空间是一种绝妙的理念,我们应当多加利用(倡导与号召)//
