
R 语言描述性分析
1. 数字特征
随即构造一个正态样本,研究它的数字特征
# 构造数据,随机生成一个正态分布
X <- rnorm(10,0,1)
1.1 样本均值
mean(X)
> mean(X)
[1] -0.0586382
加入截尾参数 trim,该参数默认为0
mean(X, trim = 0.1) # 去掉 X 向量排序后的 两端数据的 10%,
> mean(X, trim = 0.1) # 去掉 X 向量排序后的 两端数据的 10%,
[1] -0.1577639
# 等价于
mean(sort(X)[2:9])
> mean(sort(X)[2:9])
[1] -0.1577639
如果数据有缺失值,那么可以使用 na.rm 参数,默认为“False”,例如
Y <- X
Y[3] <- NaN
Y
> Y
[1] 0.439891287 -0.004540984 NaN 0.075344112 -0.103447416
[6] 0.145027671 -1.860503334 -1.443864860 0.658675667 -1.029196428
mean(Y, na.rm = T)
> mean(Y, na.rm = T)
[1] -0.3469571
Y[3] <- 0
sum(Y)/(length(Y)-1)
> sum(Y)/(length(Y)-1)
[1] -0.3469571
# 因此它的作用是直接消除缺失项,同时项数减1
1.2 样本方差
var(X)
> var(X)
[1] 1.518705
也可以用var()计算两样本的协方差
Y <- rnorm(10,0,1)
var(X,Y)
> var(X,Y)
[1] -0.5049783
# 等价于
cov(X,Y)
> cov(X,Y)
[1] -0.5049783
与 mean() 一样,也有 na.rm 参数
Y[3] <- NaN
var(Y, na.rm = T)
> var(Y, na.rm = T)
[1] 0.9002631
1.3 标准差
sd(X)
> sd(X)
[1] 1.232357
Y <- rnorm(10,0,1)
Y[3] <- NaN
sd(Y, na.rm = T)
> sd(Y, na.rm = T)
[1] 0.8890223
1.4 中位数
median(X)
> median(X)
[1] 0.03540156
median(Y, na.rm = T)
> median(Y, na.rm = T)
[1] 0.4815701
1.5 分位数
quantile(X)
> quantile(X)
0% 25% 50% 75% 100%
-1.86050333 -0.79775917 0.03540156 0.36617538 2.53623226
