
存储过程
2010-09-03 09:39 苏飞 阅读(3035) 评论(11) 编辑 收藏 举报文章导航 SQL Server 2005 学习笔记系列文章导航
在写这一系列的文章的时候发现有些朋友,还有就是我的同事们,对数据的基本类型和基本操作上不是很熟悉,像存储过程 ,事务这些东西不怎么理解,
我就本着帮助新手的理念在这里把这一系列的东东都 一个一个的介绍一下吧,里面再加上一个例子,相信可以对他们有些帮助。新手学习,高手指点吧,呵呵
介绍
我们先来了解一下什么是存储过程吧,存储过程是由流控制和SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,应用程序使用时只要调用即可。在ORACLE中,若干个有联系的过程可以组合在一起构成程序包。 存储过程是利用SQL Server所提供的Transact-SQL语言所编写的程序。Transact-SQL语言是SQL Server提供专为设计数据库应用程序的语言,它是应用程序和SQL Server数据库间的主要程序式设计界面。它好比Oracle数据库系统中的PL-SQL和Informix的数据库系统结构中的Informix- 4GL语言。这类语言主要提供以下功能,让用户可以设计出符合引用需求的程序: 1)、变量说明 2)、ANSI兼容的SQL命令(如Select,Update….) 3)、一般流程控制命令(if…else…、while….) 4)、内部函数 存储过程(Stored Procedure)是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程可由应用程序通过一个调用来执行,而且允许用户声明变量 。同时,存储过程可以接收和输出参数、返回执行存储过程的状态值,也可以嵌套调用。
它的优点
* 存储过程的能力大大增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的 运算。
* 可保证数据的安全性和完整性。
# 通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。
# 通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
* 在运行存储过程前,数据库已对其进行了语法和句法分析,并给出了优化执行方案。这种已经编译好的过程可极大地改善SQL语句的性能。由于执行SQL语句的大部分工作已经完成,所以存储过程能以极快的速度执行。
* 可以降低网络的通信量。
* 使体现企业规则的运算程序放入数据库服务器中,以便 集中控制。
# 当企业规则发生变化时在服务器中改变存储过程即可,无须修改任何应用程序。企业规则的特点是要经常变化,如果把体现企业规则的运算程序放入应用程序中,则当企业规则发生变化时,就需要修改应用程序工作量非常之大(修改、发行和安装应用程序)。如果把体现企业规则的运算放入存储过程中,则当企业规则发生变化时,只要修改存储过程就可以了,应用程序无须任何变化。
分类
1)、系统存储过程:以sp_开头,用来进行系统的各项设定.取得信息.相关管理工作, 如 sp_help就是取得指定对象的相关信息,sp_refreshview 是刷新视图 2)、扩展存储过程以XP_开头,用来调用操作系统提供的功能 exec master..xp_cmdshell 'ping 192.168.1.1'
3)、用户自定义的存储过程,这是我们所指的存储过程
存储过程的格式
CREATE PROCEDURE [拥有者.]存储过程名[;程序编号]
[(参数#1,…参数#1024)]
[WITH
{RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION}
]
[FOR REPLICATION]
AS 程序行
其中存储过程名不能超过128个字。每个存储过程中最多设定1024个参数
(SQL Server 7.0以上版本),参数的使用方法如下:
@参数名 数据类型 [VARYING] [=内定值] [OUTPUT]
每个参数名前要有一个“@”符号,每一个存储过程的参数仅为该程序内部使用,参数的类型除了IMAGE外,其他SQL Server所支持的数据类型都可使用。
[=内定值]相当于我们在建立数据库时设定一个字段的默认值,这里是为这个参数设定默认值。[OUTPUT]是用来指定该参数是既有输入又有输出值的,也就是在调用了这个存储过程时,如果所指定的参数值是我们需要输入的参数,同时也需要在结果中输出的,则该项必须为OUTPUT,而如果只是做输出参数用,可以用CURSOR,同时在使用该参数时,必须指定VARYING和OUTPUT这两个语句。
例子
我们一起来看几个例子吧,先来看一下最简单的一个,我们现在要做的工作是查询表City中的所有数据
看代码

 代码
代码

SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <Author,sufei>
-- Create date: <Create Date,2010-09-03>
-- Description: <Description,查询表City的所有信息>
-- =============================================
CREATE PROCEDURE IP_selectAllCity
AS
BEGIN
SELECT * FROM City
END
GO
-- exec IP_selectAllCity
执行的结果如下图
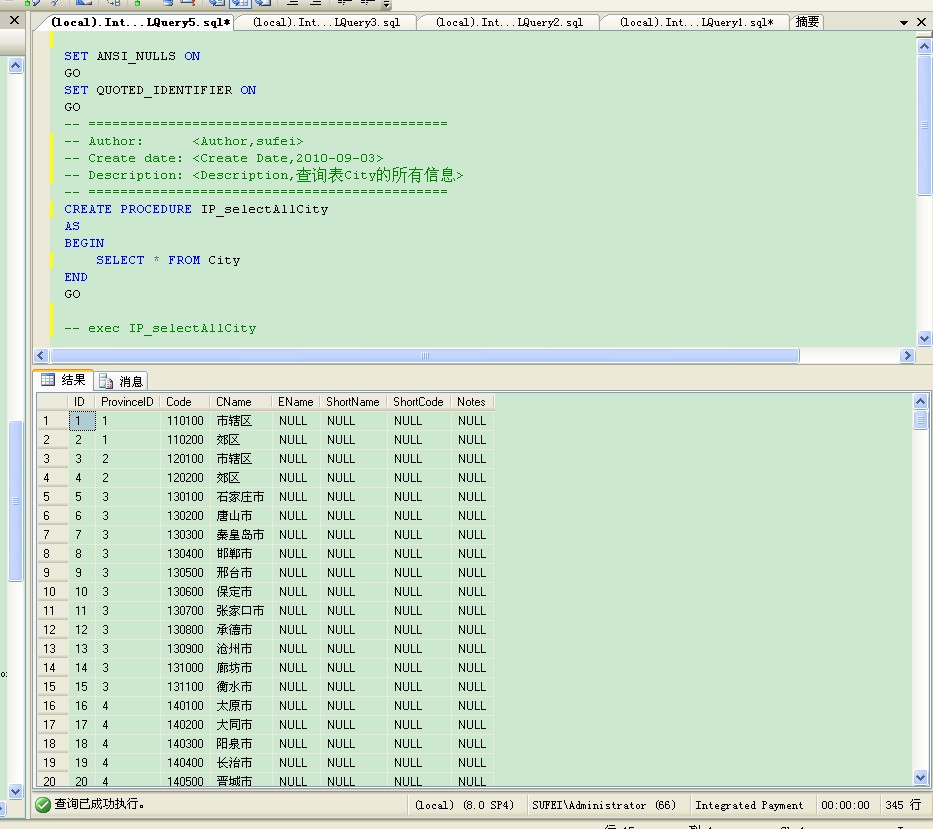
这个是很简单了,下面我们一起分析一个复杂一点的
代码
set QUOTED_IDENTIFIER ON
go
-- =============================================
-- Author: <Author,,sufei>
-- Create date: <Create Date,2010-02-01 2:42>
-- Description: <Description,财务端用来查询各商户各业务的总交易量>
-- =============================================
ALTER proc [dbo].[PGetSaleTableInfo1]
@st as DateTime = '2009-07-01',
@et as DateTime = '2009-07-20'
AS
select t1.*, t2.ofLogin as ofName, t3.fiName from
( --移动
select ormOid as offId, ormType as funid,cast(sum(ormPayAmount) AS decimal(18,2)) as amountsum from ordermobile
where ormState in (2,6) and ormExecTime >= @st and ormExecTime<=@et group by ormOid, ormType
union --联通
select oruOid as offId, oruType as funid,cast(sum(oruPayAmount) AS decimal(18,2)) as amountsum from orderunicom
where oruState in (2,6) and oruExecTime >= @st and oruExecTime<=@et group by oruOid, oruType
union --电信
select ortOid as offId, ortType as funid,cast(sum(ortPayAmount) AS decimal(18,2)) as amountsum from ordertelecom
where ortState in (2,6) and ortExecTime >= @st and ortExecTime<=@et group by ortOid, ortType
) as t1,
