算法金 | 致敬深度学习三巨头:不愧是腾讯,LeNet问的巨细。。。

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
读者参加面试,竟然在 LeNet 这个基础算法上被吊打~
LeNet 确实经典,值得好好说道说道
更多内容,见微*公号往期文章:有史以来最详细的卷积神经网络(CNN)及其变体讲解!!!(多图)
1. LeNet 的背景和发展
LeNet 是由 Yann LeCun 等人在 1989 年提出的一种卷积神经网络(CNN)结构,用于手写数字识别。LeNet 引入了许多在现代深度学习中广泛使用的概念和技术,是计算机视觉领域的重要里程碑之一。通过模拟人脑视觉皮层的工作方式,LeNet 成功提升了机器处理图像数据的能力,奠定了深度学习在图像识别任务中的基础。

深度学习三巨头
2. LeNet 的基本结构
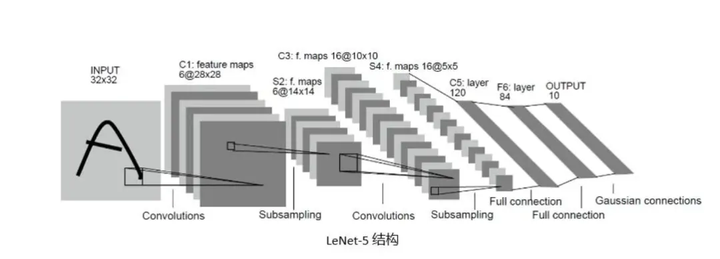
整体架构 LeNet 的整体架构包括多个卷积层和池化层,最后通过全连接层输出结果。它的典型结构如下:
- 输入层:接受 32x32 像素的灰度图像
- 卷积层 C1:6 个 5x5 的卷积核,输出 6 个 28x28 的特征图
- 池化层 S2:2x2 的平均池化,输出 6 个 14x14 的特征图
- 卷积层 C3:16 个 5x5 的卷积核,输出 16 个 10x10 的特征图
- 池化层 S4:2x2 的平均池化,输出 16 个 5x5 的特征图
- 卷积层 C5:120 个 5x5 的卷积核,输出 120 个 1x1 的特征图
- 全连接层 F6:84 个神经元
- 输出层:10 个神经元,对应 10 个类别
各层功能
- 卷积层:通过卷积运算提取图像的局部特征,并生成特征图
- 池化层:通过下采样减小特征图的尺寸,减少计算量,并在一定程度上防止过拟合
- 全连接层:将特征图展平并进行分类,输出最终结果
这种层次化的结构设计使得 LeNet 能够有效地处理图像数据,并在手写数字识别任务中取得了优异的表现。
LeNet
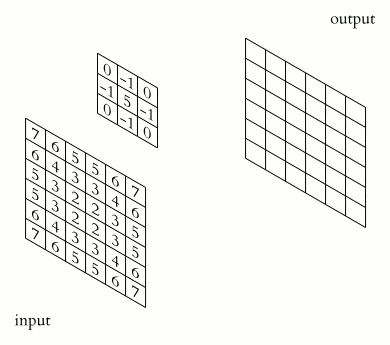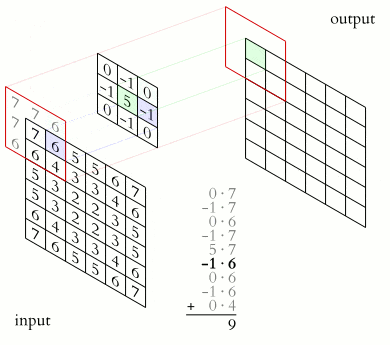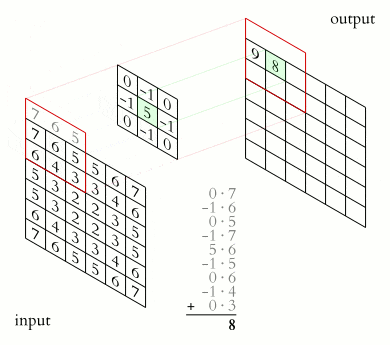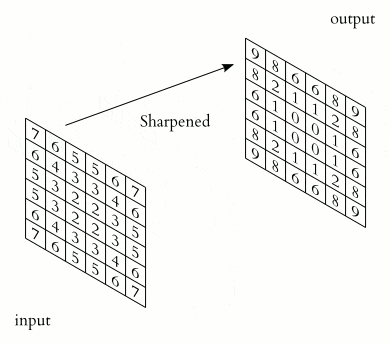
3. 卷积层
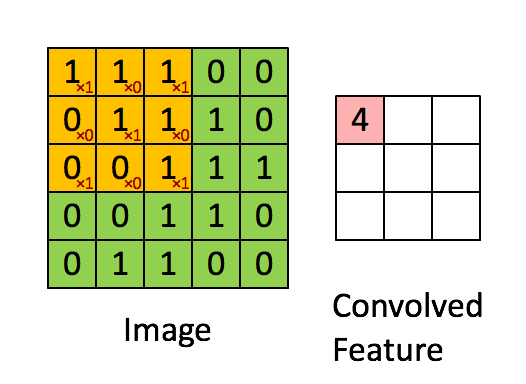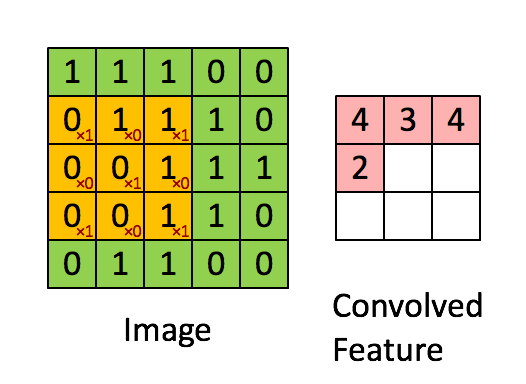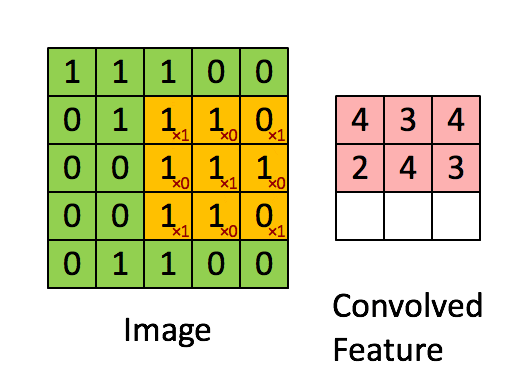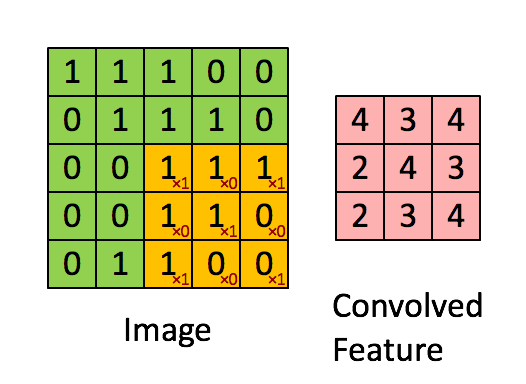