# 0.25 分位数
quantile(X, probs = 0.25)
> quantile(X, probs = 0.25)
25%
-0.7977592
# 0.75 分位数
quantile(X, probs = 0.75)
> quantile(X, probs = 0.75)
75%
0.3661754
# na.rm 用法
quantile(Y, na.rm = T)
> quantile(Y, na.rm = T)
0% 25% 50% 75% 100%
-1.3108392 -0.1681030 0.4815701 0.6309903 1.6807826
# names 用法
quantile(X, probs = 0.25, names = F)
> quantile(X, probs = 0.25, names = F)
[1] -0.7977592
1.6 极差
# 最大值
max(X)
> max(X)
[1] 2.536232
# 最小值
min(X)
> min(X)
[1] -1.860503
# 极差
max(X) - min(X)
> max(X) - min(X)
[1] 4.396736
# range 函数
range(X) # 返回最小值和最大值构成的向量
> range(X) # 返回最小值和最大值构成的向量
[1] -1.860503 2.536232
range(X)[2] - range(X)[1]
> range(X)[2] - range(X)[1]
[1] 4.396736
# 四分位极差(半极差)
quantile(X, 3/4) - quantile(X, 1/4)
> quantile(X, 3/4) - quantile(X, 1/4)
75%
1.163935
1.7 自定义数字特征函数
describe <- function(x){
R1 <- quantile(x, 3/4, name = F) - quantile(x, 1/4, name = F)
data.frame(
n = length(x),
max = max(x),
min = min(x),
R = max(x) - min(x),
R1 = R1,
mean = mean(x),
median = median(x),
var = var(x),
sd = sd(x)
)
}
describe(X)
> describe(X)
n max min R R1 mean median var
1 10 2.536232 -1.860503 4.396736 1.163935 -0.0586382 0.03540156 1.518705
sd
1 1.232357
2 常用的分布
2.1 正态分布
2.1.1 概率密度函数 dnorm(x, mean = 0, sd = 1, lower.tail = T)
dnorm(1, 0, 1)
> dnorm(1, 0, 1)
[1] 0.2419707
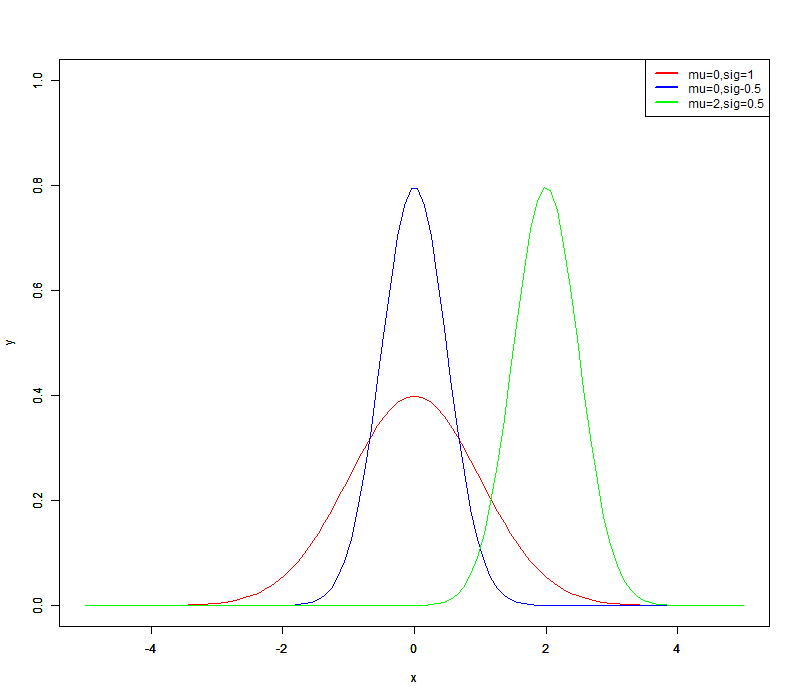
绘制标准正态分布概率密度函数图
x <- seq(-5, 5, length = 100)
y1 <- dnorm(x, 0, 1)
y2 <- dnorm(x, 0, 0.5)
y3 <- dnorm(x, 2, 0.5)
plot(x, y1, type = 'l', col = 'red', xlab = 'x', ylab = 'y', ylim = c(0,1))
par(new = TRUE)
plot(x, y2, type = 'l', col = 'blue', xlab = 'x', ylab = 'y', ylim = c(0,1))
par(new = TRUE)
plot(x, y3, type = 'l', col = 'green', xlab = 'x', ylab = 'y', ylim = c(0,1))
legend("topright", #图例位置为右上角
legend=c("mu=0,sig=1","mu=0,sig-0.5","mu=2,sig=0.5"), #图例内容
col=c("red","blue","green"), #图例颜色
lty=1,lwd=2) #图例大小
2.1.2 分布函数 pnorm(q, mean = 0, sd = 1, lower.tail = T)
pnorm(1, 0, 1)
> pnorm(1, 0, 1)
[1] 0.8413447
lower.tail 参数,默认为 TRUE,即作下尾运算 \(F(x)=P(X \leq x)\);若改为 FALSE,则表示 \(F(x)=P(X>x)\)
pnorm(1, 0, 1, lower.tail = FALSE)
> pnorm(1, 0, 1, lower.tail = FALSE)
[1] 0.1586553
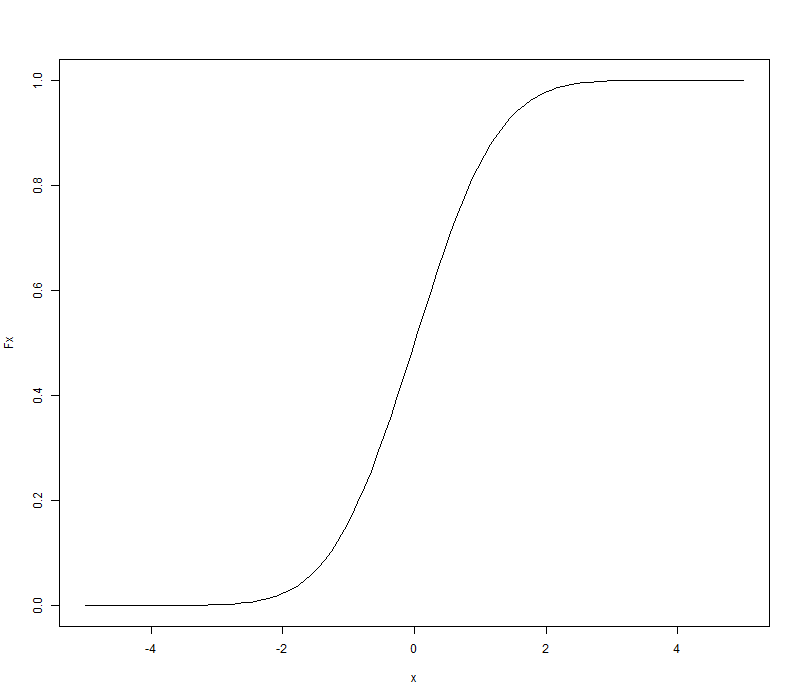
分布函数图像
Fx <- pnorm(x, 0, 1)
plot(x, Fx, type = 'l')
2.1.3 分位函数(默认下分位点)qnorm(p, mean = 0, sd = 1, lower.tail = T)
qnorm(0.3, 0, 1)
> qnorm(0.3, 0, 1)
[1] -0.5244005
q <- qnorm(0.3, 0, 1)
pnorm(q, 0, 1)
> pnorm(q, 0, 1)
