西瓜书第一章学习笔记
第一章
- 基本术语
- 分类:预测离散值
- 回归:预测连续值
- 聚类:将训练集中的内容分为一些簇,训练样本不拥有标记信息
- 有监督学习:如分类和回归
- 无监督学习:如聚类
- 泛化:使得模型可以适用于新样本的能力
- 假设空间
- 归纳:特殊到一般(泛化过程)
- 演绎:一般到特殊(特化过程)
- 版本空间:与训练集一致的“假设空间”
- 如何求解版本空间:
-
写出假设空间:先列出所有可能的样本点(即特征向量)(即每个属性都取到所有的属性值)
-
对应着给出的已知数据集,将与正样本不一致的、与负样本一致的假设删除。
-
归纳偏好
- 归纳偏好:在学习过程中对某种类型假设的偏好,如图,假设训练样本是图中的各个(x,y),模型学习的目标就是找到一条穿过所有
训练样本的曲线。因为训练集有限,得到的曲线会有很多种。当学习的偏好是“相似样本应有相似输出”时,学习出来的曲线应该是曲线A。

- 奥卡姆剃刀:若多个假设与观察一致,选择最简单的那个。

其中,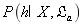 表示算法ξα基于训练数据X产生假设h的概率,
表示算法ξα基于训练数据X产生假设h的概率,
f为我们希望学习的真实目标函数。Eote表示在训练集之外的所有样本上的误差。Ⅱ(·)为指示函数,()中的波尔函数值为true即为1,否则为0。
函数的理解:在样本空间中训练集之外的误差=样本x的概率0或1算法基于训练数据X产生假设h的概率,当假设不符合真实目标函数时取1.
对于任意两个算法,都有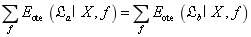 ,即算法的期望性能相同。(前提:所有问题出现机会相同或所有问题同等重要)
,即算法的期望性能相同。(前提:所有问题出现机会相同或所有问题同等重要)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号