内置CRC于文本文件中的方法
- 0、前言
首先,这是一件很无聊的事,把CRC的值内置到文本文件中什么的。
顺便一提,之前在csdn写的那些文章,由于那个网站的广告太多了就不想在那写了,就先搬过来看看(好像文章中有很多公式不见了,想看原文的话,去那个网站翻翻吧,那些公式敲起来贼麻烦,懒得补了)。
之前写过两篇文章,分别叫《指定CRC反构数据》、《内置CRC于hex程序中的方法》,前者针对bin文件(虽支持文本文件,但会产生乱码),后者针对hex文件(暂不支持数字信号处理器,也就是输出给dsp使用的hex文件)。
再顺带一提,当时我并没有给出我设计的针对hex文件的CRC算法。首先说说“SEGGER J-Flash”软件给出的CRC算法,那个软件使用的算法,是按照用户选择的MCU型号,得到Flash的首地址与容量,将hex文件未使用的部分全部填充0xFF,转换成bin文件之后,以bin模式计算标准CRC32,得到的结果作为hex文件的CRC。我不使用这个的理由,在于用户必须选择MCU型号,这是用户的负担,也是检验码软件的负担。用一个相同的hex文件,选择不同Flash容量的MCU型号,算出的CRC会不一样。J-Flash软件的更新频繁,很大程度上是为了扩充新MCU的Flash容量之类的数据。
我使用的方法,则是分别对有效地址和有效数据计算CRC32,但是模型稍有变动,不影响内置保持不变的性质。
例如,有这么个文件:

分别取出有效地址,跳过窟窿字节,32比特拆成4个字节时,高字节在前,低字节在后,排列如下:
08 00 00 00
08 00 00 01
08 00 00 03
08 00 00 04
08 00 00 05
08 00 00 08
08 00 00 09
08 00 00 0A
08 00 00 0B
08 00 00 0C
08 00 00 0D
再分别取出有效数据,同样跳过窟窿字节,排列如下:
12 34 56 78 90 AA BB CC DD EE FF
分别计算两个的CRC,异或之后作为hex文件的CRC。
- 1、内置CRC于bin文件中的方法
太简单啦,通过《指定CRC反构数据》里面的方法,已经可以做到了。
例如这么个文件:

这个文件有19个字节,CRC32是FA6C02E4。我想在第7个字节后边添加CRC,CRC占用8个字节的字符,CRC后添加4个字节的尾巴,称为平衡算子,初值暂时写零,平衡算子之后是原有的剩余12个字节。平衡算子的目的,是抵消填充物,对整体CRC值的影响。
临时文件共计31字节,内容如下:

之后,使用《指定CRC反构数据》里面的方法,填充4个字节的平衡算子,得到的新文件如下:

算一下这个新文件的CRC32就是FA6C02E4,与原文件一致。
- 2、内置CRC于bin文件中的烦恼
其实上一节给出的文件也是一个文本文件,里面是文字且无乱码,但是串进内置CRC后,会出现乱码,实际上,用文本编辑器打开就会有乱码:
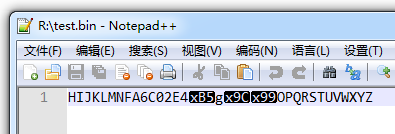
别跟我说什么选的编码方式不对什么的,这玩意就不该给人看到。假设我把CRC和平衡算子放置到某个C语言的源文件中,用注释符括起来,那么就有这样的风险,平衡算子里面出现换行符,甚至出现匹配为注释结尾符,那甚至会破坏那个源文件的语法结构。。。所以有必要让平衡算子“消失”。
想要让文字消失,最好的办法,就是使用空格,或者类似于空格的不可见字符。我找到了一对很适合拿来用的不可见字符,由于不可见,所以这里仅仅给出其UTF-8编码:分别是E2 80 8C、E2 80 8D。这一对编码有个两个特点:首先是不可见,不但不可见,甚至连宽度都是零;然后是近似,二者有且只有1个比特的差别,只要叠32次,就有可能构造出有效的平衡算子。根据我的调查,E2 80 8C被称为ZERO WIDTH NON-JOINER,E2 80 8D被称为ZERO WIDTH JOINER,这两个控制字符放在注释里,不但是隐形的,而且不会破坏源文件的语法。
当然,唯一的限制就是,原文本文件最好要使用UTF-8编码,才能支持这两个字符。用GB2312编码或者用UTF-16编码什么的,后续思路是类似的,但是要想办法找到一对空白字符,两者有且只有1个比特的差别就行。统一使用UTF-8编码并不是什么过分的要求,后文只针对UTF-8编码。
- 3、构建文本文件的平衡算子
我提出一个假说:在二进制文件中(尺寸4字节以上),指定连续的32比特,通过穷举其所有可能的组合,总有一种组合满足希望的CRC32。这个假说是成立的,因为那篇文章中已经推演过了。
我再提出第二个假说:在二进制文件中(尺寸4字节以上),指定任意的32比特,通过穷举其所有可能的组合,总有一种组合满足希望的CRC32。这个假说不成立,因为TruncPoly=0x104C11DB7,写成二进制模式就是1 0000 0100 1100 0001 0001 1101 1011 0111,只要按照这个模式中的1的位置,指定15个比特,同时反转这15个比特的值,就可以保证CRC不变。因此,在这15个比特的基础上,再随便找其他17个比特,凑齐32比特,穷举时,结果就会出现冲突。
虽然第二个假说不成立,但是没准我的运气不错,我选择的32个比特,满足我的目的呢?根据上一节提到的两个字符:E2 80 8C、E2 80 8D,叠32次,共计96字节,也就是24比特叠32次,共计768比特。将每3个字节的最后一个字节的第0位,共计32比特拿出来,作为我的平衡算子。
之后就是求解平衡算子。这个与连续的32比特平衡算子不同,很难用数学方法推演出来。数学高手可以尝试下。。。
嘛,毕竟2的32次方并不是很大的数,只要找到每个比特变化,对应的平衡算子的变化,制成查找表格就好啦。毕竟是穷举法,这个方法对CRC64是绝望的,对CRC16就很友好了。
