算法金 | DL 骚操作扫盲,神经网络设计与选择、参数初始化与优化、学习率调整与正则化、Loss Function、Bad Gradient

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
今日 216/10000
- 神经网络设计与选择
- 参数初始化与优化
- 学习率调整与正则化
- 数据预处理与标准化
- 训练过程与监控
- 特定模型技巧
- 其他训练技巧
1. 神经网络设计与选择
网络结构选择 多层感知器(MLP)是最基本的神经网络结构,由输入层、若干隐藏层和输出层组成。每一层的神经元与前一层的神经元全连接。这种结构适用于各种一般性任务,但对于图像和序列数据效果较差
循环神经网络(RNN)适用于处理序列数据,如时间序列和自然语言处理。RNN的特点是拥有记忆能力,通过隐状态(hidden state)传递信息,使其能够捕捉序列中的时序关系。然而,传统的RNN存在梯度消失和梯度爆炸问题,需要通过长短期记忆(LSTM)和门控循环单元(GRU)来改进
卷积神经网络(CNN)专为处理图像数据设计,通过卷积层、池化层和全连接层的组合,能够自动提取图像的空间特征。卷积层利用卷积核对输入图像进行局部感知,池化层则减少特征图的尺寸和参数数量,提高计算效率。CNN在计算机视觉任务中表现出色,如图像分类、目标检测和图像分割
激活函数选择 Sigmoid和Tanh是传统的激活函数,适用于简单的网络结构。Sigmoid将输入映射到0到1之间,Tanh则将输入映射到-1到1之间。这些激活函数在反向传播过程中容易导致梯度消失,影响网络训练效果
ReLU(修正线性单元)及其变种(如Leaky ReLU、Parametric ReLU)解决了梯度消失问题,提高了训练速度和效果。ReLU将输入大于零的部分直接输出,小于零的部分输出为零。Leaky ReLU在小于零部分引入一个较小的斜率,避免神经元完全失活
隐藏层设计 网络深度和隐藏层神经元数量是设计神经网络的重要因素。增加网络深度可以提高模型的表达能力,但同时也增加了训练难度和过拟合风险。选择合适的深度需要结合具体任务和数据情况
隐藏层中神经元的数量同样需要慎重选择。过少的神经元可能导致模型欠拟合,而过多的神经元则可能导致过拟合。通常可以通过交叉验证等方法来确定最佳的神经元数量
2. 参数初始化与优化
参数初始化
权重初始化方法对神经网络的训练效果有着重要影响。常见的权重初始化方法包括Xavier初始化和He初始化。Xavier初始化将权重设置为服从均值为0、方差为 2/(a_in+b_out) 的正态分布,其中 a_in 和 b_out 分别是输入和输出层的神经元数量。这种方法适用于Sigmoid和Tanh激活函数。He初始化则将权重设置为服从均值为0、方差为 2/a_in 的正态分布,适用于ReLU及其变种激活函数
Bias初始化方法通常将偏置(Bias)初始化为零。这样做的原因是,在训练开始时,所有的神经元有相同的激活输入,且不会因偏置不同而产生差异
优化算法 Mini-batch SGD(随机梯度下降)是常用的优化算法,通过每次更新一小部分样本的梯度来加速训练并减少内存使用。相比于全量数据的梯度下降,Mini-batch SGD在训练大数据集时更为高效
对于大数据集,Adam(自适应矩估计)优化算法是一种常用选择。Adam结合了动量和RMSProp的优点,能够自适应地调整学习率,提高训练稳定性和速度。对小数据集,RMSProp和AdaGrad也常被使用,因其能够根据梯度的历史信息调整每个参数的学习率
自适应学习率方法 Adagrad是一种自适应学习率方法,通过对每个参数的梯度平方和进行累加,调整每个参数的学习率。Adagrad适用于稀疏特征数据,但在后期学习率可能变得过小
其他自适应方法如RMSProp和Adam改进了Adagrad。RMSProp通过引入衰减系数,限制了累积的梯度平方和,避免学习率过小的问题。Adam则结合了动量和RMSProp的优点,计算每个参数的动量和二阶矩估计,自适应调整学习率,提高了训练的稳定性和速度
参数初始化和优化是神经网络训练中的关键步骤,合理的初始化和优化算法选择能够显著提升模型性能和训练效率。
点击 ↑ 领取
3. 学习率调整与正则化
学习率调整 固定学习率是最简单的学习率设置方式,在整个训练过程中保持不变。然而,固定学习率可能导致训练过程不稳定,难以找到最优解
动态学习率方法则通过在训练过程中调整学习率,提高训练效果。常见的动态学习率方法包括学习率衰减和自适应学习率。学习率衰减方法中,常见的有指数衰减和分段常数衰减,通过逐步减小学习率,避免训练后期的震荡现象。自适应学习率方法如Adam和RMSProp,通过自适应调整每个参数的学习率,进一步提高训练的稳定性和效率