officeInfo as t2, functionInfo as t3 where t1.offId = t2.ofId and t1.funid = t3.fiId
order by ofName
--exec PGetSaleTableInfo1 '2010-01-01','2010-03-25'
我们来一起分析一下这个存储过程吧,存储过程的作用是查询出来ordermobile (中国移动缴费记录) orderunicom(中国联通缴费记录) ordertelecom
(中国电信缴费记录)三张表,在一段时间内,各个用户,各个业务的缴费总各。@st as DateTime = '2009-07-01',
@et as DateTime = '2009-07-20' 这是两个时间参数,@st开始时间,@et结束时间。我是利用 Select Union的方式把三个表合并在了一起,然后按用户ID,和业务ID分了一下组,并使用cast(sum(ortPayAmount) AS decimal(18,2)) as amountsum 这一句来得到所有这个用户某个业务的交易总各的sum是求和大家都知道了cast带有四舍五入的功能。
执行一下存储过程我们一起来看一下结果吧
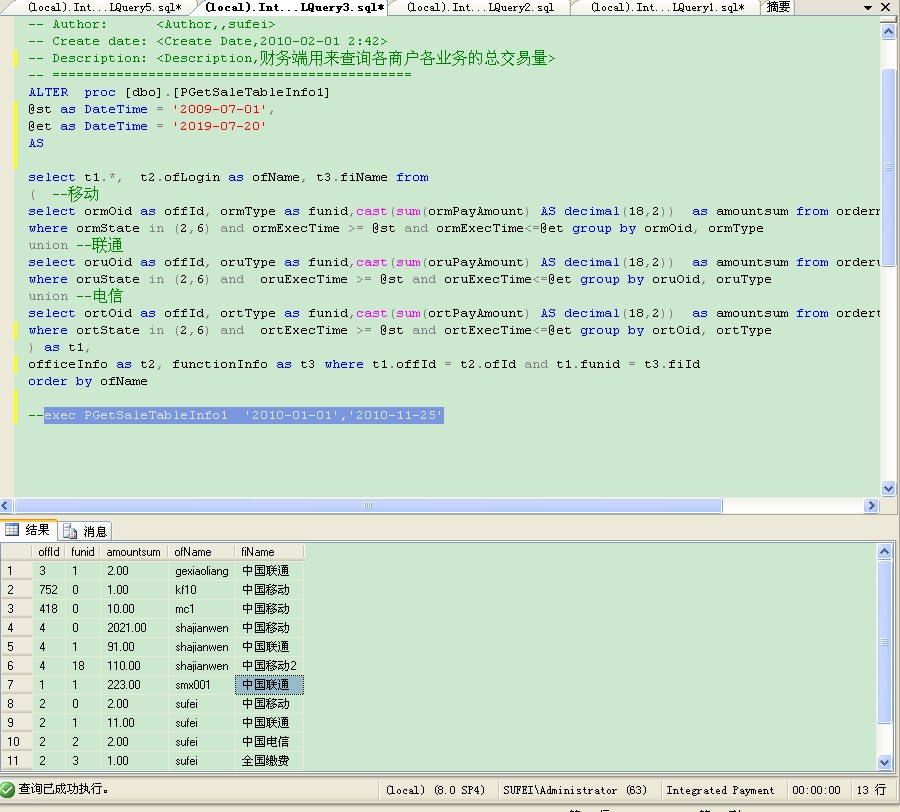
这样的话我们就把每一个用户的每一个业务的交易总各查了出来了。
c#调用Sql2005的存储过程
现在我们使用c#来调用 一下这个存储过程吧,我在这里使用SqlHelper 类
代码
/// 财务端用来查询各业务的总交易量
/// </summary>
/// <param name="startTime">开始时间</param>
/// <param name="endtime">结束时间</param>
/// <returns>DataTable</returns>
public DataTable PGetSaleTableInfo1(DateTime startTime, DateTime endtime)
{
SqlParameter[] parameters = {
new SqlParameter("@sdt ", SqlDbType.DateTime),
new SqlParameter("@edt", SqlDbType.DateTime)};
parameters[0].Value = startTime;
parameters[1].Value = endtime;
return SqlHelper.GetTableProducts("PGetSaleTableInfo1", parameters)[0];
}
我们要以传进去两个时间就可以了。前台查询得到的效果如下
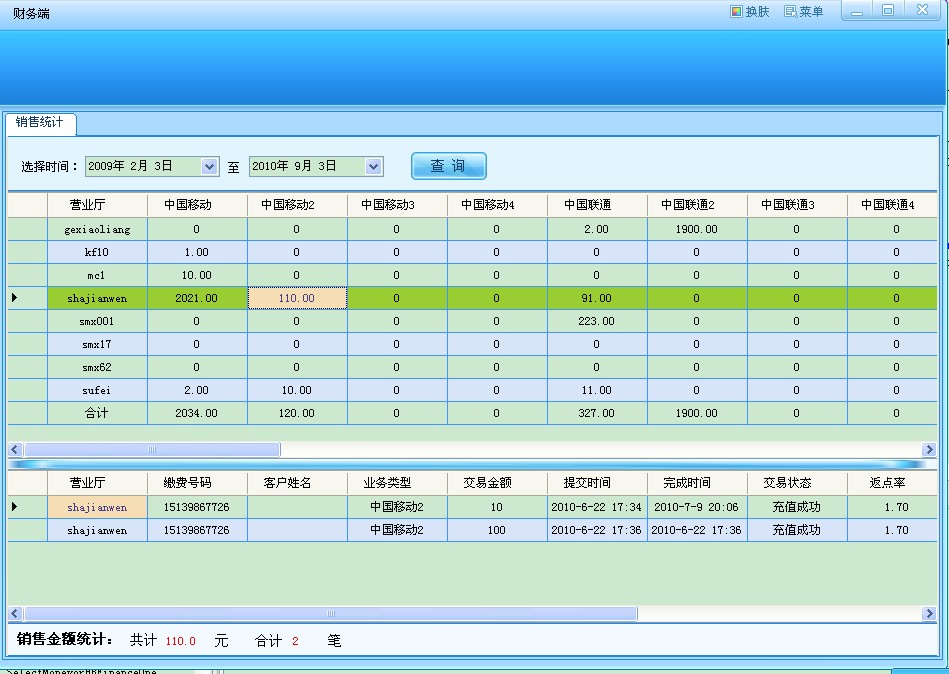
当然,这是经过我处理过后的结果,我是把业务当成了列,并且在单击每一个金额是能查出相应的来源,
在这里我可以简单的提供一下思路,如果有朋友对这一块感兴趣的话,咱们可以交流一下的
我可以把我是怎么样生成这个表的代码放在这里,
代码
private DataTable binder(DataTable tables)
{
DataTable dt_Sale = new DataTable();
DataColumn dc = null;
//营业厅
dc = new DataColumn();
dc.ColumnName = "Oid";
dc.DefaultValue = "null";
dt_Sale.Columns.Add(dc);
//中国移动
dc = new DataColumn();
dc.ColumnName = "mobile";
dc.DefaultValue = "0";
dt_Sale.Columns.Add(dc);
//中国移动
dc = new DataColumn();
dc.ColumnName = "mobile2";
dc.DefaultValue = "0";
dt_Sale.Columns.Add(dc);
//中国移动
dc = new DataColumn();
dc.ColumnName = "mobile3";
