资深博导:我以为数据预处理是常识,直到遇到自己的学生

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
在光谱学领域,数据预处理是不可或缺的一环。
本文将基于 NIR soil 近红外光谱数据,运用 Python 语言进行数据处理,并通过图表直观反映预处理带来的变化。(数据集:后台回复 [ NIR soil ] 获取 )
常用的光谱数据预处理技术包括:
- MSC(多元散射校正)
- SNV(标准正规化变换)
- 光谱微分
- 基线校正
- 去趋势

一、MSC(多元散射校正)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# 读取数据
nirsoil_df = pd.read_csv(path)
# 提取光谱数据
spectra = nirsoil_df.filter(like='spc.')
# 进行MSC预处理
def msc(input_data):
# 计算参考光谱(均值光谱)
ref_spectrum = np.mean(input_data, axis=0)
# 初始化校正后的光谱数据矩阵
corrected_spectra = np.zeros_like(input_data)
for i in range(input_data.shape[0]):
fit = np.polyfit(ref_spectrum, input_data[i, :], 1, full=True)
corrected_spectra[i, :] = (input_data[i, :] - fit[0][1]) / fit[0][0]
return corrected_spectra
# 应用MSC
msc_spectra = msc(spectra.values)
# 可视化对比
plt.figure(figsize=(12, 6))
# 原始光谱
plt.subplot(1, 2, 1)
plt.plot(spectra.values.T, color='blue', alpha=0.1)
plt.title('Original Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
# MSC校正后的光谱
plt.subplot(1, 2, 2)
plt.plot(msc_spectra.T, color='red', alpha=0.1)
plt.title('MSC Corrected Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
plt.tight_layout()
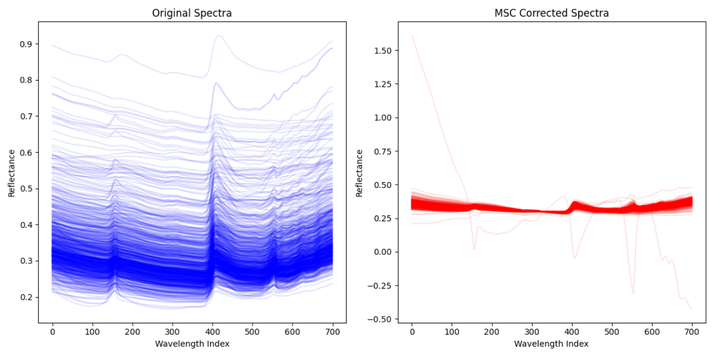
在输出的图片中,左侧显示的是原始光谱数据,右侧显示的是经过MSC(多元散射校正)处理后的光谱数据。
原始光谱(左侧图)
- 颜色和形状:每条蓝色的线代表一个样本的光谱数据,颜色浅且分布较散。
- 特点:可以观察到光谱数据在某些波长处的反射率(Reflectance)存在一定的波动,这可能是由于散射效应和基线漂移引起的。
MSC校正后的光谱(右侧图)
- 颜色和形状:每条红色的线代表一个样本的校正后的光谱数据,颜色浅且分布较集中。
- 特点:校正后的光谱数据在各个波长处的反射率(Reflectance)更加一致,减少了由散射效应和基线漂移引起的变化。整体曲线更加平滑,差异性减少。
总结
- 变化:经过MSC处理后,光谱数据在整体上变得更加一致和平滑,减少了不必要的噪音和变动,使得数据更适合后续的分析和建模。
- 意义:MSC处理通过消除光谱数据中的散射效应和基线漂移,提高了数据的质量,增强了不同样本之间的可比性。
防失联,进免费知识星球交流。算法知识直达星球:https://t.zsxq.com/ckSu3
更多内容,见免费知识星球
二、SNV(标准正规化变换)
# 提取光谱数据
spectra = nirsoil_df.filter(like='spc.')
