人口增长模型
1. 指数增长模型
设第今年的人口为 \(x_0\),年增长率为 \(r\),预测 \(k\) 年后的人口为 \(x_k\),则有
这个模型的前提是年增长率 \(r\) 在 \(k\) 年内保持不变.
利用 (1) 式可以根据人口估计年增长率,例如经过 \(n\) 年后人口翻了一番,那么这期间的年平均增长率约为 \((70/n)\%\).
证明:
1.1 人口增长模型的建立
将人口看作连续时间 \(t\) 的连续可微函数 \(x(t)\). 于是有
求解上述微分方程:
由于 \(x(0) = x_0\),代入上式可得 \(x_0 = C\),可以解出
可以用 R 语言定义指数增长模型方程
## 指数增长模型方程
fun1 <- function(t) x0 * exp(r*t)
1.2 参数估计
以书本 P142 美国人口数据为例
1.1.1 线性最小二乘估计
对 (3) 取对数,有 \(\ln x = \ln x_0 + rt\),于是 \(\ln x\) 与 \(t\) 存在线性关系,令10年为一个单位.
下面用 R 进行参数估计.
> ## 美国人口数据的导入
> x <- c(3.9, 5.3, 7.2, 9.6, 12.9, 17.1, 23.2, 31.4,
+ 38.6, 50.2, 62.9, 76.0, 92.0, 105.7, 122.8,
+ 131.7, 150.7, 179.3, 203.2, 226.5, 248.7, 281.4)
> ## 线性最小二乘估计
> y <- log(x)
> t <- sequence(length(x), 0, 1)