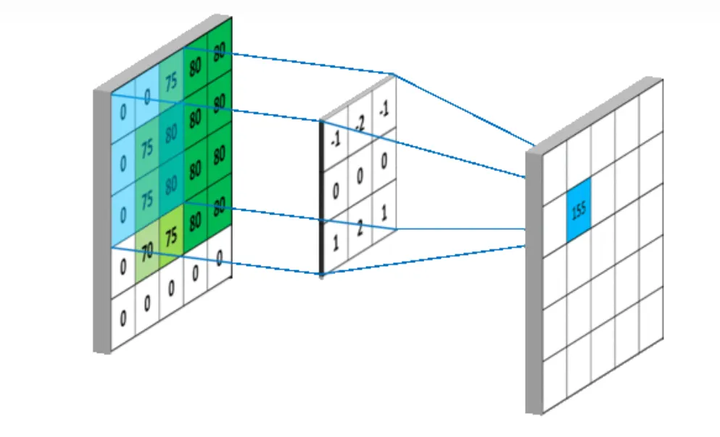
卷积层的作用 卷积层是 LeNet 中最核心的部分,其主要作用是通过卷积运算提取图像的局部特征。卷积运算可以看作是图像和卷积核(滤波器)之间的点积操作,这样可以检测出图像中的特定模式,如边缘、角点等。
卷积核 卷积核是一个小尺寸的权重矩阵,通常为 3x3 或 5x5。卷积核在图像上滑动(卷积),生成特征图。每个卷积核可以提取图像的一种特征。
卷积层的实现 在 LeNet 中,第一个卷积层(C1)使用 6 个 5x5 的卷积核,将输入图像转化为 6 个 28x28 的特征图。第二个卷积层(C3)使用 16 个 5x5 的卷积核,将池化后的特征图转化为 16 个 10x10 的特征图。最后一个卷积层(C5)使用 120 个 5x5 的卷积核,将特征图进一步压缩为 120 个 1x1 的特征图。
通过这些卷积层,LeNet 能够逐层提取图像的高级特征,为后续的分类任务奠定基础。
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
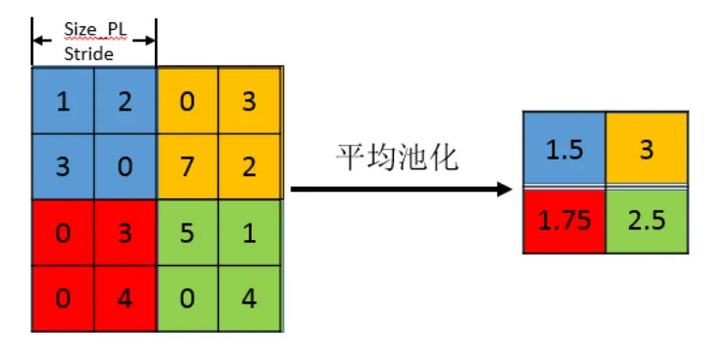
4. 池化层
池化层的作用 池化层(也称为下采样层或子采样层)的主要作用是通过降低特征图的分辨率来减少计算量,同时保留关键信息。池化层还能增强模型的鲁棒性,减少过拟合。
池化操作 池化操作可以有多种形式,常见的包括平均池化和最大池化。在 LeNet 中,使用的是平均池化。平均池化通过对特征图的局部区域(如 2x2)的像素值进行平均,从而生成下采样后的特征图。
池化层的实现 在 LeNet 中,池化层紧跟在每个卷积层之后:
- 池化层 S2:对卷积层 C1 的 6 个 28x28 特征图进行 2x2 的平均池化,生成 6 个 14x14 的特征图
- 池化层 S4:对卷积层 C3 的 16 个 10x10 特征图进行 2x2 的平均池化,生成 16 个 5x5 的特征图
通过池化层,LeNet 大幅减少了特征图的尺寸和计算量,同时保留了重要的特征信息,为后续的卷积和全连接层提供了更紧凑的特征表示。
5. 激活函数
激活函数的作用 激活函数引入非线性,使得神经网络可以表示更复杂的函数,从而增强模型的表达能力。如果没有激活函数,无论网络多么深,每一层的输出都只是输入的线性变换,最终网络的表达能力会受到限制。
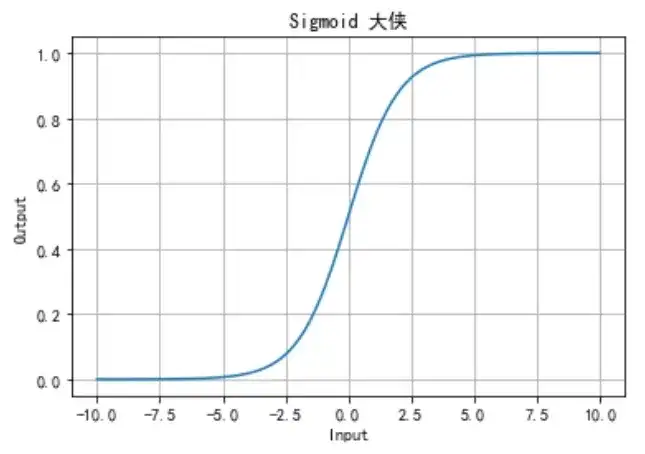
LeNet 中的激活函数 在 LeNet 中,使用的是 Sigmoid 激活函数。Sigmoid 函数将输入值映射到 (0, 1) 之间,使得输出具有概率解释。
