EasyPR--开发详解(7)字符分割
大家好,好久不见了。
一转眼距离上一篇博客已经是4个月前的事了。要问博主这段时间去干了什么,我只能说:我去“外面看了看”。

图1 我想去看看
在外面跟几家创业公司谈了谈,交流了一些大数据与机器视觉相关的心得与经验。不过由于各种原因,博主又回来了。
目前,博主的工作是在本地的一个高校做科研。而研究的方向主要是计算机视觉。

图2 科研就是不断的探索过程
由于我所做的是计算机视觉方向,跟EasyPR本身非常契合。未来这个这个系列的博客会继续下去,并且以后会有更加专业的内容。
目前我研究的方向是文字定位,这个技术跟车牌定位很像,都是在图中去定位一些语言相关的位置。不同之处在于,车牌定位只需要处理的是在车牌中出现的文字,字体,颜色都比较固定,背景也比相对单一(蓝色和黄色等)。
文字定位则复杂很多,研究界目前要处理的是是各种类型,不同字体,且拥有复杂背景的文字。下图是一张样例:

图3 文字定位图片样例
可以看出,文字定位要处理的问题是类似车牌定位的,不过难度要更大。一些文字定位的技术也应该可以应用于车牌的定位和识别。
未来EasyPR会借鉴文字定位的一些思想和技术,来强化其定位的效果。
一.前言
今天继续我们EasyPR的开发详解。
这几个月我收到了不少的邮件问:为什么EasyPR开发详解教程中只有车牌定位的部分,而没有字符识别的部分?
这个原因一是由于整个开发详解是按照车牌识别的流程顺序来的,因此先讲定位,后面再讲字符识别。所以字符识别的部分出来的比较晚。
二是由于字符识别相对于前面的车牌定位而言,显得较为简单。不像在一个复杂和低分辨场景下进行车牌定位,在字符分割和识别的部分时,所需要处理的场景已经较为固定了,因此其处理技术也较为单一。
这两个原因是字符分割和识别部分出来较晚的原因。不过在本篇博客中我们会将字符分割部分讲完。
二.整体流程
我们首先看一下,字符分割所需要处理的输入: 即是前面车牌定位中的结果,一个完整的车牌。
 图4 字符分割模块的输入
图4 字符分割模块的输入
由于在车牌定位中,我们使用了归一化过程。因此所需要处理的车牌的大小是统一的,在目前的版本中(v1.3),这个值是136*36。
那么字符分割的结果就是将车牌中的所有文字一一分割开来,形成单一的字符块。生成的字符块就可以输入下一步的字符识别部分进行识别。在EasyPR里,字符识别所使用的技术是人工神经网络,也就是ANN。
具体而言,字符分割过程是如何做的呢?简单说,就是:灰度化->颜色判断->二值化->取轮廓->找外接矩形->截取图块。
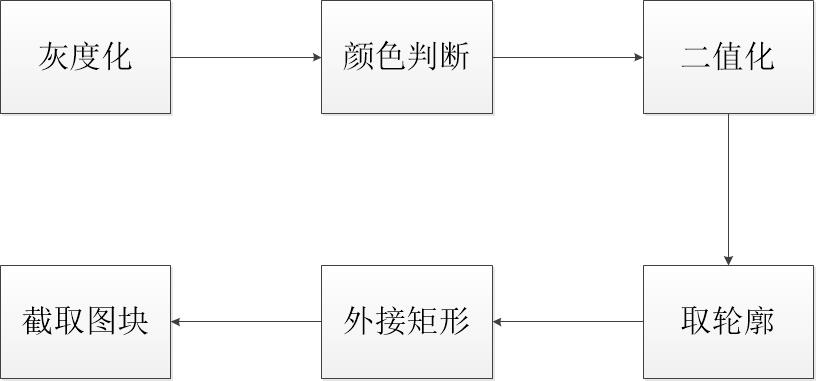
图5 字符分割处理流程
下面,我们使用下图的车牌完整的跑一遍字符分割的流程,以此对其有一个全局的认识。

图6 原始图片
1.灰度化
首先,我们把彩色的图片转化为灰度化图片。注意:为了以后可以利用彩色信息,在前面的车牌检测过程中,我们的输出结果不是灰度化图片,而是彩色图片。这样以后当我们改正算法,想利用彩色信息时就可以使用了。
但是在这里,我们的算法还是针对的是灰度化图片,因此首先进行灰度化处理。
灰度化后的图片见下图:

图7 灰度化后结果
2.颜色判断
灰度化之后,为了分割字符。我们需要获取字符的轮廓。注意:分割字符有很多种方法。例如投影法,滑动窗口判断法,在这里,EasyPR使用的是取字符轮廓法。
因为需要取轮廓,就需要把图片转化成一个二值化图片。不过,由于蓝色和黄色车牌图片的区别,两者需要用的二值化参数不一样,因此这里需要对车牌图片的颜色进行一个判断。车牌颜色对二值化的影响的分析见后面“其他细节”章节。
这里颜色判断的使用的是前面颜色定位详解里的模板匹配法。

图8 颜色判断
3.二值化
获取颜色后,就可以选择不同的参数进行大津阈值法来进行二值化。对于本示例图片中的蓝色车牌而言,使用的参数为CV_THRESH_BINARY。
二值化后的效果见下图:

图9 二值化后结果
4.取轮廓
接下来,使用被多次用到的取轮廓方法findContours。关于这个方法的具体内容,在前面的开发详解中已做过介绍,这里不再赘述。
取轮廓后的结果如下图:

图10 取轮廓操作
注意:直接使用findContours方法取轮廓时,在处理中文字符,也就是“苏”时,会发生断裂现象。因此为了处理中文字符,EasyPR换了一种思路,使用了额外的步骤来解决这个问题。具体可以见后面的“中文字符处理”章节。
5.找外接矩形
使用了中文字符处理方法以后,成功获取了所有的字符的外接矩形。
具体见下图:

图11 所有字符的外接矩形
6.截取图块
最后,把图中的外接矩形一一截取出来,归一化到统一格式。留待输入下个步骤--字符识别模块处理。
归一化后字符图块见下图:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
图12 截取并归一化的图块
三.中文字符处理
上面的流程在处理英文车牌时,效果是很好的。但是在处理中文车牌时,存在一个很大的问题。
在取轮廓时,中文由于自身的特性,例如有笔画区间,取轮廓会造成断裂现象。例如下图中的“苏”。英文字符通过取轮廓都被完整的包括了,而“苏”字则分成了两个连通区域。

图13 取轮廓操作示例
虽然并不是所有的中文都会存在这个问题(例如下图的“津”字),但直接用取轮廓操作已经不合适了。
EasyPR是如何解决这个问题的呢?其实想法很简单。那就是既然有些中文字符没办法用取轮廓处理,那么就干脆先不处理中文字符,而是用取轮廓操作处理中文字符后面的字符。例如“苏A88M88”,其中“A88M88”这六个字符我都能用取轮廓操作获得。我先获取这六个字符,再想办法获取中文字符。

图14 “津”字
获取这六个字符后,接下来该如何获取“苏”这个中文字符的轮廓呢?
这里的关键就是“苏”字符后面的“A”字符,这个字符在中文车牌里代表城市的代码,我们在这里简称它为“城市字符”或者“特殊字符”。
这个字符有一个特征,就是与后面的字符存在一定的间隔。但是与前面的中文字符靠的较紧。倘若我获取了这个特殊字符的外接矩形,只要把这个外接矩形向左做一些的偏移(偏移的大小可以通过经验指定,例如设置为字符宽度的1.15倍),这样这个外接矩形就成了包含中文字符的一个矩形了。下面就可以截取中文字符的图块。
下图就是“特殊字符”与被反推得到的“中文字符”的矩形,在图中用红色矩形表示。

图15 反推得到的中文字符位置
下面的问题就是如何获取“特殊字符”的位置?
一种方法是把所有取轮廓操作获取到的矩形进行排序,最左边的就是特殊字符的图块。但是有些中文字符会被取轮廓操作截取为一个连通区域。在这种情况下,最左边的图块矩形是中文字符的矩形,而不是特殊字符的矩形了。所以这个方法不能用。
另一种方法就是依次判断所有取轮廓操作得到的矩形的位置,设矩形的中点恰好在整个车牌的1/7到2/7之间时的矩形为特殊矩形。这样操作的前提是我们的车牌定位的非常准确,恰到把整个车牌截取的正正好。在这种情况下,只要外接矩形满足这些条件,就可以判断为特殊字符的矩形。
这个方法思路很简单,实际中应用效果也不错,因此也是EasyPR目前采用的方法。
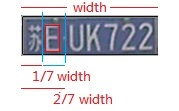
图16 获取特殊字符的位置
以下是特殊字符判断的代码:


//! 找出指示城市的字符的Rect,例如苏A7003X,就是"A"的位置 int CCharsSegment::GetSpecificRect(const vector<Rect>& vecRect) { vector<int> xpositions; int maxHeight = 0; int maxWidth = 0; for (size_t i = 0; i < vecRect.size(); i++) { xpositions.push_back(vecRect[i].x); if (vecRect[i].height > maxHeight) { maxHeight = vecRect[i].height; } if (vecRect[i].width > maxWidth) { maxWidth = vecRect[i].width; } } int specIndex = 0; for (size_t i = 0; i < vecRect.size(); i++) { Rect mr = vecRect[i]; int midx = mr.x + mr.width / 2; //如果一个字符有一定的大小,并且在整个车牌的1/7到2/7之间,则是我们要找的特殊字符 //当前字符和下个字符的距离在一定的范围内 if ((mr.width > maxWidth * 0.8 || mr.height > maxHeight * 0.8) && (midx < int(m_theMatWidth / 7) * 2 && midx > int(m_theMatWidth / 7) * 1)) { specIndex = i; } } return specIndex; }
以上就是EasyPR能处理中文车牌的主要原因。原先的taotao1233的代码中无法处理中文的原因就是没有这样一步预处理。其实这是一个很简单的思想,但在之前并没有被实现。EasyPR里实现了这个思路,同时发现,这个方法效果出奇的好。基本可以应对所有的情况。所以说,这个方法可以说是一个简单,有效的处理中文车牌的方法。
四.其他一些细节
1.颜色判断
在进行二值化前,需要进行一次颜色判断,这是因为对于蓝色和黄色车牌而言,使用的二值化策略必须不同。


图17 蓝色与黄色车牌的不同
对于蓝色车牌而言,使用的参数为CV_THRESH_BINARY。
而对于黄色车牌而言,使用的参数为CV_THRESH_BINARY_INV。
假设黄色车牌使用了CV_THRESH_BINARY作为参数,则会发生如下图一样的二值化结果,其中字符部分变成了黑色,而背景则是白色(同理,蓝色车牌使用CV_THRESH_BINARY_INV也是一样的效果)。
在这种不正确的参数带来的二值化情况下,取轮廓操作将无法按照预期的行为进行处理。因此,必须使用正确的二值化参数。

图18 不正确参数的二值化效果
在颜色判断时,有一个小技巧,就是先把四周的“边”截取后再进行颜色的判断,这样可以消除车牌定位时一些多余的四周的干扰。
代码如下:
1 Mat tmpMat = input(Rect_<double>(w * 0.1, h * 0.1, w * 0.8, h * 0.8)); 2 3 // 判断车牌颜色以此确认threshold方法 4 Color plateType = getPlateType(tmpMat, true);
颜色判断方法的代码如下:
1 // getPlateType 2 //判断车牌的类型 3 Color getPlateType(const Mat& src, const bool adaptive_minsv) { 4 float max_percent = 0; 5 Color max_color = UNKNOWN; 6 7 float blue_percent = 0; 8 float yellow_percent = 0; 9 float white_percent = 0; 10 11 if (plateColorJudge(src, BLUE, adaptive_minsv, blue_percent) == true) { 12 // cout << "BLUE" << endl; 13 return BLUE; 14 } else if (plateColorJudge(src, YELLOW, adaptive_minsv, yellow_percent) == 15 true) { 16 // cout << "YELLOW" << endl; 17 return YELLOW; 18 } else if (plateColorJudge(src, WHITE, adaptive_minsv, white_percent) == 19 true) { 20 // cout << "WHITE" << endl; 21 return WHITE; 22 } else { 23 // cout << "OTHER" << endl; 24 25 // 如果任意一者都不大于阈值,则取值最大者 26 max_percent = blue_percent > yellow_percent ? blue_percent : yellow_percent; 27 max_color = blue_percent > yellow_percent ? BLUE : YELLOW; 28 29 max_color = max_percent > white_percent ? max_color : WHITE; 30 return max_color; 31 } 32 }
2.排除缝隙
在获得中文字符图块以后,下面一步就是把剩下的图块获取了。不过由于中文车牌一般只有7个字符,所以可以把后面的图块从左到右排序,依次选择6个即可。一些会被误判为“I”的缝隙可以通过这种方法排除出去。
例如下图中,最右边的一个缝隙会被误识别为"1"。但是倘若从左到右依次选择的话,这个缝隙并不会被选入候选集合中,因为它已经是“第八个”字符了。