> lm(y~t) -> sol
> summary(sol)
Call:
lm(formula = y ~ t)
Residuals:
Min 1Q Median 3Q Max
-0.43901 -0.19764 0.00609 0.23405 0.32145
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.79999 0.10538 17.08 2.14e-13 ***
t 0.20201 0.00859 23.52 4.80e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.2556 on 20 degrees of freedom
Multiple R-squared: 0.9651, Adjusted R-squared: 0.9634
F-statistic: 553.1 on 1 and 20 DF, p-value: 4.8e-16
> exp(1.79999)
[1] 6.049587
结果分析:
于是\(r = 0.2020/10年, \ x_0 = e^{1.79999}=6.0496\)
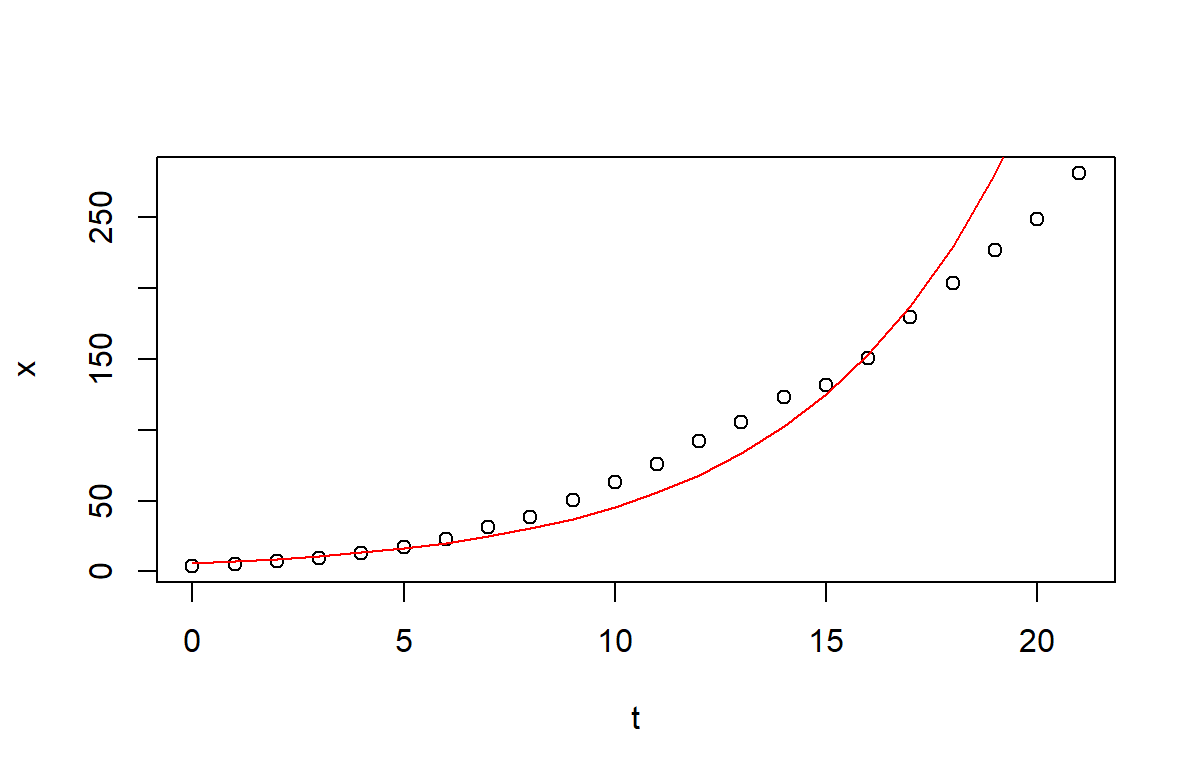
通过图像看看拟合效果:
# 拟合图像
x0 <- exp(1.79999)
r <- 0.20201
y_hat1 <- fun1(t)
plot(t, x)
lines(t, y_hat1, col="red")
1.1.2 基于数值微分的参数估计
对人口数据作数值微分,进而计算增长率,将增长率的平均值作为 \(r\) 的估计;\(x_0\) 直接采用原始数据.
理论依据:
数值微分可用中点公式算近似值:
下面用 R 语言计得出 \(r\) 的估计值
> ## 数值微分估计
> dx <- c()
> dx[1] <- (-3*x[1]+4*x[2]-x[3])/2 # 数值微分中点公式的应用
> for (i in 2:(length(x)-1)){
+ dx[i] <- (x[i+1]-x[i-1])/2 # 数值微分中点公式的应用
+ }
> dx[length(x)] <- (x[length(x)-2]-4*x[length(x)-1]+3*x[length(x)])/2 # 数值微分中点公式的应用
> R <- dx/x # 增长率序列
> r <- mean(R) # 其平均值就是r的估计
> r
[1] 0.02051861
通过图像看看拟合效果
# 拟合图像
x0 <- x[1]
y_hat2 <- fun1(t)
plot(t, x)
lines(t, y_hat2, col="red")

1.3 改进的指数增长模型
在前面的模型中,我们假定了每年人口的增长率是固定的,显然这是存在缺陷的,每年的增长率应是时间的函数,即增长率为 \(r(t)\).
我们首先画出 \(r(t)\) 与 \(t\) 的散点图(这里我们的增长率用的是1.2.2中做数值微分得到的增长率序列),看看他们存在什么函数关系
## 画出 r~t 散点图
plot(t,R)
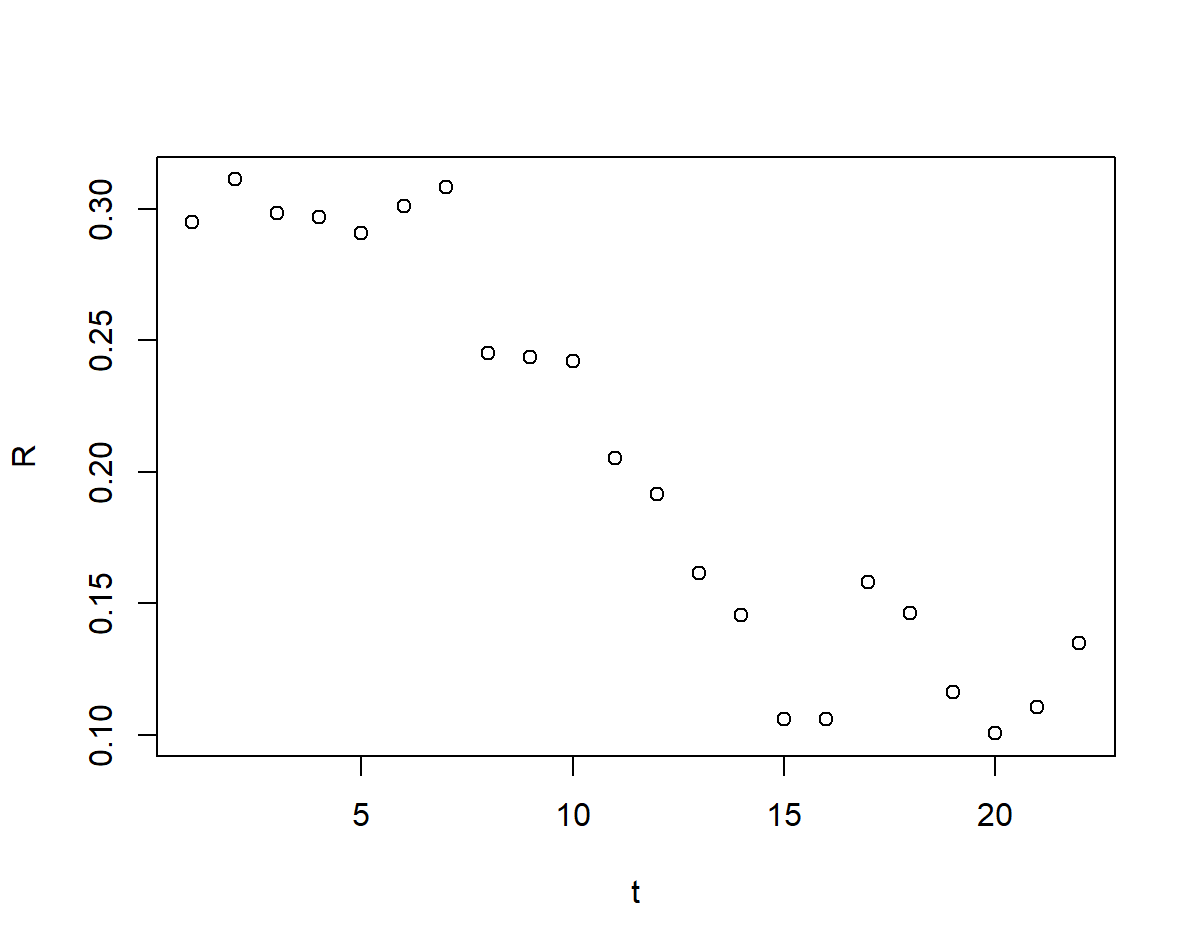
可以看出两者疑似存在线性关系,不妨做线性拟合
