Python数据容器
1. 容器
-
定义:容纳多份数据的数据类型。Python的数据容器可以理解为C++中的数据结构,这些数据结构的方法多为“增删改查”。
-
容器类型:列表、元组、字符串、
2. 列表list
-
列表可理解为数组,下标从0开始。
-
定义
定义代码
name_list = ['zhangsan', 'lisi', 'wangwu'] # 字符串 num_list = [2, 3, 4] # 整型 li_list = [[1,2,3], ['lisi', 'wangwu'], [1]] # 列表 -
查询
查询代码
print(name_list[0]) # 输出字符串列表下标为0的元素 print(num_list[2]) # 输出整型列表下标为2的元素 print(li_list[1]) # 输出列表类型列表下标为0的元素 print(name_list[-1]) # 输出字符串列表最后一个元素 print(name_list[-2]) # 输出字符串列表倒数第二个元素 -
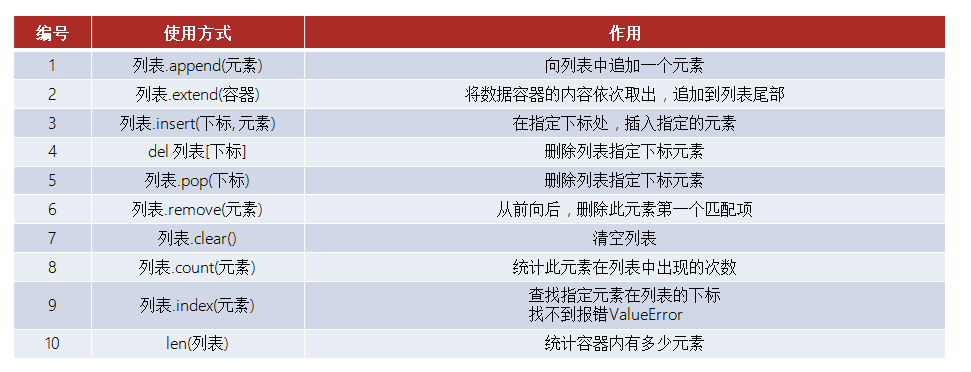
方法如下:
![]()
查询元素对应下标
print(name_list.index('lisi')) # 输出name_list中“lisi”的下标 print(li_list[1].index('lisi')) # 输出li_lis中1号元素中“lisi”的下标修改
num_list[0] = 5 # 将num_list中的0号元素修改为5 num_list[-2] = 0 # 将num_list中的倒数第二个修改为0 print(num_list)插入
name_list.insert(1, 'libai') # 在name_list的1号元素前插入'libai' print(name_list) num_list.append(0) # 在num_list末尾插入0 print(num_list) num_list.append([1, 2]) # 在num_list末尾插入列表[1, 2] print(num_list) num_list.extend(name_list) # 将name_list中的元素插入到num_list末尾 print(num_list)删除
print(num_list) num_list.pop(7) # 删除num_list的8号元素 print(num_list)删除查找到的元素
num_list.remove('libai') # 删除num_list中查找到的元素‘libai’ print(num_list)统计列表中某个元素的个数
print(num_list.count(0)) # 统计num_list中0的个数统计列表长度(元素个数)
len(num_list)清空列表
num_list.clear() # 清空num_list print(num_list) -
遍历
定义:将容器内的元素依次取出,并处理的操作。while遍历
index = 0 # index记录num_list的下标 while index < len(num_list) : print(num_list[index], end=' ') index += 1 print()for遍历
for i in num_list : # 将num_list中的元素依次存入临时变量i print(i, end=' ')注:while可自定义循环条件,for不行,for只能从容器依次取出元素。
特点:
- 可以容纳多个元素(上限为2**63-1、9223372036854775807个)