# 进行SNV预处理
def snv(input_data):
# 每个样本减去其均值,然后除以其标准差
corrected_spectra = (input_data - np.mean(input_data, axis=1, keepdims=True)) / np.std(input_data, axis=1, keepdims=True)
return corrected_spectra
# 应用SNV
snv_spectra = snv(spectra.values)
# 可视化对比
plt.figure(figsize=(12, 6))
# 原始光谱
plt.subplot(1, 2, 1)
plt.plot(spectra.values.T, color='blue', alpha=0.1)
plt.title('Original Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
# SNV校正后的光谱
plt.subplot(1, 2, 2)
plt.plot(snv_spectra.T, color='green', alpha=0.1)
plt.title('SNV Corrected Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
plt.tight_layout()
plt.show()
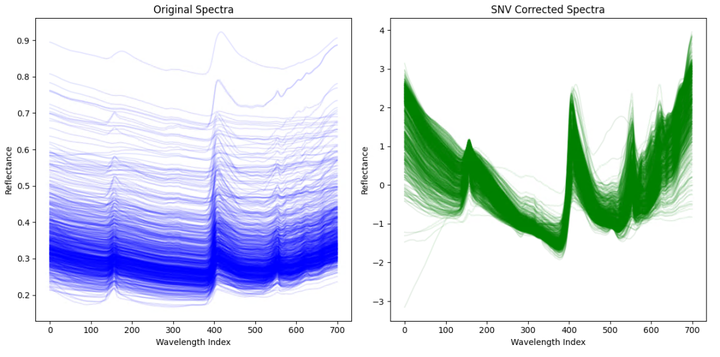
在输出的图片中,左侧显示的是原始光谱数据,右侧显示的是经过SNV(标准正规化变换)处理后的光谱数据。
原始光谱(左侧图)
- 颜色和形状:每条蓝色的线代表一个样本的光谱数据,颜色浅且分布较散。
- 特点:可以观察到光谱数据在某些波长处的反射率(Reflectance)存在一定的波动,这可能是由于样本间的差异和噪声引起的。
SNV校正后的光谱(右侧图)
- 颜色和形状:每条绿色的线代表一个样本的校正后的光谱数据,颜色浅且分布较集中。
- 特点:校正后的光谱数据在各个波长处的反射率(Reflectance)变得更加一致,样本间的差异和噪声显著减少。每条曲线的均值为零,标准差为一,使得所有光谱都在同一个尺度上。
总结
- 变化:经过SNV处理后,光谱数据的均值被中心化为零,标准差被标准化为一,减少了由于不同样本间的散射效应和噪声带来的影响。
- 意义:SNV处理通过对每个样本的光谱数据进行均值中心化和标准化,消除了样本间的散射效应,提高了数据的一致性和可比性,使得数据更适合后续的分析和建模。

三、光谱微分
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
# nirsoil_df = pd.read_csv('path_to_your_csv.csv')
# 提取光谱数据
spectra = nirsoil_df.filter(like='spc.')
# 进行光谱微分处理
def spectral_derivative(input_data, order=1):
if order == 1:
derivative_spectra = np.diff(input_data, n=1, axis=1)
elif order == 2:
derivative_spectra = np.diff(input_data, n=2, axis=1)
else:
raise ValueError("Only first and second order derivatives are supported.")