说一下平很算子的解法。把字符E2 80 8C重复32次,作为原始素材。用0作为余数,从原始素材最右边,向左边做CRC的逆运算,得到初值rem。之后,仍然用0作为余数,但是要改变原始素材中,被选为平衡算子的那32个比特,从新的素材最右边,向左边做CRC的逆运算,得到新的初值rem。不断重复这个过程,直到遍历完成全部的2的32次方种组合。我们关注的余数有33个,首先是0x00000000,这个是基准,这意味着用那个平衡算子对0做CRC运算,得到的结果仍然是0。之后是0x00000001、0x00000002、0x00000004、0x00000008、……、0x80000000,共计32个数,其规律是,都是2的整幂,这个想法是理所当然的,只要组合这32种情况,就能拟合出任意的rem变化。
当然,我们关注的并不是这些平衡算子的值,我们只关注后边的32个值,相对于基准值的变化。在rem扫描平衡算子之前的部分之后,我们无法更改rem的值,但是我们可以对平衡算子之后的部分求取CRC的逆,得到rem的变化。只要找到了这些变化的一一对应关系,就可以组合出最终的平衡算子。
- 4、求取破解表
#include <stdint.h> #include <stdio.h> static uint32_t s_gen_table[0x100] = { 0 }; static uint32_t s_inv_table[0x100] = { 0 }; static uint32_t s_empty = 0; static uint32_t s_crack[0x20] = { 0 }; void init_table() { for (int i = 0; i < 0x100; ++i) { uint32_t gen = i; uint32_t inv = i << 24; for (int j = 0; j < 8; ++j) { gen = (gen >> 1) ^ (gen & 0x00000001 ? 0xEDB88320 : 0); inv = (inv << 1) ^ (inv & 0x80000000 ? 0xDB710641 : 0); } s_gen_table[i] = gen; s_inv_table[i] = inv; } return; } void crack_search(uint32_t rem = 0, size_t deep = 0, uint32_t value = 0) { if (deep == 6) { printf ("."); } if (deep == 32) { if (rem == 0) { s_empty = value; } else if (((rem - 1U) & rem) == 0) { for (size_t i = 0; i < 32; i++) { if ((rem >> i) == 1U) { s_crack[i] = value; break; } } } return; } rem = (rem << 8U) ^ s_inv_table[rem >> 24U]; rem = (rem << 8U) ^ s_inv_table[rem >> 24U]; rem = (rem << 8U) ^ s_inv_table[rem >> 24U]; crack_search (rem ^ 0x8C80E2, deep + 1, value); crack_search (rem ^ 0x8D80E2, deep + 1, value ^ (0x80000000U >> deep)); return; } int main(int argc, char *argv[]) { init_table (); crack_search (); printf ("\n"); for (size_t i = 0; i < 0x20; i++) { printf ("0x%08X, ", s_crack[i] ^ s_empty); if (i % 4 == 3) { printf ("\n"); } } return 0; }
这是一个递归二叉搜索,只是为了重复利用穷举过程的中间结果。执行之后,就可得到破解表。if (deep == 6)是为了显示穷举进度。
0x160E142B, 0x5972F1D7, 0xBE7DBE2F, 0xC5804111, 0x1A13ACF2, 0x016AD10A, 0xCD8E8D74, 0x1A45AE34, 0x77B133B2, 0x78CF4017, 0x51802E15, 0xE3D30532, 0xBA09386A, 0x1A5D560A, 0x39F02BC8, 0x413B6A57, 0x00000001, 0xFB359B60, 0x7AAE788F, 0x28209B40, 0x656482F8, 0xCDA12D7A, 0x3B206904, 0x3CBC58E5, 0x2C1C2856, 0xB2E5E3AE, 0x6E0C5043, 0x99F7AE3F, 0x342759E4, 0x02D5A214, 0x89EA36F5, 0x348B5C68,
说明一下破解表的用途:
首先将CRC和初始平衡算子(就是将字符E2 80 8C重复32次,作为原始素材的平衡算子),用注释符包裹起来,放置在原有文件的任一行中。之后,求取平衡算子之前部分的rem,并用原始文件的CRC32的值,从文件结尾向前,求取CRC逆运算,直到越过平衡算子,得到后半部分的rem。理论上这两个rem如果一致,那么就表示,rem不需变化就可以连接上,新文件的CRC32与原始文件的CRC32就是一致的。但是这种概率很低,实际上两个rem之间,会有很多个比特是不同的,找出不同的比特,根据其占在第几位,对应出破解表的项。破解表中的值,是用来修正平衡算子的。遍历所有不同的比特,将其在对应破解表中的值找出,全部异或在一起,就是我们求出来的最终的平衡算子。
- 5、内置CRC于文本文件中
跟内置CRC于hex文件中一样,我希望将当前日期和时间一起内置在注释中,并通过求取平衡算子,保证新文件的CRC,与原有文件的CRC一致。
编译环境VS2015。测试文件为“R:\test.txt”,其内容与文章开头给出的“test.bin”一致,CRC32=FA6C02E4。
HIJKLMNOPQRSTUVWXYZ
测试代码如下:
#include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #ifdef WIN32 #include <malloc.h> #endif static const uint32_t CRACK_TABLE[0x20] = { 0x160E142B, 0x5972F1D7, 0xBE7DBE2F, 0xC5804111, 0x1A13ACF2, 0x016AD10A, 0xCD8E8D74, 0x1A45AE34, 0x77B133B2, 0x78CF4017, 0x51802E15, 0xE3D30532, 0xBA09386A, 0x1A5D560A, 0x39F02BC8, 0x413B6A57, 0x00000001, 0xFB359B60, 0x7AAE788F, 0x28209B40, 0x656482F8, 0xCDA12D7A, 0x3B206904, 0x3CBC58E5, 0x2C1C2856, 0xB2E5E3AE, 0x6E0C5043, 0x99F7AE3F, 0x342759E4, 0x02D5A214, 0x89EA36F5, 0x348B5C68, }; static uint32_t s_gen_table[0x100] = { 0 }; static uint32_t s_inv_table[0x100] = { 0 }; void init_table() { for (int i = 0; i < 0x100; ++i) { uint32_t gen = i; uint32_t inv = i << 24; for (int j = 0; j < 8; ++j) { gen = (gen >> 1) ^ (gen & 0x00000001 ? 0xEDB88320 : 0); inv = (inv << 1) ^ (inv & 0x80000000 ? 0xDB710641 : 0); } s_gen_table[i] = gen; s_inv_table[i] = inv; } return; } bool self_crc32_utf8(const char *filename, int line = 0) { #ifdef WIN32 #define fseeko64 _fseeki64 #define ftello64 _ftelli64 #define localtime_r(rawtime, timeinfo) localtime_s (timeinfo, rawtime) #endif if (filename == nullptr) { return false; } if (filename[0] == '\0') { return false; } int filename_len = strlen (filename); char *tmp_filename = (char *) alloca (filename_len + 5); snprintf (tmp_filename, filename_len + 5, "%s.tmp", filename); FILE *dst_stream = fopen (tmp_filename, "wb"); if (dst_stream == nullptr) { return false; } FILE *src_stream = fopen (filename, "rb"); if (src_stream == nullptr) { fclose (dst_stream); remove (tmp_filename); return false; } uint32_t new_rem = 0xFFFFFFFF; int64_t new_pos = -1; int line_i = -1; uint32_t rem = 0xFFFFFFFF; bool cr_flag = false; // "\r" bool lf_flag = false; // "\n" bool last_flag = false; // last == '\r' bool error_flag = false; enum { BUF_SIZE = 0x400 }; unsigned char buf[BUF_SIZE] = {}; size_t text_len = 0; while (size_t read_len = fread (buf + text_len, 1, BUF_SIZE - text_len, src_stream)) { text_len += read_len; size_t valid_len = 0; if (line_i == -1) { line_i = 0; if (text_len >= 3 && buf[0] == 0xEF && buf[1] == 