- 可以容纳不同类型的元素(混装)
- 数据是有序存储的(有下标序号)
- 允许重复数据存在
- 可以修改(增加或删除元素等)
3. 元组tuple
-
元组和列表区别:元组内数据不能更改,列表数据可以。
-
定义
("abc", 8, True) -
注意:元组只有一个数据时,该数据后面需加“,”。
t2 = (1, ) # 单个数据元组 -
方法
按下标查值
print(t1[1]) # 与列表相似,用下标索引按值查下标
print(t1.index(8))统计某个元素出现次数
print(t3.count(5))统计元组长度(元素个数)
print(len(t1))总结:元组内的数据无法更改(即第一个下标数据无法更改),元组内列表的数据可以更改(即第二个下标数据可以更改),但元组内列表本身不能修改。修改
t4[0] = 5 # 无法直接修改元组内的数据,会报错 t4[2][1] = 1 # 可修改元组内的列表数据 t4[2] = [1] # 不能替换元组内的列表,会报错 print(t4)遍历:与列表一致。
特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是有序存储的(下标索引)
- 允许重复数据存在
- 不可以修改(增加或删除元素等)
- 支持for循环
4. 字符串str
-
定义:即C和C++中的字符数组,区别是Python中的字符串无法修改。
-
方法
按下标查值
print(name[1]) print(name[-2])按值查下标
print(name.index('n')) # 从name中查找‘n’的下标 print(name.index(new_name)) # 从name中查找new_name的下标注:Python中的字符串替换并不是在原来字符串中进行,而是创建了一个新的字符串,原字符串并未改变。替换
name1 = name.replace("a", new_name1) # 将name中的‘n’替换成new_name在赋值给name1,name自身的值未发生改变 print(name) # 原字符串并未改变 print(name1)分割
name_list = my_name.split(" ") print(name_list) print(type(name_list))规整
my_str = " abc w 312 " my_str1 = "12 abc w 321" print(my_str.strip()) # 去除前后空格 print(my_str1.strip("12")) # 按照单个字符,排除最后出现的‘1’和‘2’统计字符串出现次数
print(name.count("an"))统计长度(字符个数)
print(len(name))特点:
- 只可以存储字符串
- 长度任意(取决于内存大小)
- 支持下标索引
- 允许重复字符串存在
- 不可以修改(增加或删除元素等)
- 支持for循环
5. 序列
-
定义:内容连续、有序,支持重复元素,可使用下标索引的数据容器。列表、元组、字符串,均可视为序列。
-
方法
切片