[1] 0.3
1 - pnorm(q, 0, 1, lower.tail = F)
> 1 - pnorm(q, 0, 1, lower.tail = F)
[1] 0.3
## 也可以计算上分位点
qnorm(0.3, 0, 1, lower.tail = F)
> qnorm(0.3, 0, 1, lower.tail = F)
[1] 0.5244005
2.2 \(\mathcal{X}^2\)卡方分布
2.2.1 概率密度函数 dchisq(x, df, ncp = 0)
dchisq(1, df = 5)
> dchisq(1, df = 5)
[1] 0.08065691
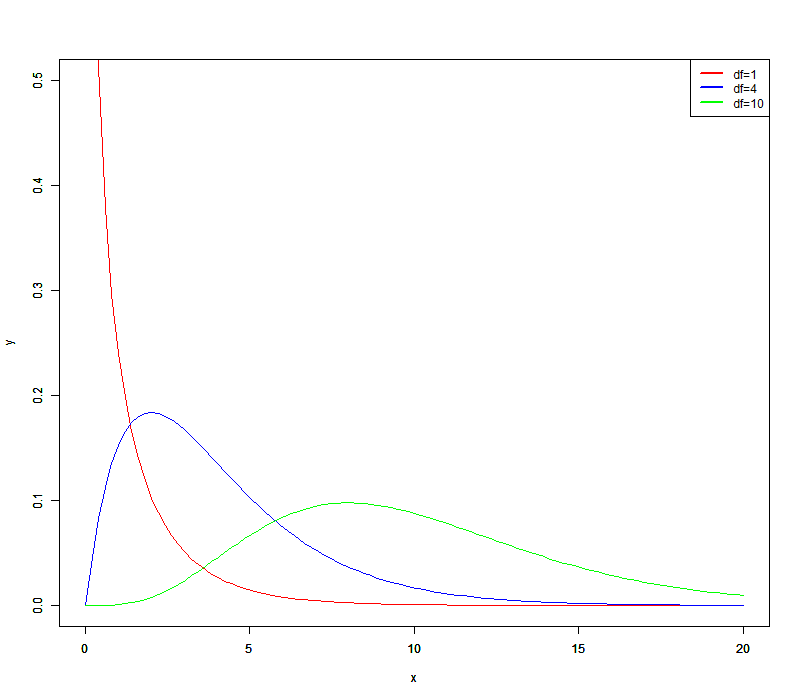
绘制密度函数图像
x <- seq(0, 20, length = 100)
y1 <- dt(x, df = 1)
y2 <- dt(x, df = 4)
y3 <- dt(x, df = 10)
plot(x, y1, type = 'l', col = 'red', xlab = 'x', ylab = 'y', ylim = c(0,0.5))
par(new = TRUE)
plot(x, y2, type = 'l', col = 'blue', xlab = 'x', ylab = 'y', ylim = c(0,0.5))
par(new = TRUE)
plot(x, y3, type = 'l', col = 'green', xlab = 'x', ylab = 'y', ylim = c(0,0.5))
legend("topright", #图例位置为右上角
legend=c("df=1","df=4","df=10"), #图例内容
col=c("red","blue","green"), #图例颜色
lty=1,
lwd=2
) #图例大小
2.2.2 分布函数 pchisq(q, df, ncp = 0, lower.tail = T)
pchisq(1, 5)
> pchisq(1, 5)
[1] 0.03743423
lower.tail 参数,默认为 TRUE,即作下尾运算 \(F(x)=P(X\leq x)\);若改为 FALSE,则表示 \(F(x)=P(X>x)\)
pchisq(1, 5, lower.tail = FALSE)
> pchisq(1, 5, lower.tail = FALSE)
[1] 0.9625658
分布函数图像
Fx <- pchisq(x, 5)
plot(x, Fx, type = 'l')
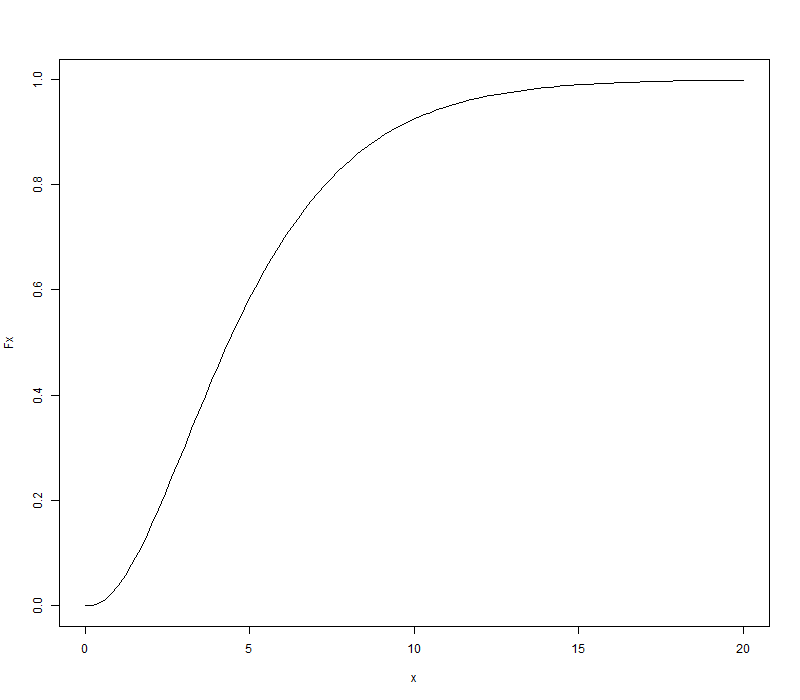
