

一元线性回归的Python实现
1 问题的提出
对于给定的数据集 ,线性回归 (linear regression) 试图学得一个线性模型以尽可能准确地预测是指输出标记.
2 原理
设给定的数据集 . 对于离散属性,如果属性值间存在“序”(order)的关系,可通过连续化将其转化为连续值,例如二值属性“身高”的取值“高”“矮”可转化为 ,三值属性“高度”的取值“高”“中”“低”可转化为 ;若属性之间不存在有序关系,假定有 个属性值,则通常转化为 维向量,例如属性“瓜类”的取值“西瓜”“南瓜”“黄瓜”可转化为 .
线性回归试图学得
2.1 代价函数
我们需要确定 和 的值使得 和 之间的差别尽可能小. 因此我们引入均方误差,均方误差是回归问题中最常用的性能度量工具,我们可以试图让均方误差最小化,即
意思就是找出一个 使得 的值最小,即他的返回值是 的最小值所对应的 的值.
均方误差有很好的几何意义,它对应了常用的“欧式距离”(Euclidean distance),基于均方误差最小化的进行模型求解的方法称为“最小二乘法”(least square method). 在线性回归中,最小二乘法就是试图寻找一条直线,使得所有样本点到直线的欧氏距离之和最小.
在均方误差的基础上进一步构造代价函数
这里分母的 是为了后续求导的方便
求解 和 使 最小化的过程,称为线性回归模型的最小二乘“参数估计”(parameter estimation). 我们可将 分别对 和 求导,得到
令上两式等于0,解得
是关于 的凸函数,根据凸函数的性质,其偏导为 时就是 和 的最优解.
其中 为 的均值.
2.2 模型的评价
2.2.1 皮尔逊相关系数
使用相关系数衡量线性相关性的强弱,皮尔逊相关系数的公式如下:
相关度越高,皮尔逊相关系数的值就趋于 1 或 -1 (趋于 1 表示它们呈正相关, 趋于 -1 表示它们呈负相关);如果相关系数等于0,表明它们之间不存在线性相关关系.
2.2.2 决定系数
决定系数 也称拟合优度,反应了 的波动有多少百分比能被 的波动所描述. 决定系数越接近 1 ,说明拟合程度越好.
总平方和
回归平方和
残差平方和
其中
3 Python 实现
3.1 不调sklearn库
Step1. 调库
import numpy as np from numpy import genfromtxt import matplotlib.pyplot as plt
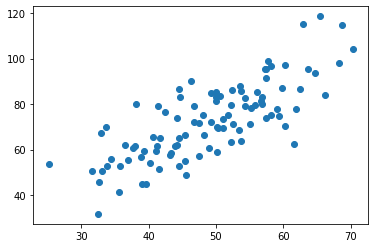
Step2. 数据导入并绘制散点图
data = genfromtxt("data.csv", delimiter = ",") x = data[:, 0, np.newaxis] y = data[:, 1, np.newaxis] plt.scatter(x, y) plt.show()
Step3. 求回归系数
根据先前的推导,已经知道
m = len(x) x_bar = np.mean(x) w = (np.sum((x - x_bar)*y))/(np.sum(x**2)-(1/m)*(np.sum(x))**2) b = np.mean(y-w*x) print(w,b)
1.3224310227553517 7.991020982270779
Step4. 拟合图像
plt.plot(x, y, 'b.') plt.plot(x, w*x+b, 'r') plt.show()

Step5. 计算相关系数和决定系数
COVxy = np.cov(x.T,y.T) r = COVxy[0,1]/(x.std()*y.std()) print(r)
0.78154393928063
y_hat = w*x+b SSR = np.sum((y_hat-np.mean(y))**2) SST = np.sum((y-np.mean(y))**2) R2 = SSR/SST print(R2)
0.5986557915386548
3.2 调 sklearn 库
建模:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(x, y)
LinearRegression()
拟合图像的得出
plt.plot(x, y, 'b.') plt.plot(x, model.predict(x), 'r') plt.show()

回归系数
w = model.intercept_ b = model.coef_ print("截距为 {0}, 回归系数为 {1}".format(w[0], b[0][0]))
截距为 7.991020982270385, 回归系数为 1.32243102275536
决定系数
model.score(x, y)
0.598655791538662
4 梯度下降法
4.1 原理
由于代价函数是凸函数,因此只有全局最小值,梯度下降法的原理是先定一个初始值,然后利用导数就像阶梯一样慢慢逼近全局最小值

已知代价函数 ,我们需要找一组 使得 最小,给定一个算法:
其中 为学习率,学习率不能太大也不能太小,可以多次尝试 .