> ## 线性拟合
> lm(R~t) -> sol2
> summary(sol2)
Call:
lm(formula = R ~ t)
Residuals:
Min 1Q Median 3Q Max
-0.059303 -0.007904 -0.001237 0.015108 0.051549
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.3252461 0.0117048 27.79 < 2e-16 ***
t -0.0114343 0.0009541 -11.98 1.39e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.02839 on 20 degrees of freedom
Multiple R-squared: 0.8778, Adjusted R-squared: 0.8717
F-statistic: 143.6 on 1 and 20 DF, p-value: 1.391e-10
结果分析:
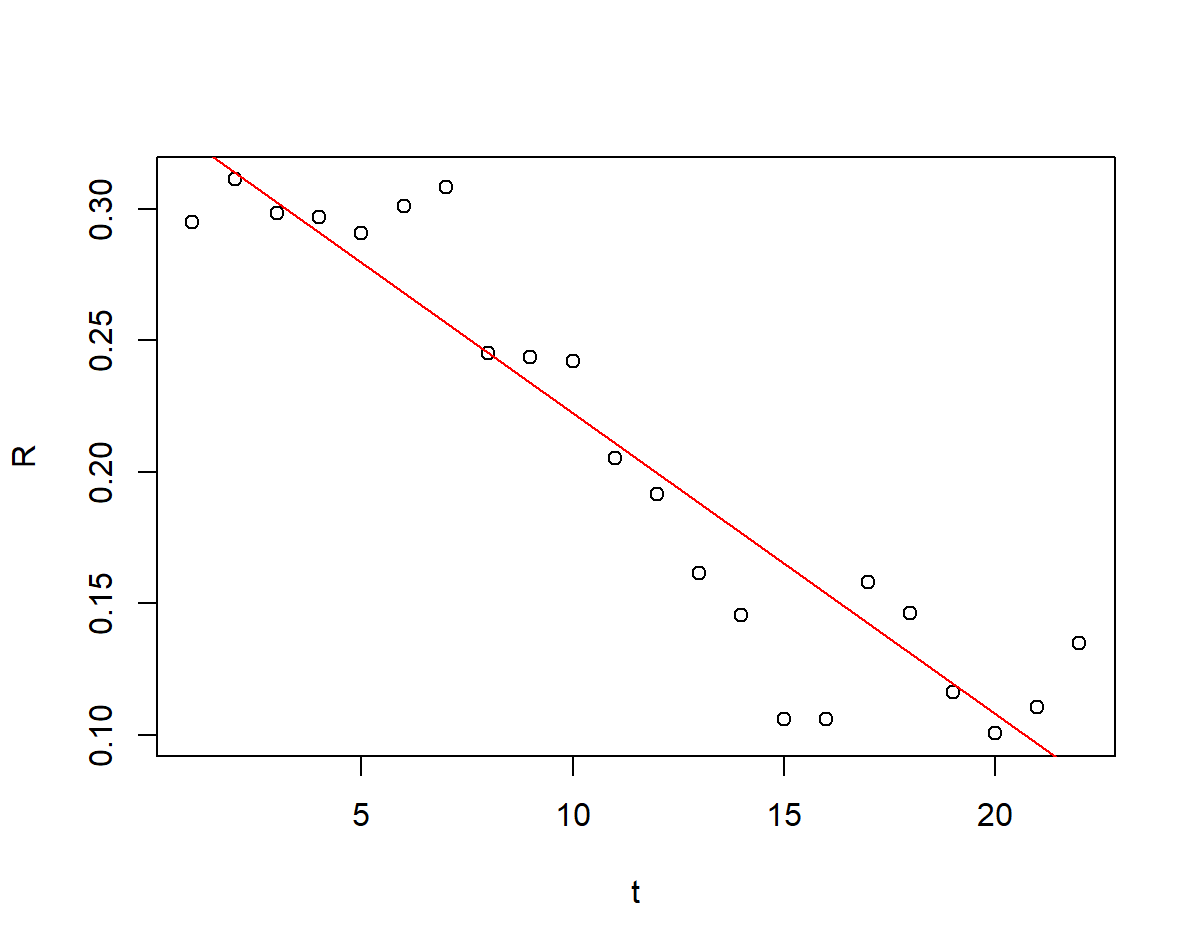
且回归方程的检验统计量\(F=143.6, \ p = 1.391e-10 << 0.01, \ R^2 = 0.8778\),认为回归方程的拟合程度不错,两者存在非常显著的线性关系;常数项检验 \(t = 27.79, \ p << 0.01\),一次项系数检验 \(t = -11.98, \ p = 1.39e-10 << 0.01\),认为回归方程系数显著不为0.