2.2.3 分位函数 qchisq(p, df, ncp = 0, lower.tail = T)
qchisq(0.3, 5)
> qchisq(0.3, 5)
[1] 2.999908
q <- qchisq(0.3, 5)
pchisq(q, 5)
> pchisq(q, 5)
[1] 0.3
1 - pchisq(q, 5, lower.tail = F)
> 1 - pchisq(q, 5, lower.tail = F)
[1] 0.3
## 也可以计算上分位点
qnorm(0.3, 5, lower.tail = F)
> qnorm(0.3, 5, lower.tail = F)
[1] 5.524401
2.3 t分布
2.3.1 概率密度函数 dt(x, df, ncp = 0)
dt(1, df = 5)
> dt(1, df = 5)
[1] 0.2196798
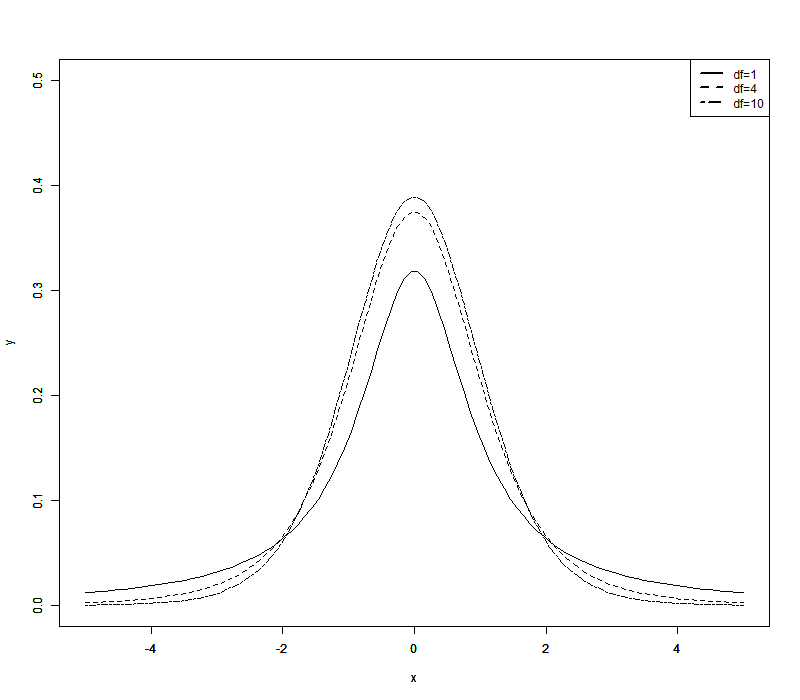
绘制密度函数图像
x <- seq(-5, 5, length = 100)
y1 <- dt(x, df = 1)
y2 <- dt(x, df = 4)
y3 <- dt(x, df = 10)
plot(x, y1, type = 'l', lty = 1, xlab = 'x', ylab = 'y', ylim = c(0,0.5))
par(new = TRUE)
plot(x, y2, type = 'l', lty = 2, xlab = 'x', ylab = 'y', ylim = c(0,0.5))
par(new = TRUE)
plot(x, y3, type = 'l', lty = 6, xlab = 'x', ylab = 'y', ylim = c(0,0.5))
legend("topright", #图例位置为右上角
legend=c("df=1","df=4","df=10"), #图例内容
# col=c("red","blue","green"), #图例颜色
lty=c(1, 2, 6),
lwd=2
) #图例大小
2.3.2 分布函数 pt(q, df, ncp = 0, lower.tail = T)
pt(1, 5)
> pt(1, 5)
[1] 0.8183913
lower.tail 参数,默认为 TRUE,即作下尾运算 \(F(x)=P(X\leq x)\);若改为 FALSE,则表示 \(F(x)=P(X>x)\).
pt(1, 5, lower.tail = FALSE)
> pt(1, 5, lower.tail = FALSE)
[1] 0.1816087
分布函数图像
Fx <- pt(x, 5)
plot(x, Fx, type = 'l')