return derivative_spectra
# 一阶微分
first_derivative = spectral_derivative(spectra.values, order=1)
# 二阶微分
second_derivative = spectral_derivative(spectra.values, order=2)
# 可视化对比
plt.figure(figsize=(12, 6))
# 一阶和二阶微分
plt.plot(first_derivative[0, :], label='1st Derivative', color='black')
plt.plot(second_derivative[0, :], label='2nd Derivative', color='red')
plt.title('Spectral Derivatives')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
plt.legend()
plt.grid(True)
plt.show()
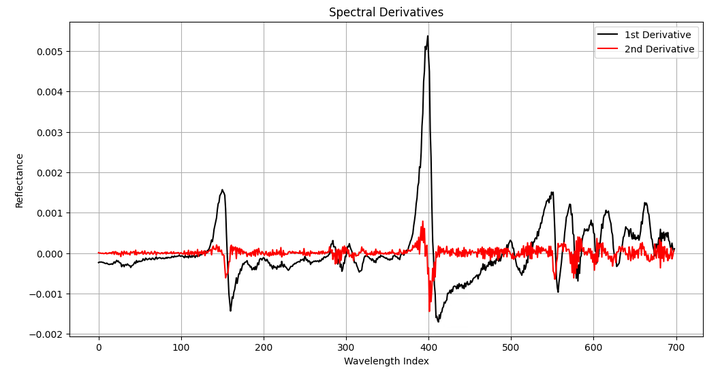
在输出的图片中,我们同时展示了一阶微分和二阶微分处理后的光谱数据。
一阶微分(黑色线)
- 特点:一阶微分曲线展示了光谱数据在各个波长处的变化率。它突出了光谱曲线的斜率变化,强调了光谱数据中快速变化的区域。
- 用途:一阶微分处理可以减少基线漂移的影响,并增强光谱中微弱的特征和变化。这对于区分类似的光谱样本非常有用。
二阶微分(红色线)
- 特点:二阶微分曲线展示了光谱数据的曲率变化率。它进一步强调了光谱曲线的局部最大值和最小值,突出了更细微的变化。
- 用途:二阶微分处理可以进一步减少基线漂移和噪声的影响,并提供更多关于光谱中细节特征的信息。这对于精细分析光谱数据中的细节特征非常有用。
总结
- 变化:一阶和二阶微分处理后,光谱数据的变化率和曲率变化率被突出展示,增强了光谱中细节特征的可见性,减少了基线漂移和噪声的影响。
- 意义:导数处理通过强调光谱数据的变化率和曲率变化率,提供了更清晰的特征和模式,有助于后续的分析和建模。
点击 ↑ 领取

四、基线校正
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.sparse import diags
from scipy.sparse.linalg import spsolve
# 读取数据
# nirsoil_df = pd.read_csv('path_to_your_csv.csv')
# 提取光谱数据
spectra = nirsoil_df.filter(like='spc.')
# 进行AsLS基线校正
def baseline_als(y, lam=1e5, p=0.01, niter=10):
L = len(y)
D = diags([1, -2, 1], [0, -1, -2], shape=(L, L-2))
D = lam * D.dot(D.T)
w = np.ones(L)
for i in range(niter):
W = diags(w, 0, shape=(L, L))
Z = W + D
z = spsolve(Z, w*y)
w = p * (y > z) + (1-p) * (y < z)
return z
def baseline_correction(input_data):
corrected_spectra = np.zeros_like(input_data)
for i in range(input_data.shape[0]):
baseline_values = baseline_als(input_data[i, :])
corrected_spectra[i, :] = input_data[i, :] - baseline_values
return corrected_spectra
# 应用基线校正
corrected_spectra = baseline_correction(spectra.values)
# 可视化对比
plt.figure(figsize=(12, 6))
# 原始光谱
plt.subplot(1, 2, 1)
plt.plot(spectra.values.T, color='blue', alpha=0.1)
plt.title('Original Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