看看拟合图像
# 拟合图像
plot(t,R)
abline(sol2, col = "red")
记 \(r = r_0 - r_1t\),于是 \((2)\) 式变为
用分离变量的方法求解上述微分方程,\((4)\) 可化为
将 \(x(0) = x_0\) 代入,即可得 \(C' = x_0\),于是解得
可以用 \(R\) 语言定义上述函数
## 定义函数
fun2 <- function(t) x0 * exp(r0*t - r1*t^2/2)
下面用 \(R\) 语言做指数增长模型的拟合
## 利用模型估计人口并做拟合图像
r0 <- 0.3252461
r1 <- 0.0114343
x0 <- x[1]
t <- sequence(length(x), 0, 1)
y_hat3 <- fun2(t)
plot(t, x)
lines(t, y_hat3, col = "red")
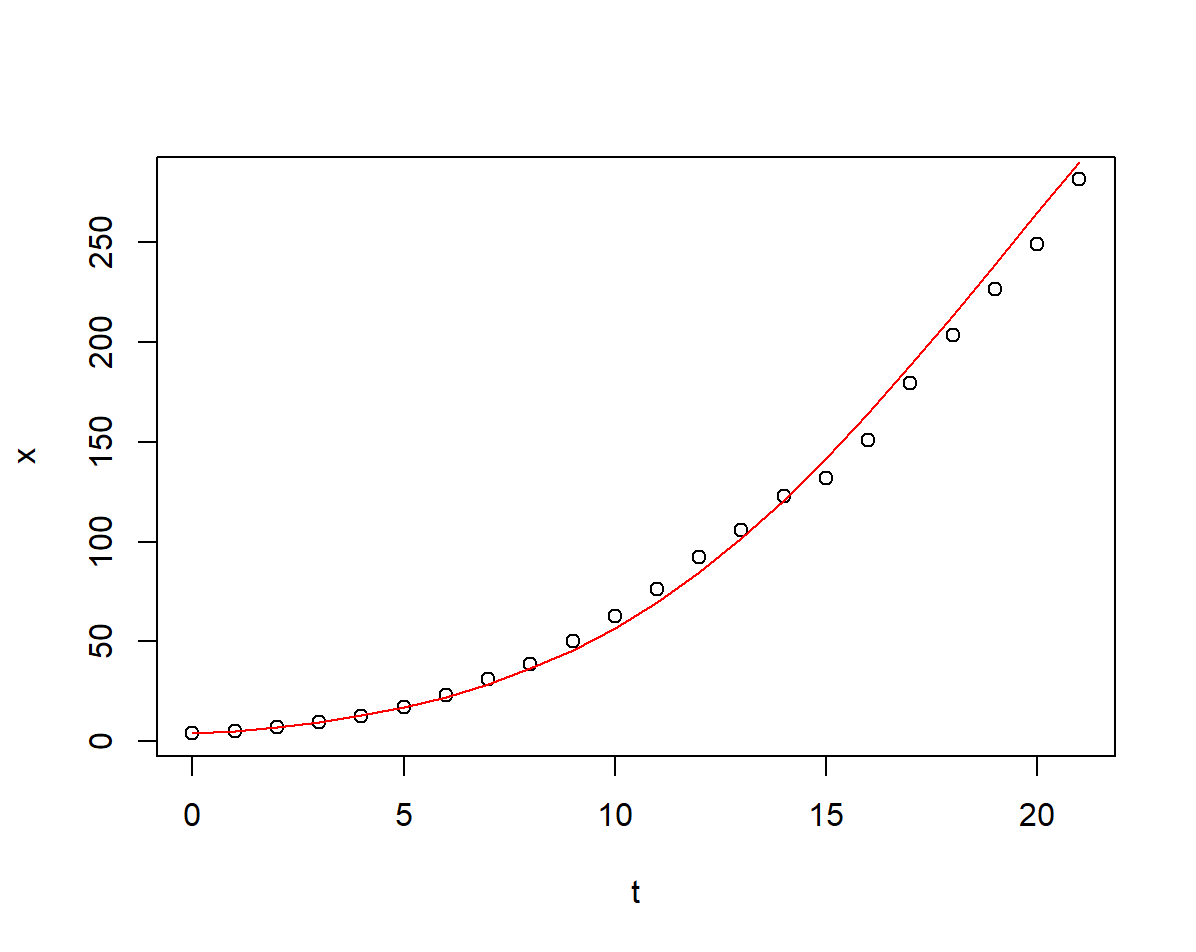
可以看出改进的指数增长模型的拟合程度明显好于改进前的指数增长模型.
2. logistic 模型
考虑自然资源、环境条件等因素对人口增长起阻碍作用,并且随着人口的增加,阻碍作用越来越大.