图19 最右边会被误判为"1"的缝隙
排序与依次选择的代码如下:
1 //! 这个函数做两个事情 2 // 1.把特殊字符Rect左边的全部Rect去掉,后面再重建中文字符的位置。 3 // 2.从特殊字符Rect开始,依次选择6个Rect,多余的舍去。 4 int CCharsSegment::RebuildRect(const vector<Rect>& vecRect, 5 vector<Rect>& outRect, int specIndex) { 6 int count = 6; 7 for (size_t i = specIndex; i < vecRect.size() && count; ++i, --count) { 8 outRect.push_back(vecRect[i]); 9 } 10 11 return 0; 12 }
3.去除柳钉
有些中国的车牌中有一个非常妨碍识别的东西,那就是柳钉。倘若对一副含有柳钉的图进行二值化,极有可能会出现下图的结果。一些字符图块(下图的"9"和"1")通过柳钉的原因联系到了一体,那样的话就无法通过取轮廓操作来分割了。

图20 柳钉的影响
因此在二值化之后,还需要一个去除柳钉的操作。
去除柳钉的思想也并不复杂,就是依次扫描每行,判断跳变次数。车牌字符所在的行的跳变次数是很多的,而柳钉所在的行就会偏少。因此当发现某行跳变次数较少,则可以把该行的所有像素值赋值为0,这样就会大幅度消除柳钉的影响了。
下图就是去除柳钉后的效果。

图21 去除柳钉后的效果
去除柳钉函数的代码如下:
1 //去除车牌上方的钮钉 2 //计算每行元素的阶跃数,如果小于X认为是柳丁,将此行全部填0(涂黑) 3 // X的推荐值为,可根据实际调整 4 bool clearLiuDing(Mat& img) { 5 vector<float> fJump; 6 int whiteCount = 0; 7 const int x = 7; 8 Mat jump = Mat::zeros(1, img.rows, CV_32F); 9 for (int i = 0; i < img.rows; i++) { 10 int jumpCount = 0; 11 12 for (int j = 0; j < img.cols - 1; j++) { 13 if (img.at<char>(i, j) != img.at<char>(i, j + 1)) jumpCount++; 14 15 if (img.at<uchar>(i, j) == 255) { 16 whiteCount++; 17 } 18 } 19 20 jump.at<float>(i) = (float)jumpCount; 21 } 22 23 int iCount = 0; 24 for (int i = 0; i < img.rows; i++) { 25 fJump.push_back(jump.at<float>(i)); 26 if (jump.at<float>(i) >= 16 && jump.at<float>(i) <= 45) { 27 //车牌字符满足一定跳变条件 28 iCount++; 29 } 30 } 31 32 ////这样的不是车牌 33 if (iCount * 1.0 / img.rows <= 0.40) { 34 //满足条件的跳变的行数也要在一定的阈值内 35 return false; 36 } 37 //不满足车牌的条件 38 if (whiteCount * 1.0 / (img.rows * img.cols) < 0.15 || 39 whiteCount * 1.0 / (img.rows * img.cols) > 0.50) { 40 return false; 41 } 42 43 for (int i = 0; i < img.rows; i++) { 44 if (jump.at<float>(i) <= x) { 45 for (int j = 0; j < img.cols; j++) { 46 img.at<char>(i, j) = 0; 47 } 48 } 49 } 50 return true; 51 }
五.总结
最后回顾一下整体的处理流程,首先是对车牌图像进行灰度化,然后根据车牌的不同颜色来进行不同的二值化处理。二值化完后首先去除柳钉,然后进行取轮廓操作。
取轮廓操作以后,在所有的轮廓中根据先验知识,找到代表城市的字符,也就是“苏A”中“A”的位置,根据“A”的位置来反推“苏”的位置。
最后将找到的这些轮廓依次排序,从左到右依次选择6个,和第一个的中文字符组成7个字符的图块数组,输入到下一步字符识别模块中进行处理。
整个字符分割流程就到此结束了,还是比较简单的。其中的中文字符位置的确定使用了“先验知识”这种方法。这种方法在面对固定已知场景中是较好的方法,但是面对特殊情况时就可能会有不太好的效果,因此要根据具体情况来权衡。
六.未来展望
本篇字符分割流程就到此结束。当下,EasyPR1.3 版也发布了,对整体架构以及处理效率都有所提升,可以下载试用。
未来的博客会按照每2个月一篇的速度诞生,下篇博客的内容是”字符识别与人工神经网络”。
版权说明:
本文中的所有文字,图片,代码的版权都是属于作者和博客园共同所有。欢迎转载,但是务必注明作者与出处。任何未经允许的剽窃以及爬虫抓取都属于侵权,作者和博客园保留所有权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号