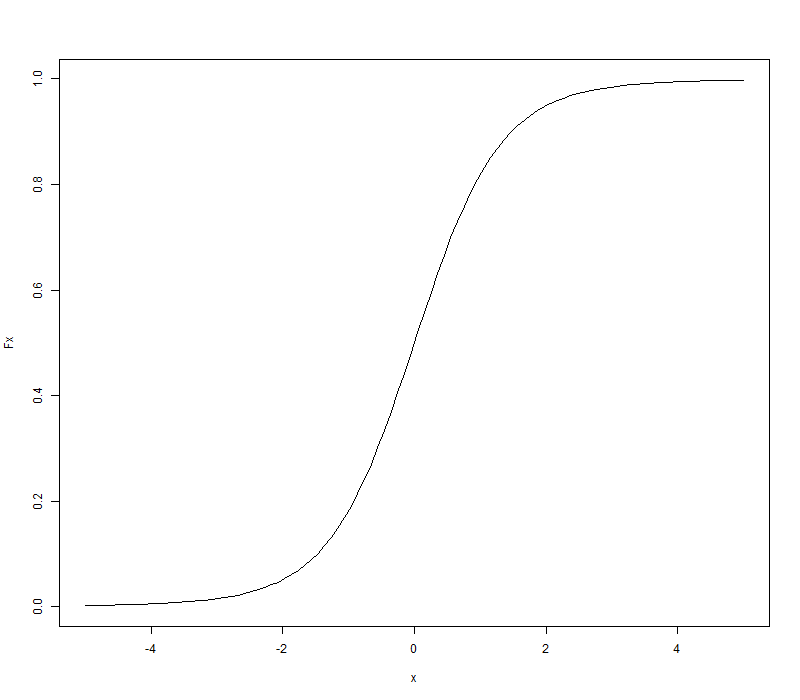
2.3.3 分位函数 qt(p, df, ncp = 0, lower.tail = T)
qt(0.3, 5)
> qt(0.3, 5)
[1] -0.5594296
q <- qt(0.3, 5)
pt(q, 5)
> pt(q, 5)
[1] 0.3
1 - pt(q, 5, lower.tail = F)
> 1 - pt(q, 5, lower.tail = F)
[1] 0.3
## 也可以计算上分位点
qt(0.3, 5, lower.tail = F)
> qt(0.3, 5, lower.tail = F)
[1] 0.5594296
2.4 F 分布
2.4.1 概率密度函数 df(x, df1, df2, ncp = 0)
df(1, df1 = 5, df2 = 1)
> df(1, df1 = 5, df2 = 1)
[1] 0.2196798
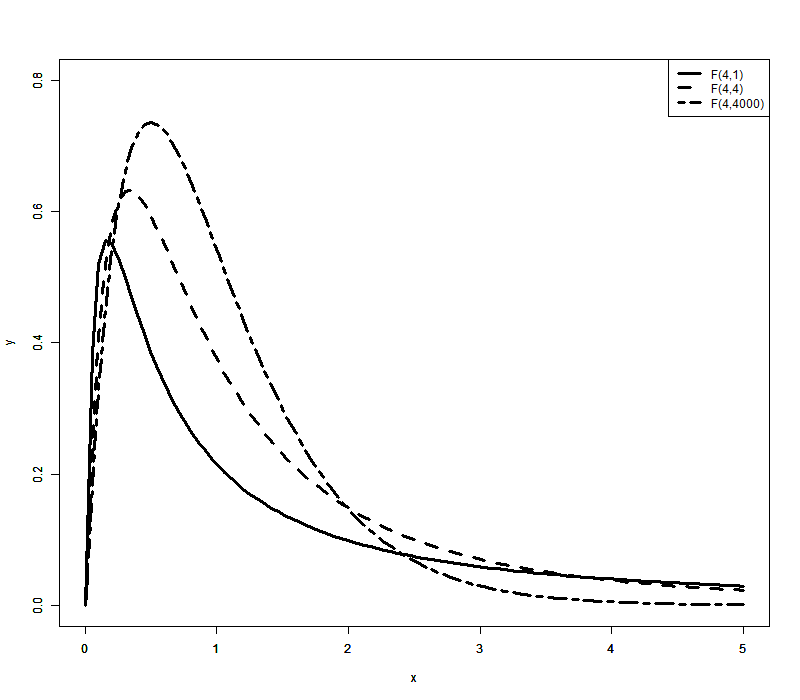
绘制密度函数图像
x <- seq(0, 5, length = 100)
y1 <- df(x, df1 = 4, df2 = 1)
y2 <- df(x, df1 = 4, df2 = 4)
y3 <- df(x, df1 = 4, df2 = 4000)
plot(x, y1, type = 'l', lty = 1, lwd = 3, xlab = 'x', ylab = 'y', ylim = c(0,0.8))
par(new = TRUE)
plot(x, y2, type = 'l', lty = 2, lwd = 3, xlab = 'x', ylab = 'y', ylim = c(0,0.8))
par(new = TRUE)
plot(x, y3, type = 'l', lty = 6, lwd = 3, xlab = 'x', ylab = 'y', ylim = c(0,0.8))
legend("topright", #图例位置为右上角
legend=c("F(4,1)","F(4,4)","F(4,4000)"), #图例内容
# col=c("red","blue","green"), #图例颜色
lty=c(1, 2, 6),
lwd=3
) #图例大小
2.4.2 分布函数 pf(q, df1, df2, ncp = 0, lower.tail = T)
pf(1, 5, 5)
> pf(1, 5, 5)
[1] 0.5
lower.tail 参数,默认为 TRUE,即作下尾运算 \(F(x)=P(X\leq x)\);若改为 FALSE,则表示 \(F(x)=P(X>x)\).