2.1 logistic 模型的建立
随着人口的增长,资源和环境的阻碍作用体现在对增长率 \(r\) 的影响上,于是 \(r(x)\) 是 \(x\) 的函数,主观上我们认为 \(r(x)\) 是减函数,我们可以画出两者之间的散点图来大致判断两者之间满足何种函数关系(这里我们的增长率用的是1.2.2中做数值微分得到的增长率序列)
## r~x 散点图
plot(x, R)
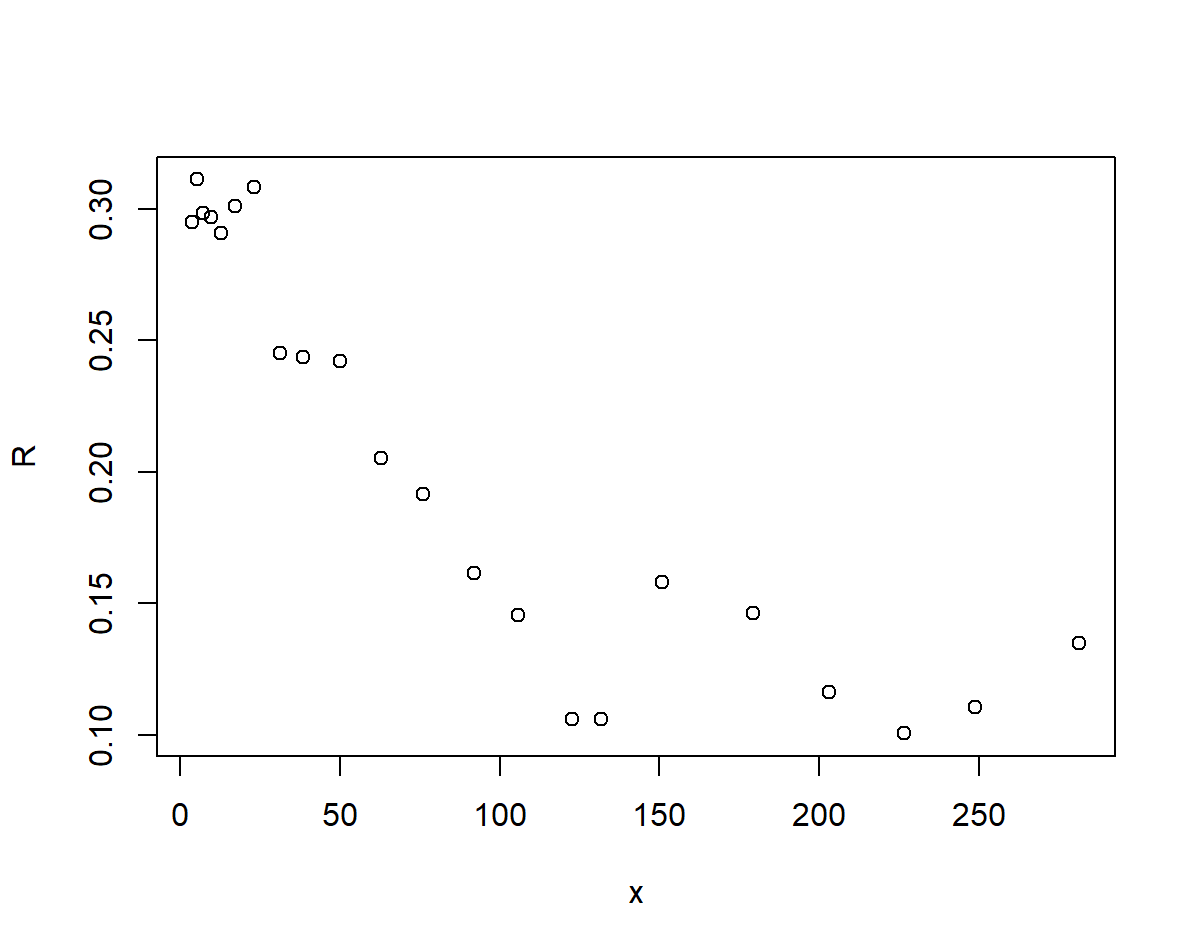
散点图显示两者之间存在线性关系,不妨设 \(r(x) = a + bx\),为了赋予系数 \(a,b\) 实际含义,引入两个参数:
- 内禀增长率 \(r_0\) \(\quad r_0\) 是 \(x=0\) 的增长率,于是 \(a = r_0\);
- 人口容量 \(x_m\) \(\quad x_m\) 是资源和环境所能容纳的最大人口数量,也就是当 \(x=x_m\) 后人口不再增长,即 \(r(x_m) = r + bx_m = 0\),解得 \(b = -\frac{r}{x_m}\).