正则化方法 减小模型大小是最直接的正则化方法之一,通过减少模型参数数量,降低过拟合风险。选择合适的网络结构和隐藏层神经元数量可以有效控制模型复杂度
L1/L2正则化是常用的正则化方法,通过在损失函数中加入参数的L1或L2范数,限制参数的大小,从而减少模型的复杂度。L1正则化倾向于产生稀疏参数,有助于特征选择;L2正则化则倾向于均匀缩小参数,防止过拟合
Early Stopping是一种简单有效的正则化方法,通过在验证误差不再下降时提前停止训练,避免模型在训练集上过拟合。设置适当的早停条件和验证集,可以显著提升模型的泛化能力
Dropout是另一种常用的正则化方法,通过在训练过程中随机丢弃一定比例的神经元,减少神经元间的共适应性,增强模型的鲁棒性。训练时丢弃神经元,预测时使用所有神经元的缩放输出,能够有效防止过拟合
通过合理的学习率调整和正则化方法,可以显著提高神经网络的训练效果和泛化能力。
4. 数据预处理与标准化
数据预处理 确保数据的一致性和连续性是数据预处理的关键步骤之一。对于缺失数据,可以使用插值法或填补法进行处理。对于分类数据,可以使用独热编码(One-Hot Encoding)将其转换为数值形式。数据的一致性还包括处理异常值、平滑数据和消除重复数据等
数据归一化和标准化也是预处理的重要步骤。归一化(Normalization)通常将数据缩放到[0,1]范围内,常用的公式为:
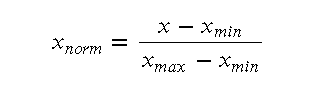
标准化(Standardization)则将数据调整为均值为0、方差为1的分布,公式为:

标准化(Normalization) 输入/输出标准化是提高神经网络训练效果的关键步骤。对于输入数据,通过标准化可以使不同特征的数据在同一尺度上,避免某些特征对训练过程的过度影响。输出数据的标准化则有助于模型更好地拟合目标值,特别是在回归任务中
常见的标准化方法包括Z-score标准化和Min-Max归一化。Z-score标准化通过调整数据的均值和方差,使其符合标准正态分布。Min-Max归一化则将数据缩放到指定的范围内,通常为[0,1]或[-1,1]
数据预处理和标准化能够显著提高模型的训练效率和效果,是神经网络训练中的重要步骤。
抱个拳,送个礼
点击 ↑ 领取
5. 训练过程与监控
梯度检查(Gradient Check) 梯度检查是一种确保反向传播算法正确性的重要方法。通过数值梯度和解析梯度的对比,可以验证反向传播实现是否正确。具体步骤如下:
- 对于参数 𝜃 ,计算数值梯度:
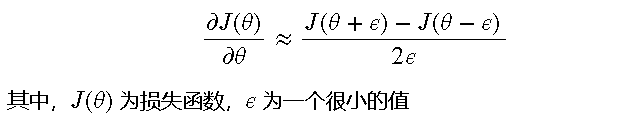
- 计算解析梯度,即反向传播得到的梯度
- 对比数值梯度和解析梯度,如果两者相差较小,则反向传播实现正确
可视化和简化任务 可视化是监控训练过程的有效方法。通过绘制损失函数和准确率随训练过程的变化图,可以直观地观察模型的收敛情况和训练效果。例如,可以使用 Matplotlib 绘制训练损失和验证损失随迭代次数的变化图:
import matplotlib.pyplot as plt
# 假设 loss_values 和 val_loss_values 分别存储训练损失和验证损失
plt.plot(epochs, loss_values, label='Training Loss')
plt.plot(epochs, val_loss_values, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
从简单任务开始逐步增加复杂度,是训练神经网络的有效策略。可以先在小规模数据集或简单任务上进行训练,确保模型能够正常工作,然后逐步增加数据集规模和任务复杂度,提高模型的泛化能力
结果检查(Results Check) 训练和预测过程中,定期监控结果是确保模型效果的重要步骤。可以通过交叉验证、混淆矩阵、准确率、精确率、召回率等指标来评估模型性能。例如,绘制混淆矩阵可以帮助直观地观察分类模型的效果:
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 假设 y_true 和 y_pred 分别存储真实标签和预测标签
cm = confusion_matrix(y_true, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
过拟合检查 过拟合是神经网络训练中的常见问题,通过对比训练误差和验证误差,可以检查模型是否过拟合。如果训练误差很低而验证误差较高,说明模型可能过拟合。此时,可以尝试增加正则化、使用 Dropout、减少模型复杂度或增加训练数据来缓解过拟合