Sigmoid 函数的定义如下:
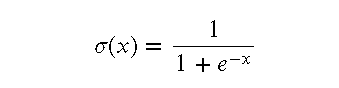
激活函数的计算 在每个卷积层和全连接层之后,都应用激活函数:
- 在卷积层 C1 和 C3 之后,使用 Sigmoid 激活函数,将卷积操作的结果映射到 (0, 1) 之间
- 在全连接层 F6 之后,使用 Sigmoid 激活函数,对输出进行非线性变换
激活函数的重要性 激活函数在神经网络中非常重要,它引入的非线性特性,使得网络能够学习和表达复杂的模式和特征。尽管现代神经网络中更常用 ReLU 激活函数,但在 LeNet 中,Sigmoid 激活函数同样起到了至关重要的作用。
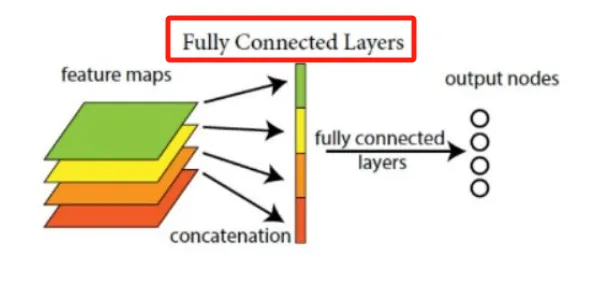
6. 全连接层
全连接层的作用 全连接层(Fully Connected Layer, FC)是神经网络中将前一层所有的输入连接到每个神经元的一层。这一层主要用于将卷积和池化层提取的特征进行综合,并输出分类结果。
LeNet 中的全连接层 在 LeNet 中,全连接层位于卷积层和池化层之后,承担着将高层次特征映射到输出类别的任务。具体包括以下两层:
- 全连接层 F6:这一层包含 84 个神经元。它接收来自上一层(C5 卷积层)的 120 个 1x1 特征图,将其展平为 120 个输入,并通过全连接操作输出 84 个特征。
- 输出层:这一层包含 10 个神经元,对应手写数字识别任务中的 10 个类别(数字 0-9)。通过 Softmax 函数,将每个输出神经元的值转换为概率,表示输入图像属于每个类别的可能性。
全连接层的重要性 全连接层通过综合卷积和池化层提取的特征,完成最终的分类任务。尽管卷积和池化层主要用于特征提取,但全连接层将这些特征转化为分类结果,是整个神经网络模型不可或缺的一部分。
在 LeNet 的设计中,全连接层不仅实现了高效的特征综合,还通过使用 Sigmoid 激活函数引入了非线性特性,使得模型能够更好地适应复杂的模式和特征。
点击 ↑ 领取
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
7. LeNet 的训练过程
训练数据 LeNet 的训练通常使用手写数字数据集,如 MNIST 数据集。该数据集包含 60,000 张训练图像和 10,000 张测试图像,每张图像是 28x28 像素的灰度图。
前向传播 在前向传播过程中,输入图像经过每一层的卷积、池化和激活函数运算,最终通过全连接层输出分类结果。前向传播的主要目标是计算每个样本的预测值。
损失函数 为了评估模型的预测性能,LeNet 使用交叉熵损失函数(Cross-Entropy Loss)来计算预测值与真实标签之间的差异。交叉熵损失函数的定义如下:
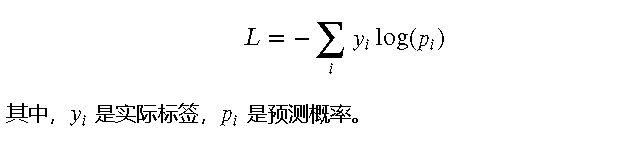
反向传播 反向传播(Backpropagation)是训练神经网络的关键步骤。在反向传播过程中,通过链式法则计算损失函数相对于每个参数的梯度,并使用梯度下降法(Gradient Descent)更新模型参数。梯度下降法的更新规则如下:
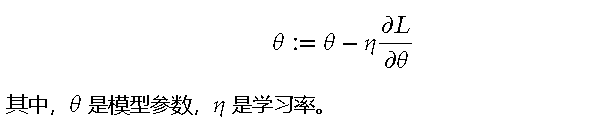
优化技术 为了加速训练过程和提高模型的性能,LeNet 使用了一些优化技术,如随机梯度下降(SGD),批量归一化(Batch Normalization)等。这些技术有助于提高模型的收敛速度和稳定性。
训练过程
- 初始化模型参数
- 输入训练数据,进行前向传播,计算预测值
- 计算损失函数
- 进行反向传播,计算梯度并更新参数
- 重复步骤 2-4,直到损失函数收敛或达到预设的训练轮次
通过上述训练过程,LeNet 能够从训练数据中学习到有效的特征表示,并在手写数字识别任务中取得优异的性能。
8. LeNet 的应用案例
手写数字识别 LeNet 最初被设计用于手写数字识别,特别是在 MNIST 数据集上。MNIST 数据集包含 0-9 的手写数字图像,LeNet 在该数据集上取得了超过 99% 的识别准确率。这个结果展示了卷积神经网络在图像处理任务中的强大能力。下面是一个详细的 LeNet 实现代码演示,涵盖整个过程,包括数据加载、模型定义、训练和评估
1. 输入:加载和预处理数据
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# 定义数据预处理
transform = transforms.Compose([
transforms.Resize((32, 32)), # 将图像调整为 32x32
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])
# 加载训练数据
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 加载测试数据
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=1000, shuffle=False)
# 展示部分输入数据
dataiter = iter(trainloader)
2. LeNet 的基本结构和各层实现
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # 输入通道为 1,输出通道为 6,卷积核大小为 5x5
self.pool = nn.AvgPool2d(kernel_size=2, stride=2) # 平均池化,窗口大小为 2x2,步幅为 2