pf(1, 5, 5, lower.tail = FALSE)
> pf(1, 5, 5, lower.tail = FALSE)
[1] 0.5
分布函数图像
Fx <- pf(x, 4, 4)
plot(x, Fx, type = 'l')
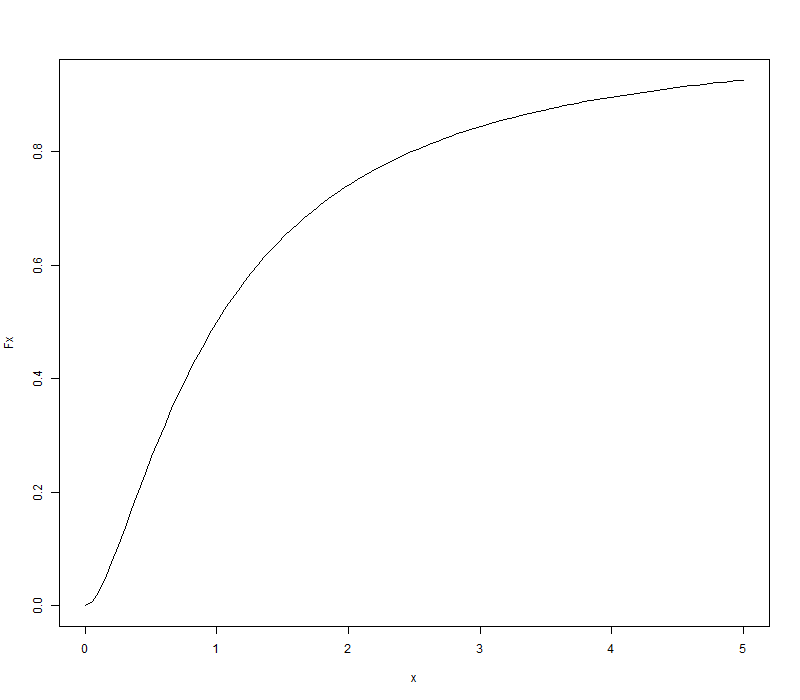
2.4.3 分位函数 qf(p, df1, df2, ncp = 0, lower.tail = T)
qf(0.3, 5, 5)
> qf(0.3, 5, 5)
[1] 0.6093936
q <- qf(0.3, 5, 5)
pf(q, 5, 5)
> pf(q, 5, 5)
[1] 0.3
1 - pf(q, 5, 5, lower.tail = F)
> 1 - pf(q, 5, 5, lower.tail = F)
[1] 0.3
## 也可以计算上分位点
qf(0.3, 5, 5, lower.tail = F)
> qf(0.3, 5, 5, lower.tail = F)
[1] 1.640976
3 数据的图形描述
3.1 直方图
# 考试成绩数据
x <- c(25, 45, 50, 54, 55,
61, 64, 68, 72, 75,
78, 79, 81, 83, 84,
84, 84, 85, 86, 86,
86, 87, 89, 89, 90,