通过有效的训练过程监控,可以及时发现和解决训练中的问题,确保模型的有效性和泛化能力。
6. 特定模型技巧
CNN的使用 卷积神经网络(CNN)在图像处理和计算机视觉任务中表现出色,其主要优势在于能够自动提取图像特征。CNN的卷积层通过卷积核扫描输入图像,捕捉局部特征,池化层则通过降采样减少数据量和参数数量,提高计算效率
具体使用技巧:
- 使用多层卷积层和池化层的组合,逐步提取图像的高级特征
- 在卷积层后添加批归一化(Batch Normalization),加速训练过程并稳定收敛
- 使用较小的卷积核(如 3×33×3),提高特征提取的精度
- 在模型末端添加全连接层,用于分类或回归任务
RNN的使用 循环神经网络(RNN)擅长处理序列数据,其主要特点是具有记忆能力,可以捕捉序列中的时序关系。RNN的隐状态(Hidden State)在每个时间步传递信息,使其能够处理时间序列和自然语言处理任务
具体使用技巧:
- 对于长序列数据,使用LSTM或GRU替代传统RNN,解决梯度消失和梯度爆炸问题
- 使用双向RNN(Bidirectional RNN)捕捉序列的前向和后向信息,提高模型效果
- 对于序列生成任务,可以使用编码器-解码器(Encoder-Decoder)结构,提升生成效果
AE降维 自编码器(Autoencoder, AE)是一种无监督学习模型,用于数据降维和特征学习。AE通过一个瓶颈层(隐藏层)将输入数据压缩到低维空间,再通过解码器重构原始输入
具体使用技巧:
- 使用L1正则化控制隐含节点的稀疏程度,提高特征选择能力
- 在编码器和解码器中使用非线性激活函数,增强模型的表达能力
- 在训练过程中加入噪声,提高模型的鲁棒性和泛化能力
点击 ↑ 领取
7. 其他训练技巧
Batch Size Batch Size对模型训练的影响显著。较小的Batch Size可以使模型更频繁地更新参数,提高收敛速度,但会增加训练的不稳定性。较大的Batch Size则能减少噪声,使模型更稳定,但训练时间较长
Loss Function 根据任务类型选择合适的损失函数是关键。对于回归任务,常用的损失函数是均方误差(MSE);对于分类任务,交叉熵损失(Cross-Entropy Loss)是常见选择。选择合适的损失函数能够更好地指导模型学习,提高性能
最后一层的激活函数 根据任务类型选择合适的激活函数对于模型性能至关重要。对于回归任务,通常不使用激活函数;对于二分类任务,常用Sigmoid函数;对于多分类任务,Softmax函数是常见选择
Bad Gradient(Dead Neurons) ReLU激活函数存在一个问题,即当输入为负时输出为零,导致神经元可能永远不会被激活,这被称为Dead Neurons。解决方案包括:
- 使用Leaky ReLU,使得输入为负时仍有少量输出
- 使用Parametric ReLU(PReLU),允许学习负斜率参数
- 使用Randomized ReLU(RReLU),在训练时随机选择负斜率
具体建议
- 使用1x1卷积提高网络表达能力,通过减少参数数量和计算量,提升模型效率
- 使用批归一化(Batch Normalization,BN)减少Internal Covariance Shift问题,稳定训练过程
- 使用shortcut结构(如ResNet中的跳跃连接)增加网络深度,提高模型性能和训练效果
[ 抱个拳,总个结 ]
- 神经网络设计与选择:选择合适的网络结构和激活函数,并合理设计隐藏层。
- 参数初始化与优化:采用有效的参数初始化方法和优化算法,如Mini-batch SGD和Adam。
- 学习率调整与正则化:动态调整学习率,采用正则化方法如L1/L2正则化和Dropout。
- 数据预处理与标准化:确保数据一致性和连续性,进行归一化和标准化处理。
- 训练过程与监控:进行梯度检查和可视化监控,及时发现并解决训练问题。
- 特定模型技巧:掌握CNN、RNN和AE的使用技巧,提高模型性能。
- 其他训练技巧:优化Batch Size,选择合适的损失函数和激活函数,解决Bad Gradient问题,使用1x1卷积和BN等提升模型效果。
通过综合应用这些技巧,可以显著提升神经网络的训练效果和模型性能,使其在各种任务中表现出色。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
日更 215 天
公众号读者破 20000 了
靠的是各位大侠的给力支持,抱拳了
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号