self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 输入通道为 6,输出通道为 16,卷积核大小为 5x5
self.conv3 = nn.Conv2d(16, 120, kernel_size=5) # 输入通道为 16,输出通道为 120,卷积核大小为 5x5
self.fc1 = nn.Linear(120, 84) # 输入为 120,输出为 84
self.fc2 = nn.Linear(84, 10) # 输入为 84,输出为 10(对应 10 个类别)
def forward(self, x):
x = self.pool(F.sigmoid(self.conv1(x))) # 卷积 -> 激活 -> 池化
x = self.pool(F.sigmoid(self.conv2(x))) # 卷积 -> 激活 -> 池化
x = F.sigmoid(self.conv3(x)) # 卷积 -> 激活
x = x.view(-1, 120) # 展平为一维向量
x = F.sigmoid(self.fc1(x)) # 全连接层 -> 激活
x = self.fc2(x) # 全连接层
return x
# 实例化模型
net = LeNet()
3. 训练过程
import torch.optim as optim
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # 随机梯度下降优化器
# 训练模型
for epoch in range(10): # 训练 10 个 epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad() # 梯度清零
outputs = net(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化
running_loss += loss.item()
if i % 100 == 99: # 每 100 个 mini-batch 打印一次
print(f'[Epoch {epoch + 1}, Batch {i + 1}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
print('Finished Training')
[Epoch 1, Batch 100] loss: 2.313
[Epoch 1, Batch 200] loss: 2.311
[Epoch 1, Batch 300] loss: 2.309
[Epoch 1, Batch 400] loss: 2.308
...