# 基线校正后的光谱
plt.subplot(1, 2, 2)
plt.plot(corrected_spectra.T, color='green', alpha=0.1)
plt.title('Baseline Corrected Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
plt.tight_layout()
plt.show()
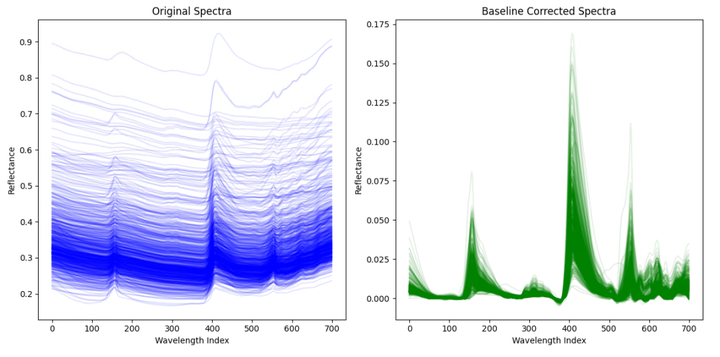
在输出的图片中,左侧显示的是原始光谱数据,右侧显示的是经过基线校正处理后的光谱数据。
原始光谱(左侧图)
- 颜色和形状:每条蓝色的线代表一个样本的光谱数据,颜色浅且分布较散。
- 特点:可以观察到光谱数据在各个波长处的反射率(Reflectance)存在一定的基线漂移和噪声,这可能是由测量误差和环境因素引起的。
基线校正后的光谱(右侧图)
- 颜色和形状:每条绿色的线代表一个样本的校正后的光谱数据,颜色浅且分布较集中。
- 特点:校正后的光谱数据在各个波长处的反射率(Reflectance)变得更加一致,基线漂移被去除,噪声显著减少。曲线的整体趋势更加平滑和稳定。
总结
- 变化:经过基线校正处理后,光谱数据的基线漂移被有效去除,减少了由测量误差和环境因素带来的影响,使得光谱数据更加清晰和稳定。
- 意义:基线校正处理通过去除光谱数据中的基线漂移,提高了数据的质量和一致性,便于后续的分析和建模。
防失联,进免费知识星球交流。算法知识直达星球:https://t.zsxq.com/ckSu3
免费知识星球,欢迎加入交流
五、去趋势
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import detrend
# # 读取数据
# nirsoil_df = pd.read_csv('path_to_your_csv.csv')
# 提取光谱数据
spectra = nirsoil_df.filter(like='spc.')
# 进行去趋势处理
def detrending(input_data):
detrended_spectra = detrend(input_data, axis=1)
return detrended_spectra
# 应用去趋势处理
detrended_spectra = detrending(spectra.values)
# 可视化对比
plt.figure(figsize=(12, 6))
# 原始光谱
plt.subplot(1, 2, 1)
plt.plot(spectra.values.T, color='blue', alpha=0.1)
plt.title('Original Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
# 去趋势后的光谱
plt.subplot(1, 2, 2)
plt.plot(detrended_spectra.T, color='brown', alpha=0.1)
plt.title('Detrended Spectra')
plt.xlabel('Wavelength Index')
plt.ylabel('Reflectance')
plt.tight_layout()
plt.show()
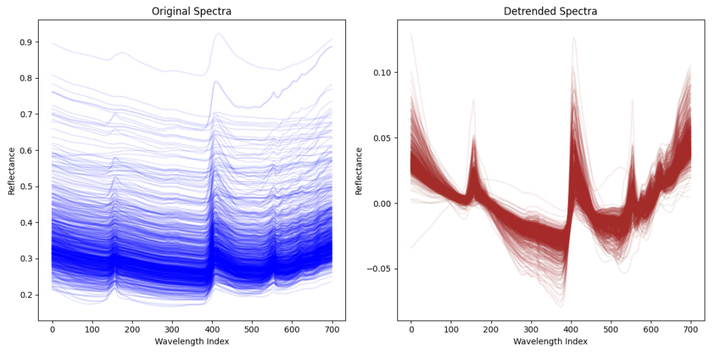
在输出的图片中,左侧显示的是原始光谱数据,右侧显示的是经过去趋势处理后的光谱数据。
原始光谱(左侧图)
- 颜色和形状:每条蓝色的线代表一个样本的光谱数据,颜色浅且分布较散。
- 特点:光谱数据在各个波长处的反射率(Reflectance)存在一定的趋势,这些趋势可能是由实验条件、测量误差等因素引起的。
去趋势后的光谱(右侧图)
- 颜色和形状:每条棕色的线代表一个样本的去趋势处理后的光谱数据,颜色浅且分布较集中。
- 特点:去趋势处理后,光谱数据中各个波长处的趋势被去除,数据更加平稳和一致,减少了由实验条件、测量误差等因素带来的系统性偏差。
总结
- 变化:经过去趋势处理后,光谱数据中的系统性趋势被去除,光谱曲线更加平稳和一致,减少了外部因素带来的系统性偏差。
- 意义:去趋势处理通过去除光谱数据中的系统性趋势,提高了数据的质量和一致性,使得光谱数据更适合后续的分析和建模。
更多内容,见微*公号往期文章: 审稿人:拜托,请把模型时间序列去趋势!!

[ 抱个拳,总个结 ]
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号