dc.DefaultValue = "0";
dt_Sale.Columns.Add(dc);
//中国移动
dc = new DataColumn();
dc.ColumnName = "mobile4";
dc.DefaultValue = "0";
dt_Sale.Columns.Add(dc);
//在这里扩展新业务
DataRow dr = dt_Sale.NewRow();
Boolean f = false;
for (int j = 0; j < tables.Rows.Count; j++)
{
//中国移动
if (tables.Rows[j]["funid"].ToString().Trim() == "0")
{
dr["mobile"] = tables.Rows[j]["amountsum"].ToString().Trim();
}
//中国移动
if (tables.Rows[j]["funid"].ToString().Trim() == "18")
{
dr["mobile2"] = tables.Rows[j]["amountsum"].ToString().Trim();
}
//中国移动
if (tables.Rows[j]["funid"].ToString().Trim() == "27")
{
dr["mobile3"] = tables.Rows[j]["amountsum"].ToString().Trim();
}
//中国移动
if (tables.Rows[j]["funid"].ToString().Trim() == "33")
{
dr["mobile4"] = tables.Rows[j]["amountsum"].ToString().Trim();
}
//在这里扩展新业务
//表示如果两行的OFFId相同的话只增加一行
if (j != tables.Rows.Count - 1)
{
if (tables.Rows[j]["offId"].ToString().Trim() != tables.Rows[j + 1]["offId"].ToString().Trim())
{
f = true;
}
else
{
f = false;
}
}
else
{
f = true;
}
//营业厅
dr["Oid"] = tables.Rows[j]["ofName"].ToString().Trim();
//是否要添加行
if (f)
{
dt_Sale.Rows.Add(dr);
dr = dt_Sale.NewRow();
}
}
return dt_Sale;
}
//在这里扩展新业务 大家在扩展的时候只要看到这一行字,在下面接着增加新业务就是了,只要能得到这个表,我相信下面的统计,什么的应该都很简单了吧,只要一个枚举类统计一下各个业务的和就是了,呵呵
接着来看存储过程
下面我们再来看一下分页的存储过程吧,在Sql2005里有了row_number()函数我们处理分页就显的非常的简单了
看下代码吧
代码
GO
/****** 对象: StoredProcedure [dbo].[CP_select_All_Customer] 脚本日期: 03/10/2009 21:09:12 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: sufei
-- Create date: <2009-2-16,,>
-- Description: <查询所有的用户信息
---Table (手机号,用户名,用户信箱,用户年龄,性别,用户职业,兴趣爱好,现居地,用户积分,注册时间 ,备注)
-- =============================================
ALTER PROCEDURE [dbo].[CP_select_All_Customer]
@startindex int ,
@pagesize int
AS
BEGIN
with NewCustomer as (