[Epoch 10, Batch 400] loss: 0.304
[Epoch 10, Batch 500] loss: 0.268
[Epoch 10, Batch 600] loss: 0.286
[Epoch 10, Batch 700] loss: 0.281
[Epoch 10, Batch 800] loss: 0.257
[Epoch 10, Batch 900] loss: 0.269
Finished Training
4. 评估模型
correct = 0
total = 0
# 不计算梯度
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total:.2f}%')
Accuracy of the network on the 10000 test images: 92.75%
5. 结果展示
展示输入图像和预测结果
import matplotlib.pyplot as plt
import numpy as np
# 从测试集中获取一些图像
dataiter = iter(testloader)
images, labels = dataiter.next()
# 展示图像的函数
def imshow(img):
img = img / 2 + 0.5 # 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 打印图像
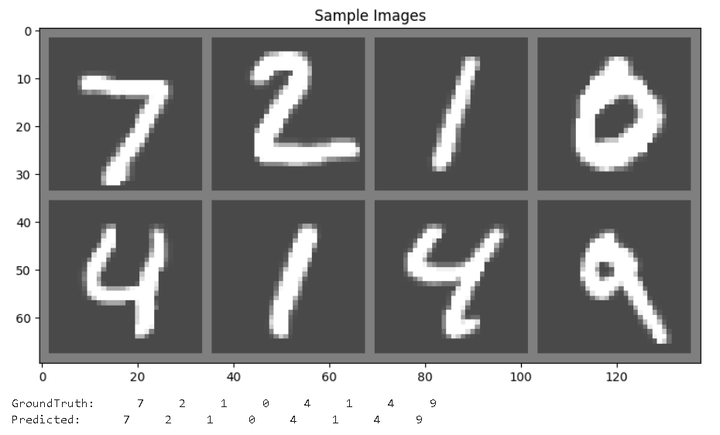
imshow(torchvision.utils.make_grid(images))
# 打印真实标签
print('GroundTruth: ', ' '.join('%5s' % labels[j].item() for j in range(8)))
# 打印预测标签
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % predicted[j].item() for j in range(8)))
展示中间层输出
我们可以通过提取中间层的输出,来直观地观察数据在各层的变化。
def visualize_layer(layer, data):
layer_output = layer(data)
layer_output = layer_output.detach().numpy()
fig, axes = plt.subplots(1, len(layer_output[0]), figsize=(12, 12))
for i, ax in enumerate(axes):
ax.imshow(layer_output[0][i], cmap='gray')
ax.axis('off')
plt.show()
# 展示卷积层 C1 的输出
dataiter = iter(testloader)
images, labels = dataiter.next()
visualize_layer(net.conv1, images)
# 展示卷积层 C2 的输出
pool1_output = net.pool(F.sigmoid(net.conv1(images)))
visualize_layer(net.conv2, pool1_output)
# 展示卷积层 C3 的输出
pool2_output = net.pool(F.sigmoid(net.conv2(pool1_output)))
visualize_layer(net.conv3, pool2_output)

点击 ↑ 领取
防失联,进免费知识星球,直达算法金 AI 实验室 https://t.zsxq.com/ckSu3
9. LeNet 的局限性
局限性 尽管 LeNet 在图像识别任务中表现出色,但它也存在一些局限性:
- 网络深度有限:LeNet 的层数较少,参数量相对较小,这限制了它对复杂任务的表现
- 激活函数的选择:LeNet 使用 Sigmoid 激活函数,容易导致梯度消失问题,特别是在深层网络中
- 池化操作:使用平均池化而非最大池化,可能会丢失一些重要的特征信息
