
Q-learning算法及其在囚徒困境问题中的实现
一、强化学习
- 强化学习是一种无教师学习。
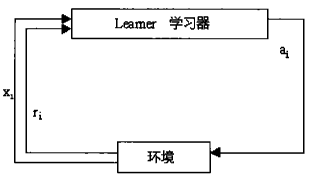
理解:系统有学习器和环境两个模块,分时进行学习,在t=i时,向学习器输入xi,选择动作ai可以获得一个ri。此时系统所要选择的是当输入xi时使得ri
最大的动作ai。选择xi的行为便称为策略。 - Q-learning算法的优点:不需要对所处的动态环境建模,所以耗费时间少,能在Agent与环境交互时在线使用。
运行机制:
- TFT算法:即针锋相对算法,其基本策略就是以对手上一步的行动为当前行动。
二、实验设计
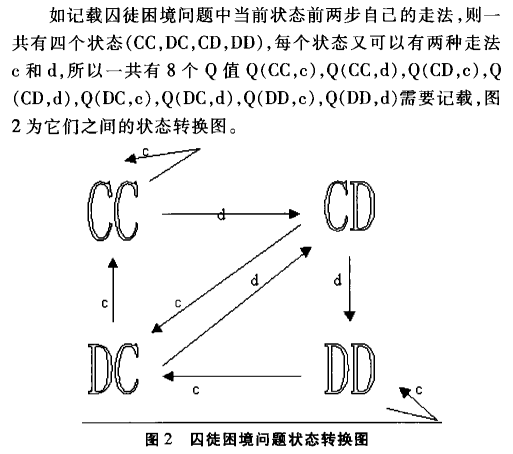


理解:共四种状态,每种状态有两种可以选择的动作,所以共8种Q值。
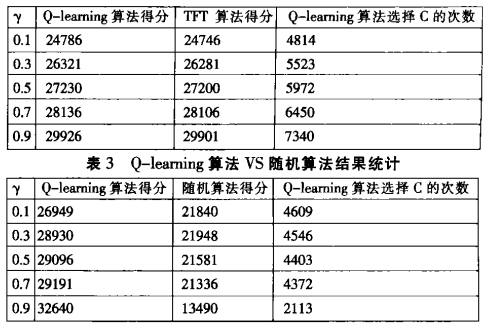
三、 实验结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号