机器学习--维度灾难
一、说在前面
今天的学习内容是机器学习中的维度灾难,它就像编程中的空指针异常一样非常的让人头疼但又经常如影随形。学习的过程中让我感受颇深的一句话是,如无必要,勿增实体。如果简单的东西可以达到复杂东西的效果,那还用复杂的干嘛呢,也提醒我们在编码的时候要尽可能的精简,不要那么多无用的冗余。
二、笔记
维度灾难 1、什么是维度灾难 随着维度(例如特征或自由度)的增多,问题的复杂性(或计算算代价)呈指数级增长的现象
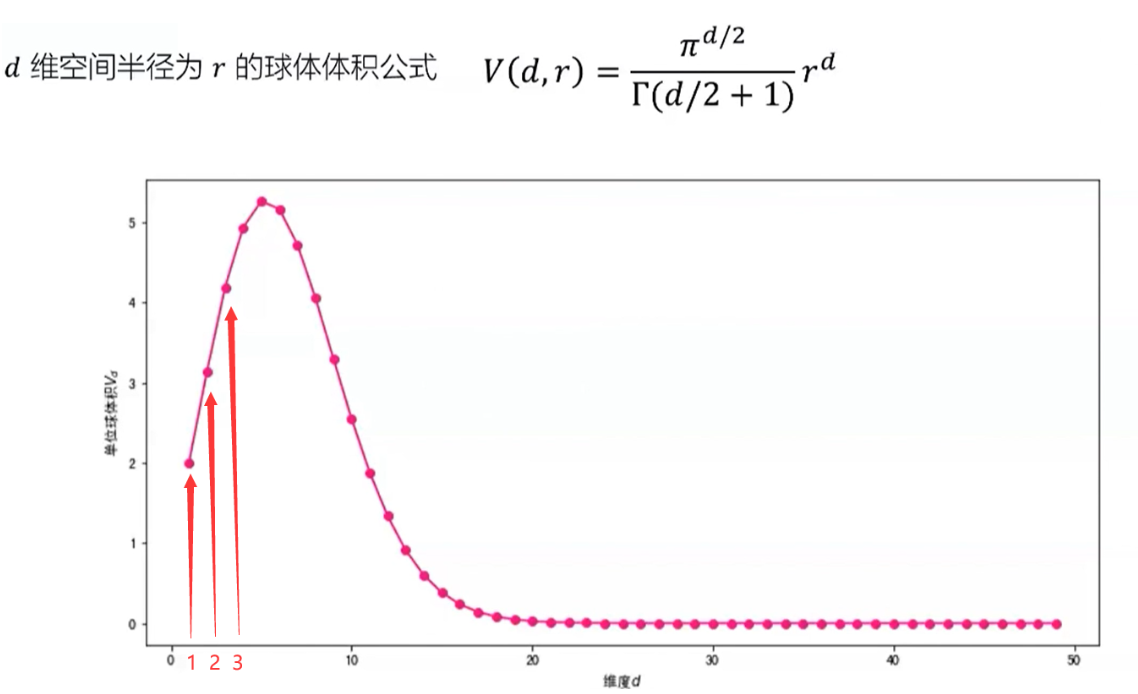

2、维度灾难给机器学习带来的影响 距离的失效、样本稀疏性和过度拟合、计算复杂度 高维空间中的欧式距离 d维空间样本x1和x2的欧式距离为:d(x1,x2)=[(i=1...d)(x1i-x2i)²]开方 随着维度的增加,单个维度对距离的影响越来越小,任意样本之间的距离趋于相同,在高维空间,(欧式)距离不是那么有效 基于距离的机器学习模型 K近邻:样本距离 支持向量机:样本到决策面距离 K-Means:样本到聚类中心的距离 层次聚类:不同簇之间的距离 推荐系统:商品或用户相似度 信息检索:查询和文档之前的相似度 过度拟合:模型对已知数据拟合较好,新的数据拟合较差 高位空间中样本变得极度稀疏,容易造成过度拟合问题 Hughes现象 在训练集固定时,锁着维度的增大,分类器性能不断提升直到达到最佳维度,继续增加维度分类器性能会下降 计算复杂度:决策树 随着维度的增加,计算复杂度指数增长 只能近似求解,得到局部最优解而非全局最优解(贪心算法) 例子:决策树 选择切分点对空间进行划分,每个特征m个取值,一共有d个特征,候选划分数量m的d次方(维度灾难) 3、如何应对维度灾难 特征选择与降维、正则化、核技巧 · 剃刀原理:如无必要,勿增实体 在能够获得较好的拟合效果前提下,尽量使用较为简单的模型 特征选择:选取特征子集 降维:使用一定变换,将高维数据转换为低维数据,PCA,流行学习,t-SNE等 · 正则化:对学习算法的修改--旨在减少泛化误差而不是训练误差

4、如何判断机器学习模型是否存在维度灾难 ·将目标函数通过某个大数定律表示成期望形式 ·通过证明对应的中心极限理论建立逼近误差的收敛率 ·估计Rademacher复杂度 5、实践案例:维度灾难的Python实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号