- 计算资源限制:LeNet 设计于计算资源有限的年代,其架构未能充分利用现代 GPU 的计算能力
改进方向 针对这些局限性,研究者们提出了许多改进方案:
- 增加网络深度:通过增加卷积层和全连接层的数量,提升网络的特征提取能力
- 使用 ReLU 激活函数:相比于 Sigmoid,ReLU 减少了梯度消失问题,并加速了模型训练
- 引入最大池化:最大池化可以保留更多的重要特征信息,提高模型的识别能力
- 利用现代计算资源:设计更复杂的模型架构,充分利用现代 GPU 的计算能力,如 VGG、ResNet 等
这些改进方向不仅提高了 LeNet 的性能,还为后续深度学习模型的发展提供了宝贵的经验。
10. LeNet 的创新点
创新之处 LeNet 作为早期的卷积神经网络,具有以下几大创新点:
- 卷积操作:通过局部感受野和权重共享,有效减少了参数数量,提高了计算效率
- 层次结构:采用多层卷积和池化的层次结构,使得网络能够逐层提取图像的高层次特征
- 端到端训练:从输入图像到输出分类结果,整个过程可以通过反向传播进行端到端训练
- 引入池化层:通过池化操作降低特征图的分辨率,减少计算量,并在一定程度上防止过拟合
影响 LeNet 的这些创新对后续算法的发展产生了深远的影响:
- 卷积神经网络(CNN)的普及:LeNet 的成功验证了 CNN 在图像处理任务中的有效性,促使更多研究者投入到 CNN 的研究中
- 现代深度学习模型:许多现代深度学习模型,如 AlexNet、VGG、ResNet 等,都在 LeNet 的基础上进行了改进和扩展
- 应用领域的拓展:LeNet 的思想不仅应用于手写数字识别,还被广泛应用于图像分类、目标检测、图像分割等多个领域
这些创新和影响,使得 LeNet 成为深度学习发展史上的一个重要里程碑。
11. 实践中的 LeNet
操作和实现细节 在实践中,实现 LeNet 需要注意以下几点:
- 数据预处理:对输入图像进行标准化处理,确保数据分布的一致性,有助于模型的训练和收敛
- 模型初始化:使用合适的权重初始化方法,如 Xavier 初始化,可以加速模型训练
- 批量训练:通过小批量(mini-batch)训练,提高模型的训练效率和稳定性
- 学习率调整:根据训练过程中损失函数的变化,动态调整学习率,有助于模型更快地收敛
技巧和经验 在实际操作中,可以通过以下技巧提高 LeNet 的性能:
- 数据增强:通过数据增强技术(如随机裁剪、旋转、翻转等),增加训练数据的多样性,提高模型的泛化能力
- 正则化技术:使用 L2 正则化、Dropout 等技术,防止模型过拟合
- 提前停止:在训练过程中监控验证集的表现,当验证误差不再下降时提前停止训练,防止过拟合
通过这些实践操作和技巧,大侠们可以更好地实现和优化 LeNet 模型,从而在实际应用中取得更好的效果。
[ 抱个拳,总个结 ]
LeNet 是卷积神经网络(CNN)领域的开创性工作之一。其通过引入卷积层和池化层的层次结构,实现了有效的特征提取和分类任务。尽管 LeNet 的结构较为简单,但它的创新点和实践经验对后续深度学习模型的发展产生了深远影响。在实践中,通过数据预处理、模型初始化、批量训练和学习率调整等操作,以及数据增强、正则化技术和提前停止等技巧,可以有效提升 LeNet 的性能。LeNet 的局限性和改进方向也为我们提供了宝贵的研究和应用经验,为现代深度学习的发展奠定了坚实基础。
希望这篇文章能帮助大侠更好地理解和应用 LeNet,为进一步研究和探索深度学习技术提供参考。
更多内容,见微*公号往期文章:有史以来最详细的卷积神经网络(CNN)及其变体讲解!!!(多图)
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
最近给某 985 大学同学讲算法,专门挑经典的比较源头的讲
经典的往往比较久远,现在用得不多(用改进版)
但思想 [钻石恒久远,一颗永流传]这样的内容如果做成一个专门的专栏专门用于算法入门,你会需要吗?会为此付费吗?期待你的反馈

全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号