于是
那么 \((2)\) 变为
上式称为 logistic 方程.
将上式化为
将点 \((t,x) = (0,x_0)\) 代入上式可得
综上就可求得
上式称为 logistic 曲线. \((5),(6)\) 统称为 logistic 模型.
利用 R 语言定义上述函数
## 定义函数
fun3 <- function(t) xm/(1+(xm/x0-1)*exp(-r0*t))
2.2 参数估计
2.2.1 线性最小二乘估计
\((5)\) 式可改写为
下面用 R 语言做线性估计
> ## 线性最小二乘估计
> lm(R~x) -> sol3
> summary(sol3)
Call:
lm(formula = R ~ x)
Residuals:
Min 1Q Median 3Q Max
-0.076819 -0.021568 0.000946 0.023945 0.078560
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.805e-01 1.243e-02 22.573 1.06e-15 ***
x -7.968e-04 9.763e-05 -8.162 8.55e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.03902 on 20 degrees of freedom
Multiple R-squared: 0.7691, Adjusted R-squared: 0.7575
F-statistic: 66.61 on 1 and 20 DF, p-value: 8.546e-08
结果分析:
且回归方程的检验统计量\(F=66.61, \ p = 8.546e-08 << 0.01, \ R^2 = 0.7691\),认为回归方程的拟合程度不错,两者存在非常显著的线性关系;常数项检验 \(t = 22.573, \ p << 0.01\),一次项系数检验 \(t = -8.162, \ p << 0.01\),认为回归方程系数显著不为0.
于是 \(r_0 = 0.2805, \ x_m = 0.1805/7.968e-04 = 352.0331\),画出拟合图像
# 拟合
r0 = 0.2805
xm = 0.2805/7.968e-04
y_hat4 <- fun3(t)
plot(t, x)
lines(t, y_hat4, col = "red")

2.2.2 非线性最小二乘法
考虑 Levenberg-Marquadt 方法求解,\((6)\) 式可化为
带估计参数为 \((x_m,x_0,r_0)\),给定初始值 \((400,4,0.25)\),用 R 求解
> ## 非线性最小二乘估计
> library(pracma)
> fun4 <- function(z) {
+ f <- numeric(22)
+ for (i in 1:22){
+ f[i] <- x[i] - z[1]/(1+(z[1]/z[2]-1)*exp(-z[3]*(i-1)))
+ }
+ f
+ }
> sol4 <- lsqnonlin(fun4, x0 = c(400,4,0.25))
> sol4
$x
[1] 443.9948201 7.6962896 0.2154783
$ssq
[1] 458.2113
$ng
[1] 0.0002470027
$nh
[1] 3.847784e-06
$mu
[1] 7.431693e-06
$neval
[1] 22
$errno
[1] 1
$errmess
[1] "Stopped by small x-step."
于是可得参数的估计值为 \(x_m = 443.9948201, \ x_0 = 7.6962896, \ r_0 = 0.2154783\).
下面将估计的参数代入 \((6)\),得出拟合图像
# 拟合
xm = 443.9948201
x0 = 7.6962896
r0 = 0.2154783
y_hat5 <- fun3(t)
plot(t, x)
lines(t, y_hat5, col = "red")

2.3 比较
为了比较线性最小二乘估计和非线性最小二乘估计的拟合程度,引入均方误差,均方误差越小说明拟合程度越高
下面用 R 计算两种方法的均方误差
> ## 比较
> MSE1 <- sum((y_hat4-x)^2)/length(x)
> MSE2 <- sum((y_hat5-x)^2)/length(x)
> print(MSE1)
[1] 127.1399
> print(MSE2)
[1] 20.82779
发现 \(MS1 = 127.1399 > 20.82779 = MSE2\),因此非线性最小二乘参数估计的拟合效果更好.
不妨再计算一下改进的指数增长模型的均方误差
> MSE3 <- sum((y_hat3-x)^2)/length(x)
> MSE3
[1] 51.51463
可以发现,logistic模型的非线性最小二乘估计参数的结果要好于改进的指数增长模型.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号