select row_number()over (order by Cus_Id)as rownumber, Cus_MSISDN,Cus_Name,Cus_Email,Cus_Age,Cus_Sex,Cus_Job,Cus_Intrestings,Cus_Address,Cus_Value,Cus_RegTime,Cus_Remark,Cus_State
from Customer
where Isdelete=0
)
select rownumber, Cus_MSISDN,Cus_Name,Cus_Email,Cus_Age,Cus_Sex,Cus_Job,Cus_Intrestings,Cus_Address,Cus_Value,Cus_RegTime,Cus_Remark,Cus_State
from NewCustomer
where rownumber >=(@startindex-1)*@pagesize+1 and rownumber<=(@startindex-1)*@pagesize+(@pagesize)
select count(*) from Customer where Isdelete=0
END
如果大家对分页有兴趣的话我这里还有一个例子 介绍一下和AspNetPager结合的不错的分页方案
存储过程的缺点
1:调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
2:移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
3:重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
4: 如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变化,接着就是系统的相关问题了,最后如果用户想维护该系统可以说是很难很难、而且代价是空前的。维护起来更加麻烦!
总之一句话,应该用的地方用,不要一味的使用就行了,根据自己的项目来定。可以彩票部分使用,比如一个执行量大,或是比较重要的查询写入,可以使用存储过程来完成。
另外存储过程里还有一个临时表的东东
可以创建本地和全局临时表。本地临时表仅在当前会话中可见;全局临时表在所有会话中都可见。
本地临时表的名称前面有一个编号符 (#table_name),而全局临时表的名称前面有两个编号符 (##table_name)。
SQL 语句使用 CREATE TABLE 语句中为 table_name 指定的名称引用临时表:
CREATE TABLE #MyTempTable (cola INT PRIMARY KEY)
INSERT INTO #MyTempTable VALUES (1)
如果本地临时表由存储过程创建或由多个用户同时执行的应用程序创建,则 SQL Server 必须能够区分由不同用户创建的表。为此,SQL Server 在内部为每个本地临时表的表名追加一个数字后缀。存储在 tempdb 数据库的 sysobjects 表中的临时表,其全名由 CREATE TABLE 语句中指定的表名和系统生成的数字后缀组成。为了允许追加后缀,为本地临时表指定的表名 table_name 不能超过 116 个字符。
除非使用 DROP TABLE 语句显式除去临时表,否则临时表将在退出其作用域时由系统自动除去:
当存储过程完成时,将自动除去在存储过程中创建的本地临时表。由创建表的存储过程执行的所有嵌套存储过程都可以引用此表。但调用创建此表的存储过程的进程无法引用此表。
所有其它本地临时表在当前会话结束时自动除去。
全局临时表在创建此表的会话结束且其它任务停止对其引用时自动除去。任务与表之间的关联只在单个 Transact-SQL 语句的生存周期内保持。换言之,当创建全局临时表的会话结束时,最后一条引用此表的 Transact-SQL 语句完成后,将自动除去此表。
有关特殊的存储过程触发器的问题我直接放在了触发器这一节里来写了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· [AI/GPT/综述] AI Agent的设计模式综述