my_list = [1, 2, 3, 4, 5] my_tuple = (1, 2, 3, 4, 5) my_str = "12345" new_list = my_list[:] # 从头到尾 new_list1 = my_list[1:4] # 下标从1到4的列表 new_list2 = my_list[3:1:-1] # 下标从3到1且倒序的列表 new_tuple = my_tuple[::2] # 下标从头到最后且步长为2的元组 new_tuple1 = my_tuple[::-1] # 下标从头(最后)到最后(首)且倒序的元组 new_str = my_str[1:4:2] # 下标从1到4且步长为2的字符串 new_str1 = my_str[:1:-2] # 下标从头(最后)到1且步长为-2(倒序步长为2)的字符串 print(new_list) print(new_list1) print(new_list2) print(new_tuple) print(new_tuple1) print(new_str) print(new_str1)
6. 集合set
-
定义:与列表、元组、字符串不同,集合的元素是不重复且无序的。
-
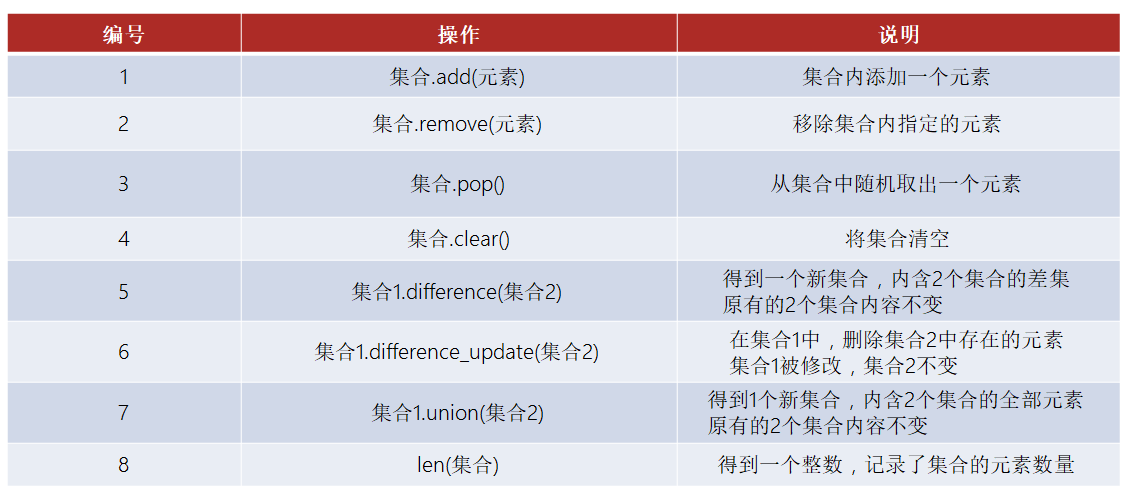
方法
![]()
定义空集合
# my_set = {} # 这样定义的为空字典,不是空集合 my_set = set() # 定义空集合注:因为要对元素做去重处理,所以无法保证顺序和创建的时候一致。
特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是无序存储的(不支持下标索引)
- 不允许重复数据存在
- 可以修改(增加或删除元素等)
- 支持for循环
7. 字典、映射dict
-
定义:通过映射检索关键字的值;格式为key:value,各种key检索value。关键字不可重复,不支持下标索引。支持for循环,不支持while循环。
stu_score = {"张三":12, "李四":80} -
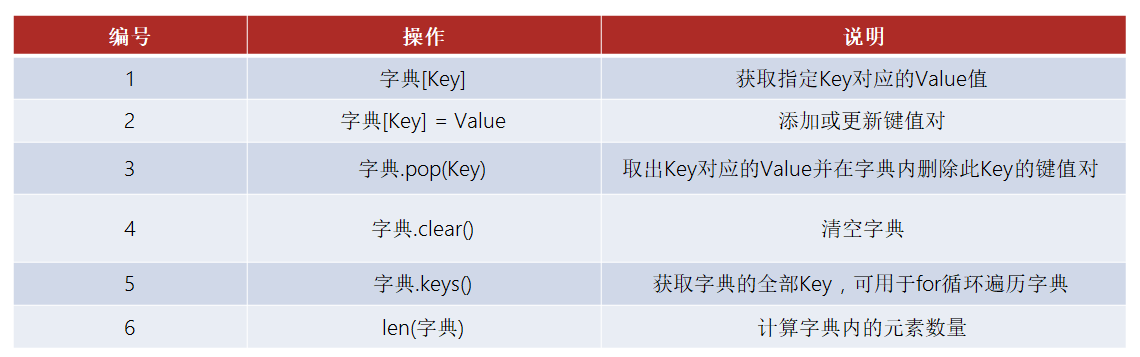
方法
![]()
注:
- 只能通过key检索value,不可通过value检索key
- 键值对的Key和Value可以是任意类型(Key不可为字典)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
- 字典不可用下标索引,而是通过Key检索Value
遍历
keys = stu_score.keys() # 先用一个变量获取字典的全部key for key in keys: print(f"学生:{key},分数:{stu_score[key]}")特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据
- 每一份数据是KeyValue键值对
- 可以通过Key获取到Value,Key不可重复(重复会覆盖)
- 不支持下标索引
- 可以修改(增加或删除更新元素等)
- 支持for循环,不支持while循环
8. 非序列
- 定义:内容无序,不可重复,不可使用下标索引的数据容器。集合、字典,均可视为非序列。
9. 总结
-
列表:一批数据,可修改、可重复的存储场景,用“ [] ”定义
-
元组:一批数据,不可修改、可重复的存储场景,用“ () ”定义
-
字符串:一串字符串的存储场景,用“ "" ”定义
-
集合:一批数据,去重存储场景,用“ {} ”定义
-
字典:一批数据,可用Key检索Value的存储场景,用“ {key:value,...,key:value} ”定义
-
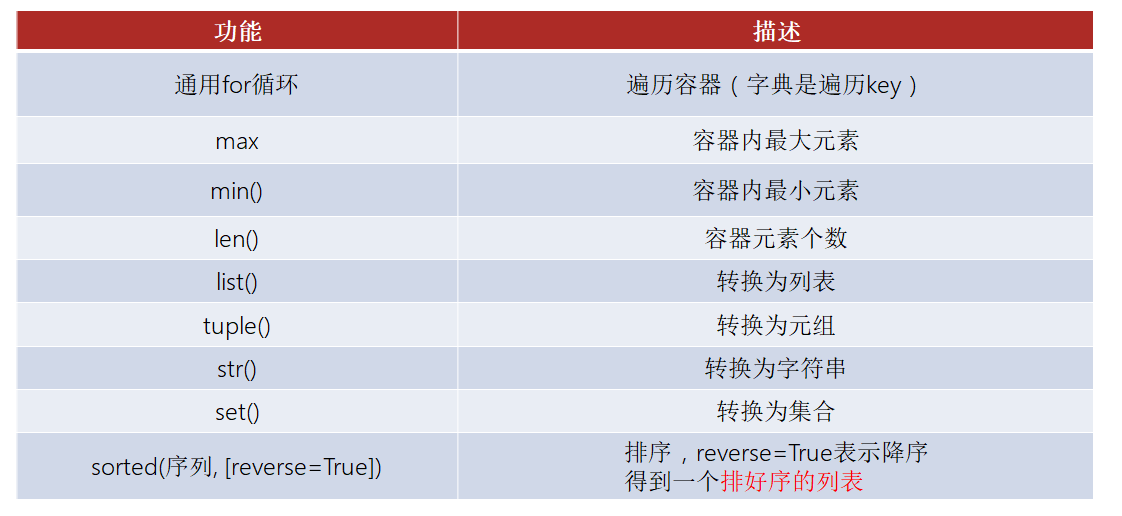
容器通用功能
![]()
-
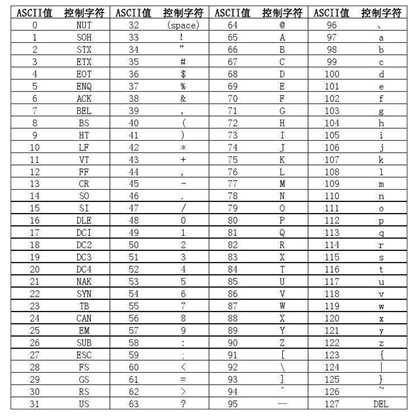
字符串比较
ASCII码表:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号