0xBB && buf[2] == 0xBF) { valid_len += 3; } } while (valid_len < text_len || line_i == line) { if (line_i == line) { ++line_i; if (valid_len > 0) { size_t write_len = fwrite (buf, 1, valid_len, dst_stream); if (write_len != valid_len) { error_flag = true; break; } for (size_t i = 0; i < valid_len; i++) { rem = (rem >> 8U) ^ s_gen_table[(rem ^ buf[i]) & 0xFFU]; } text_len -= valid_len; if (text_len > 0) { memmove (buf, buf + valid_len, text_len); } valid_len = 0; } new_rem = rem; new_pos = ftello64 (dst_stream); int seek_ans = fseeko64 (dst_stream, 144, SEEK_CUR); if (seek_ans != 0) { error_flag = true; break; } continue; } unsigned char ch0 = buf[valid_len]; if (last_flag) { last_flag = false; ++line_i; if (ch0 == '\n') { lf_flag = true; ++valid_len; } continue; } if (ch0 == '\n') { lf_flag = true; ++line_i; ++valid_len; continue; } if (ch0 == '\r') { cr_flag = true; last_flag = true; ++valid_len; continue; } last_flag = false; if (ch0 > 0 && ch0 < 0x80U) { ++valid_len; continue; } if (valid_len + 1U >= text_len) { break; } unsigned char ch1 = buf[valid_len + 1U]; if ((ch1 & 0xC0U) != 0x80U) { error_flag = true; break; } if ((ch0 & 0xE0U) == 0xC0U) { unsigned value = ((ch0 & 0x1FU) << 6U) | ((ch1 & 0x3FU) << 0U); if (value < 0x80U) { error_flag = true; break; } valid_len += 2U; continue; } if (valid_len + 2U >= text_len) { break; } unsigned char ch2 = buf[valid_len + 2U]; if ((ch2 & 0xC0U) != 0x80U) { error_flag = true; break; } if ((ch0 & 0xF0U) == 0xE0U) { unsigned value = ((ch0 & 0x0FU) << 12U) | ((ch1 & 0x3FU) << 6U) | ((ch2 & 0x3FU) << 0U); if (value < 0x800U || (value & 0xF800U) == 0xD800U) { error_flag = true; break; } valid_len += 3; continue; } if (valid_len + 3U >= text_len) { break; } unsigned char ch3 = buf[valid_len + 3U]; if ((ch3 & 0xC0U) != 0x80U) { error_flag = true; break; } if ((ch0 & 0xF8U) == 0xF0U) { unsigned value = ((ch0 & 0x07U) << 18U) | ((ch1 & 0x3FU) << 12U) | ((ch2 & 0x3FU) << 6U) | ((ch3 & 0x3FU) << 0U); if (value < 0x10000U || value > 0x10FFFFU) { error_flag = true; break; } valid_len += 4; continue; } error_flag = true; break; } if (error_flag) { break; } if (valid_len == 0) { continue; } size_t write_len = fwrite (buf, 1, valid_len, dst_stream); if (write_len != valid_len) { error_flag = true; break; } for (size_t i = 0; i < valid_len; i++) { rem = (rem >> 8U) ^ s_gen_table[(rem ^ buf[i]) & 0xFFU]; } text_len -= valid_len; if (text_len > 0) { memmove (buf, buf + valid_len, text_len); } } if (error_flag || text_len > 0) { fclose (src_stream); fclose (dst_stream); remove (tmp_filename); return false; } const char *head0 = nullptr; const char *tail1 = nullptr; const char *tail2 = nullptr; int crack_pos = 0; if (new_pos >= 0) { fseeko64 (dst_stream, new_pos, SEEK_SET); head0 = "/*"; if (cr_flag && lf_flag) { tail1 = " "; tail2 = "*/\r\n"; crack_pos = 44; } else if (cr_flag) { tail1 = " "; tail2 = "*/\r"; crack_pos = 45; } else { tail1 = " "; tail2 = "*/\n"; crack_pos = 45; } } else // if (new_pos < 0) { if (cr_flag && lf_flag) { head0 = "\r\n/*"; tail1 = " "; tail2 = "*/"; } else if (cr_flag) { head0 = "\r/*"; tail1 = " "; tail2 = "*/"; } else { head0 = "\n/*"; tail1 = " "; tail2 = "*/"; } crack_pos = 46; } time_t rawtime = time (nullptr); struct tm timeinfo = {}; localtime_r (&rawtime, &timeinfo); rem ^= 0xFFFFFFFFU; snprintf ((char *)buf, BUF_SIZE, "%s %04d-%02d-%02d %.3s %02d:%02d:%02d CRC=0x%08X %s", head0, timeinfo.tm_year + 1900, timeinfo.tm_mon + 1, timeinfo.tm_mday, 3 * timeinfo.tm_wday + "SunMonTueWedThuFriSat", timeinfo.tm_hour, timeinfo.tm_min, timeinfo.tm_sec, rem, tail1); for (size_t i = 0; i < 96; i += 3) { buf[crack_pos + i + 0] = 0xE2; buf[crack_pos + i + 1] = 0x80; buf[crack_pos + i + 2] = 0x8C; } memcpy (buf + crack_pos + 96, tail2, 48 - crack_pos); rem = new_rem; for (int i = 0; i < crack_pos; i++) { new_rem = (new_rem >> 8U) ^ s_gen_table[(new_rem ^ buf[i]) & 0xFFU]; } for (int i = 143; i >= crack_pos; i--) { rem = (rem << 8U) ^ s_inv_table[rem >> 24U]; rem ^= buf[i]; } rem ^= new_rem; uint32_t mask = 0; for (size_t i = 0; i < 32; i++) { if ((rem & (1U << i)) != 0) { mask ^= CRACK_TABLE[i]; } } for (size_t i = 0; i < 96; i += 3) { if ((mask & 1U) != 0) { buf[crack_pos + i + 2] = 0x8D; } mask >>= 1U; } size_t write_len = fwrite (buf, 1, 144, dst_stream); if (write_len != 144) { fclose (src_stream); fclose (dst_stream); remove (tmp_filename); return false; } fclose (src_stream); fclose (dst_stream); #ifdef WIN32 #undef fseeko64 #undef ftello64 #undef localtime_r #endif return true; } int main(int argc, char *argv[]) { init_table (); self_crc32_utf8 ("R:\\test.txt"); return 0; }
函数self_crc32_utf8的第二个参数,用来表示希望把注释插到第几行。没有对应行数则插到文件结尾。
运行得到的文件“R:\test.txt.tmp”,内容如下:
/* 2019-01-04 Fri 20:51:47 CRC=0xFA6C02E4 */ HIJKLMNOPQRSTUVWXYZ
其中E2 80 8C、E2 80 8D可能被网站过滤掉了看不到。其CRC32仍然是FA6C02E4。
以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号