MySQL中Replace into语句与Insert into on duplicate key update语句对比
1.初始化表和测试数据
CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c; ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ; INSERT INTO t1 SELECT 2,'2', '3'; insert into t1(b,c) select 'r2','r3';
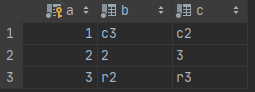
2.replace语句测试
replace into是insert into 的加强版,既可以更新数据也可以插入数据;
它的执行逻辑是:首先判断是否存在相同的唯一主键或者唯一索引,如果存在,则更新数据,否则,插入数据。例如:
[SQL]REPLACE INTO t1(a,b,c) VALUES(2,'22','22') ; 受影响的行: 2 时间: 0.048s
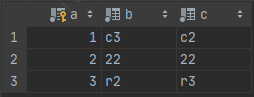
之所以会是2行数据受到影响,是因为表中已存在主键为2的数据,mysql先将原有的数据删除,并将新的数据插入,因此受影响的是2行数据。
再看下面的例子:
[SQL]REPLACE INTO t1(a) VALUES(3) ; 受影响的行: 2 时间: 0.039s
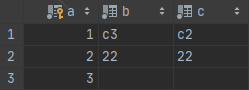
可以看出,确实是先删除后插入,当主键存在时,replace覆盖相关字段,其它字段填充默认值,可以理解为删除重复key的记录,新插入一条记录,一个delete原有记录再insert的操作。
insert into on duplicate key udpate 和replace into 类似,也是可以插入和更新,它们的不同点是,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
关于insert on update的详细用法和说明可以看我其他两篇文章:
Mysql死锁排查:insert on duplicate死锁一次排查分析过程
Mybatis大量数据的插入或更新操作方案思考(使用ON DUPLICATE KEY UPDATE)
3.总结
如果存在相同的主键或唯一索引,replace into 相当于先删除数据而后在插入,如果不存在相同的主键和唯一索引,则直接插入。
如果存在相同的主键或唯一索引,insert into on duplicate key update只更新update后面的字段,相当于udpate ;如果不存在相同的主键或唯一索引,则直接插入。
本博客文章均已测试验证,欢迎评论、交流、点赞。
部分文章来源于网络,如有侵权请联系删除。
转载请注明原文链接:https://www.cnblogs.com/sueyyyy/p/13087343.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号