根据已知条件,有
于是
4.2 Python实现
# 学习率learning rate lr = 0.0001 # 截距初值 b = 0 # 斜率初值 w = 0 # 最大迭代次数 epochs = 50 # 最小二乘法 def compute_error(b, w, x, y): totalError = 0 for i in range(0, len(x)): totalError += (y[i] - (w * x[i] + b)) ** 2 return totalError / float(len(x)) / 2.0 def gradient_descent_runner(x, y, b, w, lr, epochs): # 计算总数据量 m = float(len(x)) # 循环epochs次 for i in range(epochs): b_grad = 0 w_grad = 0 # 计算梯度的总和再求平均 for j in range(0, len(x)): b_grad += -(1/m) * (y[j] - ((w * x[j]) + b)) w_grad += -(1/m) * x[j] * (y[j] - ((w * x[j]) + b)) # 更新 b 和 w b = b - (lr * b_grad) w = w - (lr * w_grad) # 每迭代5次,输出一次图像 if i % 5 == 0: print('epochs:', i) plt.plot(x, y, 'b.') plt.plot(x, w*x + b, 'r') plt.show() return b,w
print('Starting b = {0}, w = {1}, error = {2}'.format(b, w, compute_error(b, w, x, y))) print('Running') b, w = gradient_descent_runner(x, y, b, w, lr, epochs) print('After {0} iterations b = {1}, w = {2}, error = {3}'.format(epochs, b, w, compute_error(b,w,x,y))) # 画图 plt.plot(x, y, 'b.') plt.plot(x, w * x + b, 'r') plt.show()
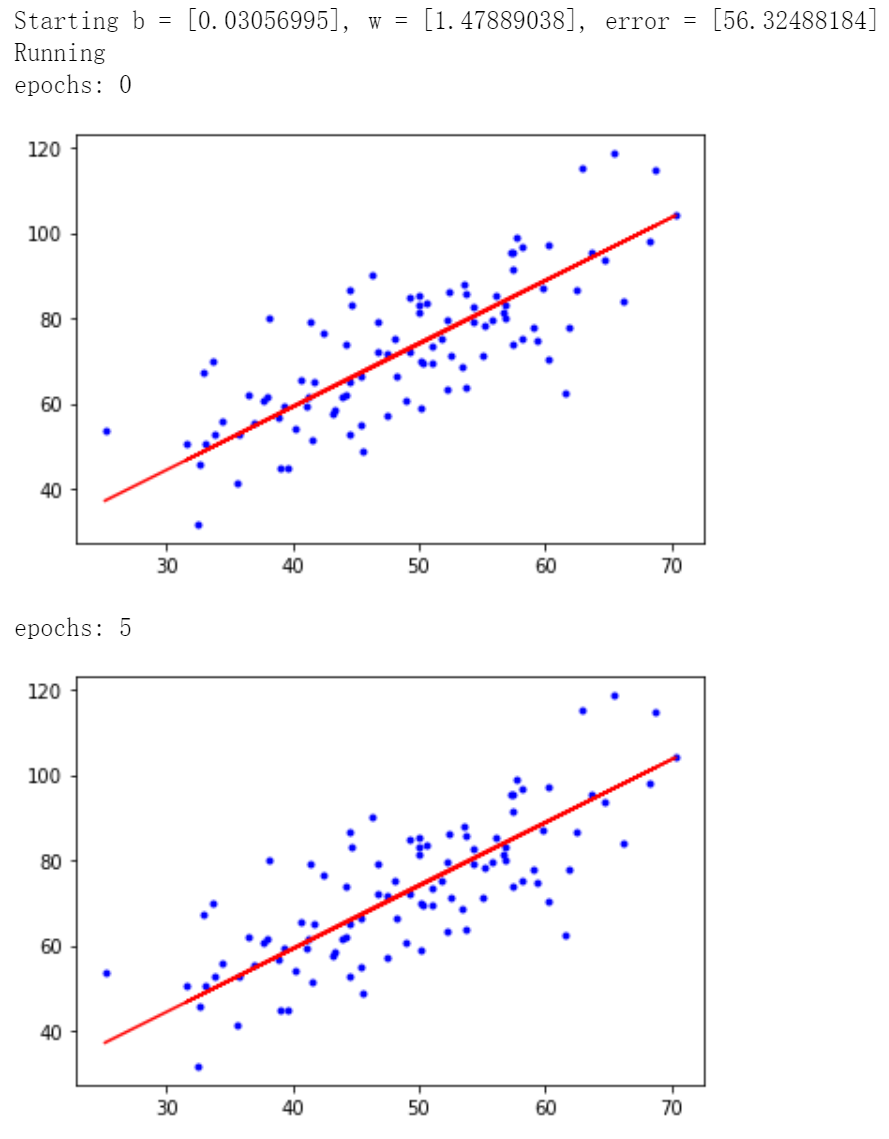

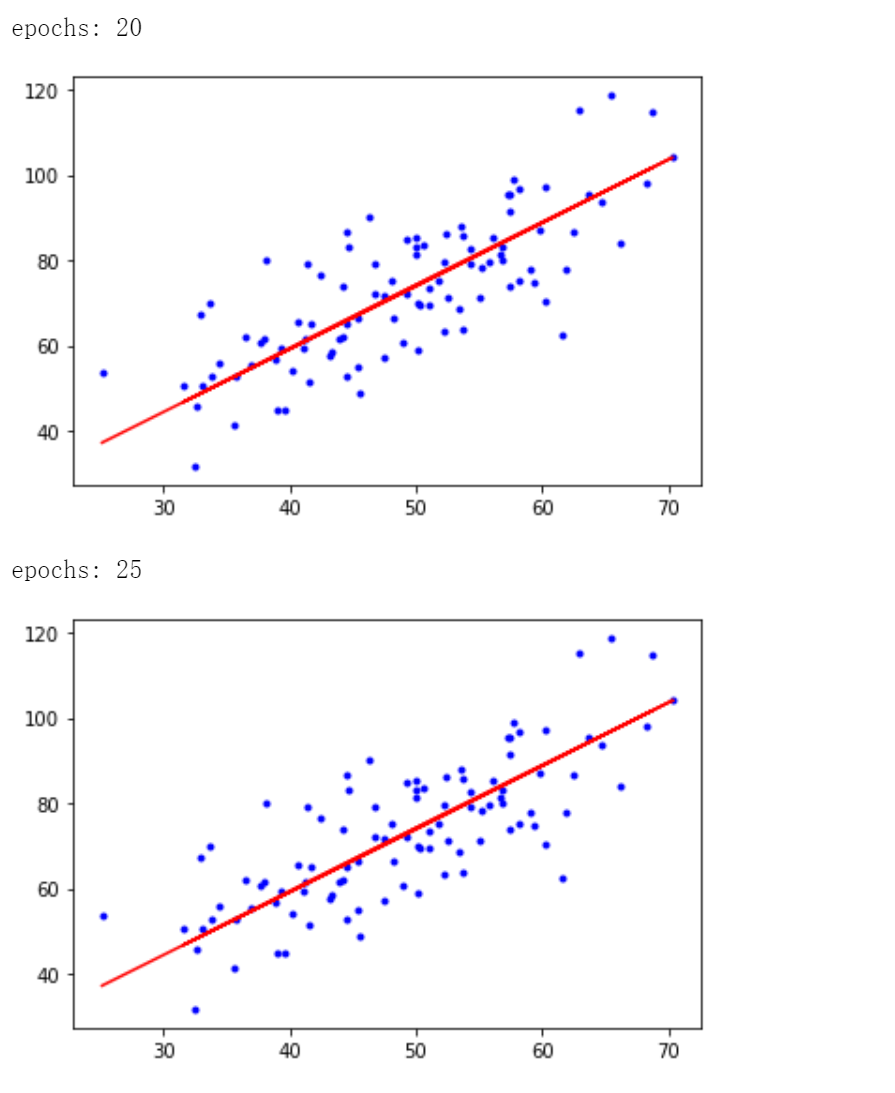
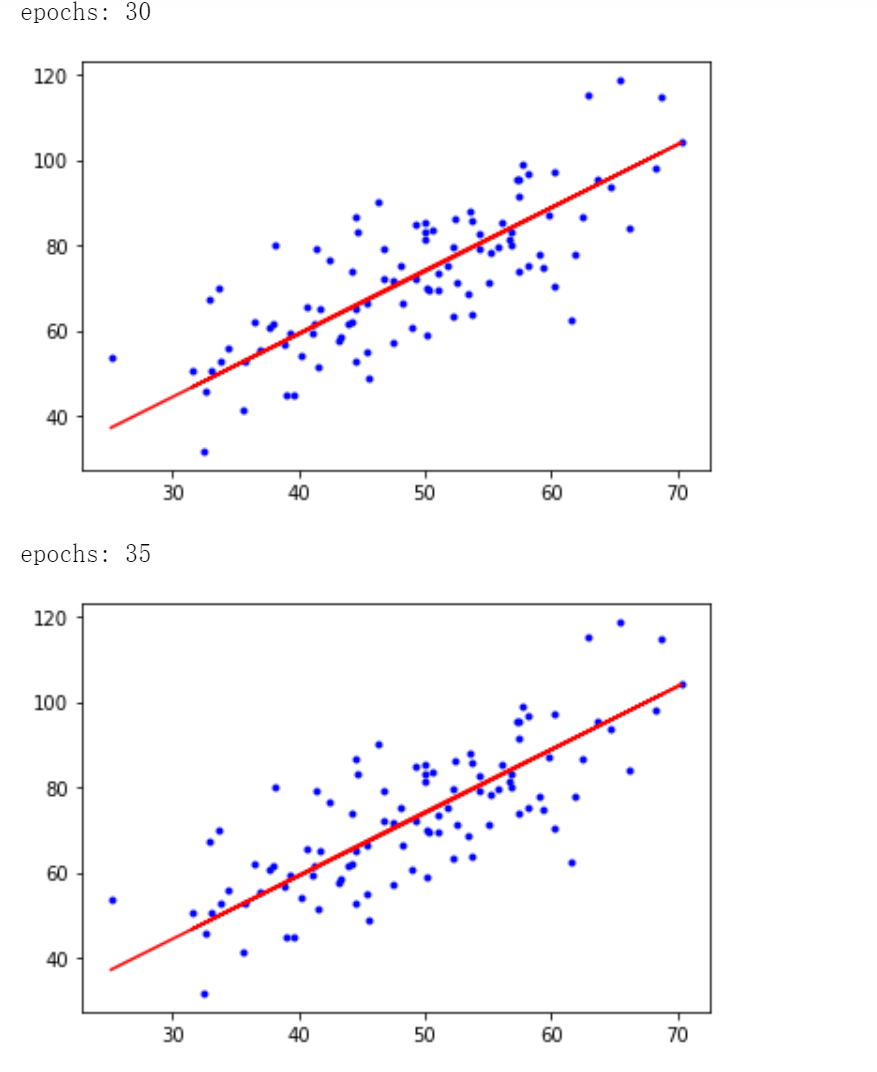
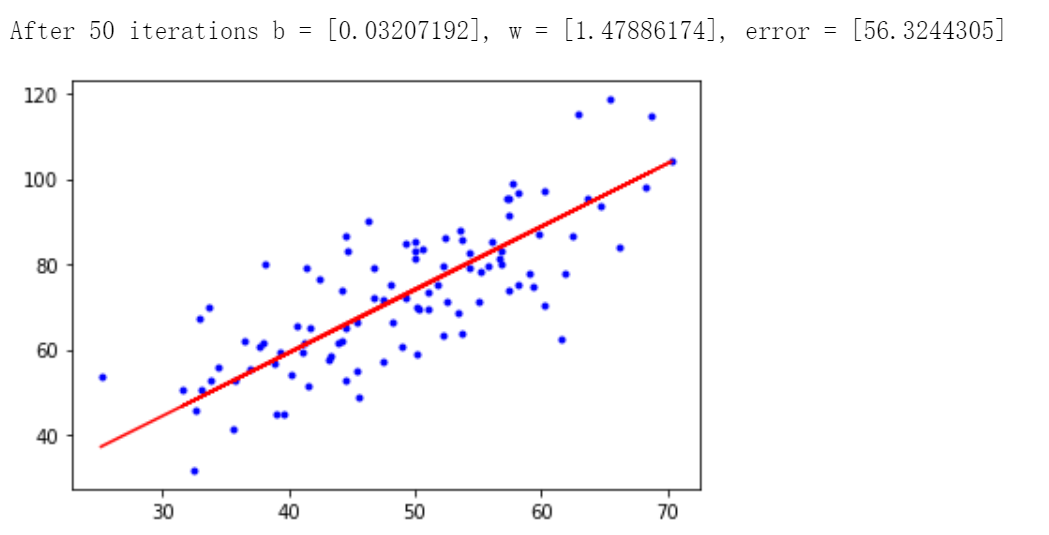
迭代50次后得到 ,最小二乘误差为 56.3244305.
参考
[1]. 周志华.《机器学习》.清华大学出版社
[2]. https://www.bilibili.com/video/BV1Rt411q7WJ?p=4&vd_source=08d2535b05740d396ec0fc720c52f36a


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下