一、说在前面
老师给找的课好久了一直没看,今天开始!
二、笔记
一、数据的特性
广泛性
多样性
结构化数据
关系数据
非结构化数据80%以上
网页
文本
图像
视频
语音
二、数据科学的内涵
1.用数据的方法研究科学
生物信息学、天体信息学、地球科学等
例:
开普勒三大定律
2.用科学的方法研究数据
统计学、机器学习、数据挖掘、数据库
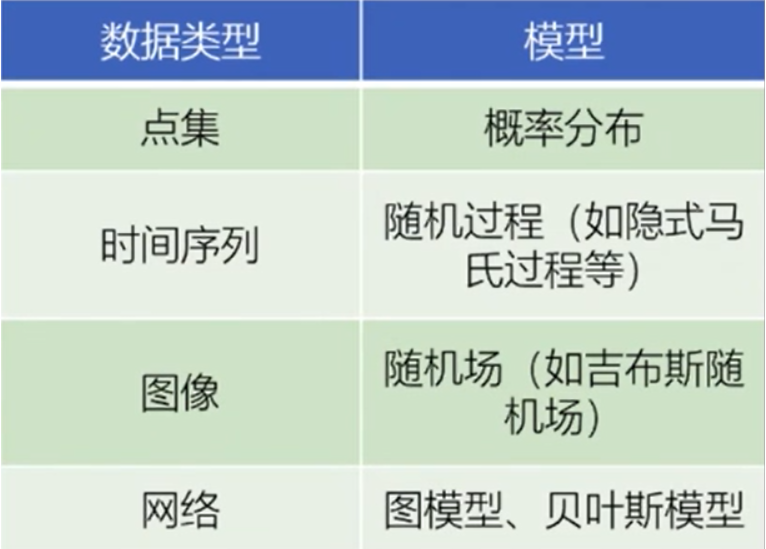
常见的数据类型
表格:最经典的数据
点集:很多数据都可以看成是某种空间的点的集合
时间序列:文本、通话和DNA序列等都可以看成是时间序列
图像视频:可以看成两个变量的函数
网页和报纸:每篇文章都可以看成是时间序列,整个网页和报纸又具有空间结构
网络数据:网络数据本质上是图,由节点和联系节点的边构成
注:数据分析的基本假设:观察到的数据都是由背后的一个模型产生
数据分析的主要困难
数据量大
维数高(核心困难):模型复杂度和计算量随着维数的增加和指数增长
如何克服:
将模型限制在一个技校的特殊类里面 如线性模型
利用数据可能有的特殊结构(例如稀疏性 低维或低秩 光滑性等)通过正则化和降维来实现。
类型复杂:表格、图像、文本、视频
噪音大:数据在生成、采集、传输和处理等流程均可能引入噪音
算法的重要性
与模型相辅相成并在计算机上实现
从算法角度看,处理大数据有两条思路
降低算法的复杂度:
如梯度下降
分布式计算:
把大问题分解成小问题,然后分而治之,如MapReduce框架
机器学习
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
机器学习是对能通过经验自动改进的计算机算法的研究。
机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号