Q -learning入门
算法思想
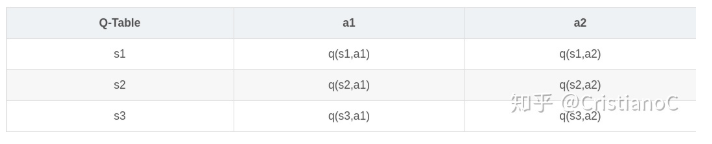
Q-Learning是强化学习算法中value-based的算法,Q即为Q(s,a),就是在某一个时刻的state状态下,采取动作a能够获得收益的期望,环境会根据agent的动作反馈相应的reward奖赏,
所以算法的主要思想就是将state和action构建成一张Q_table表来存储Q值,然后根据Q值来选取能够获得最大收益的动作。
Q-learning的主要优势就是使用了时间差分法(融合了蒙特卡洛和动态规划)能够进行off-policy的学习,使用贝尔曼方程可以对马尔科夫过程求解最优策略。
算法公式

参数介绍:
- Epsilon greedy:是用在决策上的一个策略,比如epsilon = 0.9的时候,就说明百分之90的情况我会按照Q表的最优值选择行为,百分之10的时间随机选择行为。
- alpha:学习率,决定这次的误差有多少是要被学习的。
- gamma:对未来reward的衰减值。gamma越接近1,机器对未来的reward越敏感

 浙公网安备 33010602011771号
浙公网安备 33010602011771号