91, 91, 92, 100)
# 频数直方图
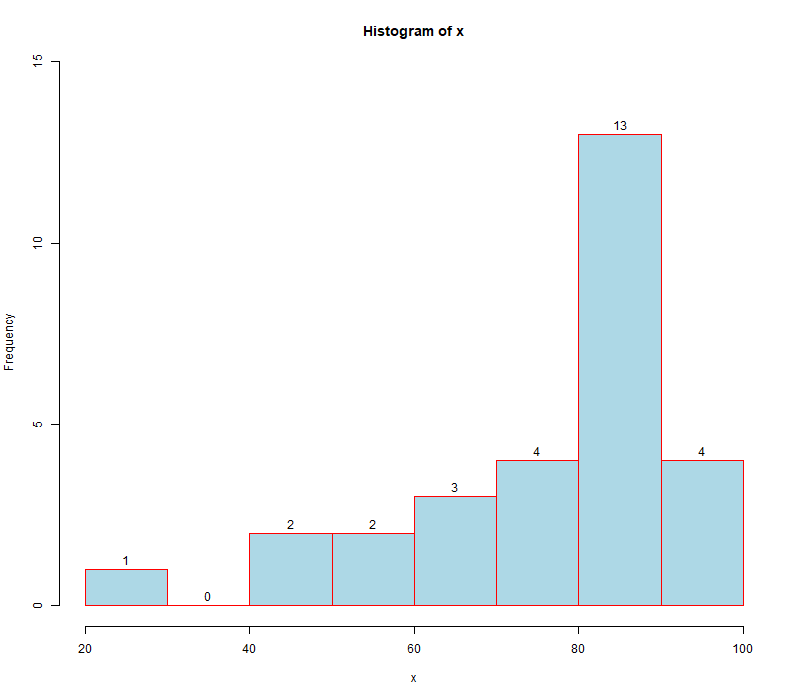
hist(x, col = 'lightblue', border = 'red', labels = T, ylim = c(0, 14.5))
# 概率密度直方图
r <- hist(x, freq = FALSE, density = 10, angle = 15+ 30* 1:6)
text(r$mids, 0, r$counts, adj = c(.5, - .5), cex = 1.2)
lines(density(x), col = 'blue', lwd = 2)
y <- seq(from = 20, to = 100, by = 1)
lines(y, dnorm(y, mean(x), sd(x)), col = 'red', lwd = 2)
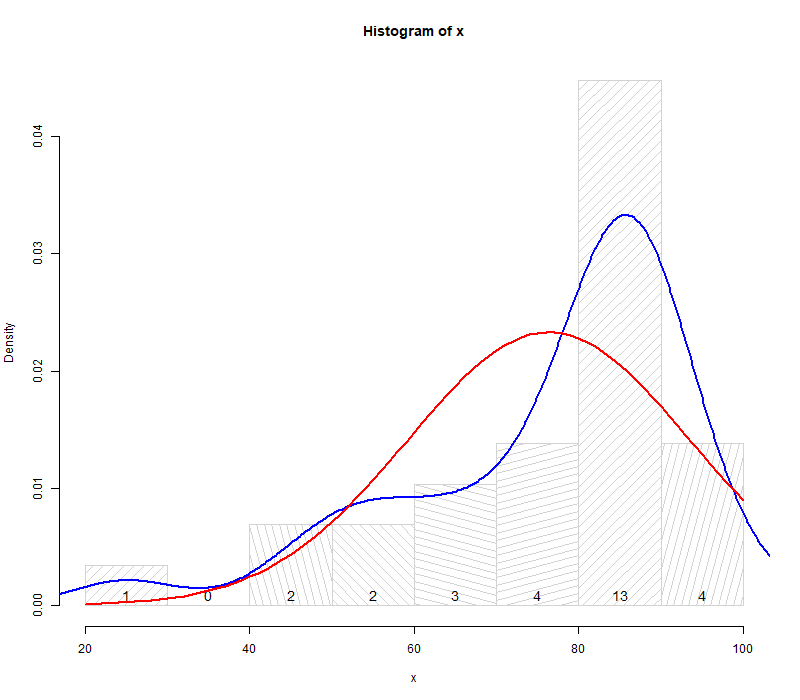
图中红线为正态分布曲线,蓝线为数据的密度曲线,从图像可以看出考试成绩数据不服从正态分布.
3.2 QQ图
qqnorm(x)
qqline(x)
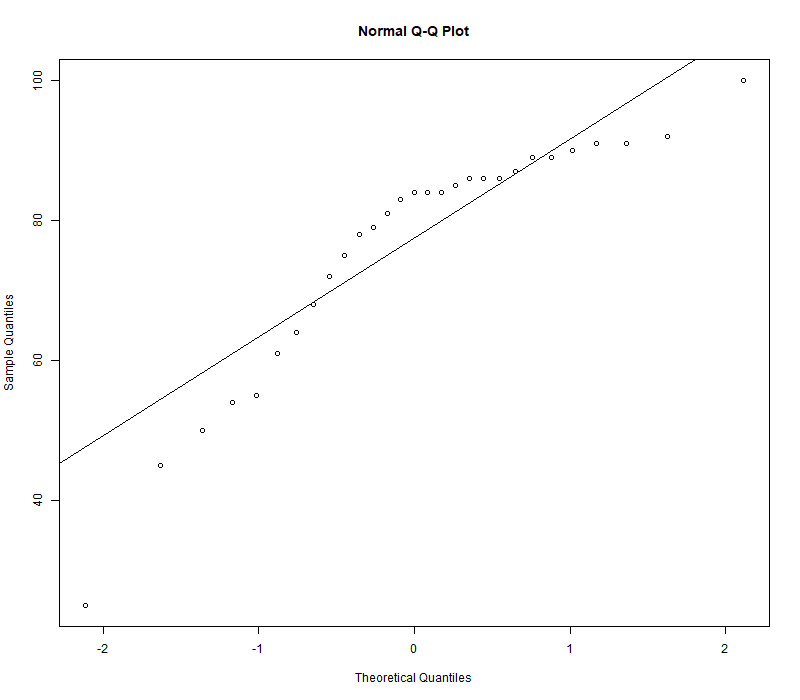
从QQ图可以看出,散点与直线的偏差过多,因此认为考试成绩数据不服从正态分布.

