用分支/合并框架执行并行求和
分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任 务的结果合并起来生成整体结果。它是 ExecutorService 接口的一个实现,它把子任务分配给 线程池(称为 ForkJoinPool )中的工作线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | import java.util.concurrent.ForkJoinPool;import java.util.concurrent.ForkJoinTask;import java.util.concurrent.RecursiveTask;import java.util.stream.LongStream;/** * @ClassName ForkJoinSumCaculator * @Description 用分支/合并框架执行并行求和 * @Author Sue * @Create 2020/3/23 11:18 **/public class ForkJoinSumCaculator extends RecursiveTask<Long> { //继承RecursiveTask来创建可以用于分支/合并框架的任务 /** * 要求和的数组、子任务处理的数组的起始和终止位置 */ private final long[] numbers; private final int start; private final int end; /** * 不再将任务分解为子任务的数组的大小 */ public static final long THRESHOLD = 10_000; /** * 公共构造函数用于创建主任务 * @param numbers */ public ForkJoinSumCaculator(long[] numbers) { this(numbers, 0, numbers.length); } /** * 私有构造函数用于以递归方式为主任务创建子任务 * @param numbers * @param start * @param end */ private ForkJoinSumCaculator(long[] numbers,int start,int end){ this.numbers = numbers; this.start = start; this.end = end; } /** * 该任务负责求和的部分的大小 * 覆盖 RecursiveTask 抽象方法 * @return */ @Override protected Long compute() { int length = end - start; if(length <= THRESHOLD){ //如果大小小于或等于阈值,顺序计算结果 return computeSequentially(); } //创建一个子任务来为数组的前一半求和 ForkJoinSumCaculator leftTask = new ForkJoinSumCaculator(numbers, start + length / 2, end); //利用另 一 个ForkJoinPool线程异步执行新创建的子任务 leftTask.fork(); //创建一个任务为数组的后一半求和 ForkJoinSumCaculator rightTask = new ForkJoinSumCaculator(numbers, start + length / 2, end); //同步执行第二个子任务,有可能允许进一步递归划分 Long rightResult = rightTask.compute(); //读取第一个子任务的结果,如果尚未完成就等待 Long leftResult = leftTask.join(); return leftResult + rightResult; } /** * 在子任务不再可分时计算结果的简单算法 * @return */ private long computeSequentially(){ long sum = 0; for (int i = start;i < end;i++){ sum += numbers[i]; } //该任务的结果是两个子任务结果的组合 return sum; } public static long forkJoinSum(long n) { long[] numbers = LongStream.rangeClosed(1, n).toArray(); ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers); return new ForkJoinPool().invoke(task); }} |
这里用了一个 LongStream 来生成包含前n个自然数的数组,然后创建一个 ForkJoinTask( RecursiveTask 的父类),并把数组传递给代码所示 ForkJoinSumCalculator 的公共构造函数。最后,创建了一个新的 ForkJoinPool ,并把任务传给它的调用方法 。在ForkJoinPool 中执行时,最后一个方法返回的值就是 ForkJoinSumCalculator 类定义的任务结果。 请注意在实际应用时,使用多个 ForkJoinPool 是没有什么意义的。正是出于这个原因,一 般来说把它实例化一次,然后把实例保存在静态字段中,使之成为单例,这样就可以在软件中任 何部分方便地重用了。这里创建时用了其默认的无参数构造函数,这意味着想让线程池使用JVM 能够使用的所有处理器。更确切地说,该构造函数将使用 Runtime.availableProcessors 的 返回值来决定线程池使用的线程数。请注意 availableProcessors 方法虽然看起来是处理器, 但它实际上返回的是可用内核的数量,包括超线程生成的虚拟内核。
运行 ForkJoinSumCalculator
当把 ForkJoinSumCalculator 任务传给 ForkJoinPool 时,这个任务就由池中的一个线程 执行,这个线程会调用任务的 compute 方法。该方法会检查任务是否小到足以顺序执行,如果不 够小则会把要求和的数组分成两半,分给两个新的 ForkJoinSumCalculator ,而它们也由 ForkJoinPool 安排执行。因此,这一过程可以递归重复,把原任务分为更小的任务,直到满足 不方便或不可能再进一步拆分的条件(本例中是求和的项目数小于等于10 000)。这时会顺序计 算每个任务的结果,然后由分支过程创建的(隐含的)任务二叉树遍历回到它的根。接下来会合 并每个子任务的部分结果,从而得到总任务的结果。这一过程如图所示。
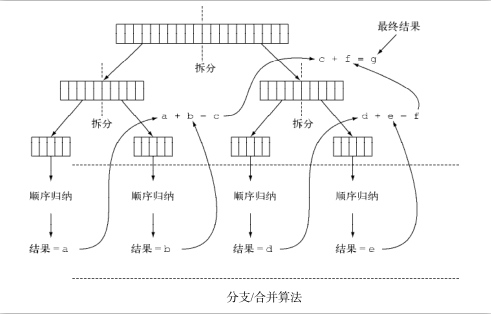
使用分支/合并框架的最佳做法
虽然分支/合并框架还算简单易用,不幸的是它也很容易被误用。以下是几个有效使用它的 最佳做法。
- 对一个任务调用 join 方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子 任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂, 因为每个子任务都必须等待另一个子任务完成才能启动。
- 不应该在 RecursiveTask 内部使用 ForkJoinPool 的 invoke 方法。相反,你应该始终直 接调用 compute 或 fork 方法,只有顺序代码才应该用 invoke 来启动并行计算。
- 对子任务调用 fork 方法可以把它排进 ForkJoinPool 。同时对左边和右边的子任务调用 它似乎很自然,但这样做的效率要比直接对其中一个调用 compute 低。这样做你可以为 其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。
- 调试使用分支/合并框架的并行计算可能有点棘手。特别是你平常都在你喜欢的IDE里面 看栈跟踪(stack trace)来找问题,但放在分支/合并计算上就不行了,因为调用 compute 的线程并不是概念上的调用方,后者是调用 fork 的那个。
- 和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计 算快。我们已经说过,一个任务可以分解成多个独立的子任务,才能让性能在并行化时 有所提升。所有这些子任务的运行时间都应该比分出新任务所花的时间长;一个惯用方 法是把输入/输出放在一个子任务里,计算放在另一个里,这样计算就可以和输入/输出 同时进行。此外,在比较同一算法的顺序和并行版本的性能时还有别的因素要考虑。就 像任何其他Java代码一样,分支/合并框架需要“预热”或者说要执行几遍才会被JIT编 译器优化。这就是为什么在测量性能之前跑几遍程序很重要,我们的测试框架就是这么 做的。同时还要知道,编译器内置的优化可能会为顺序版本带来一些优势(例如执行死 码分析——删去从未被使用的计算)。
- 对于分支/合并拆分策略还有最后一点补充:你必须选择一个标准,来决定任务是要进一步 拆分还是已小到可以顺序求值。
本博客文章均已测试验证,欢迎评论、交流、点赞。
部分文章来源于网络,如有侵权请联系删除。
转载请注明原文链接:https://www.cnblogs.com/sueyyyy/p/12552411.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix