一、说在前面
物以类聚人以群分,今天老师讲的是聚类,又双叒叕是涉及数学知识的一节课,听得云里雾里,不过有一个很深的体会就是机器学习里面对随机和迭代的使用频率确实很高。
二、笔记
1、什么是聚类?
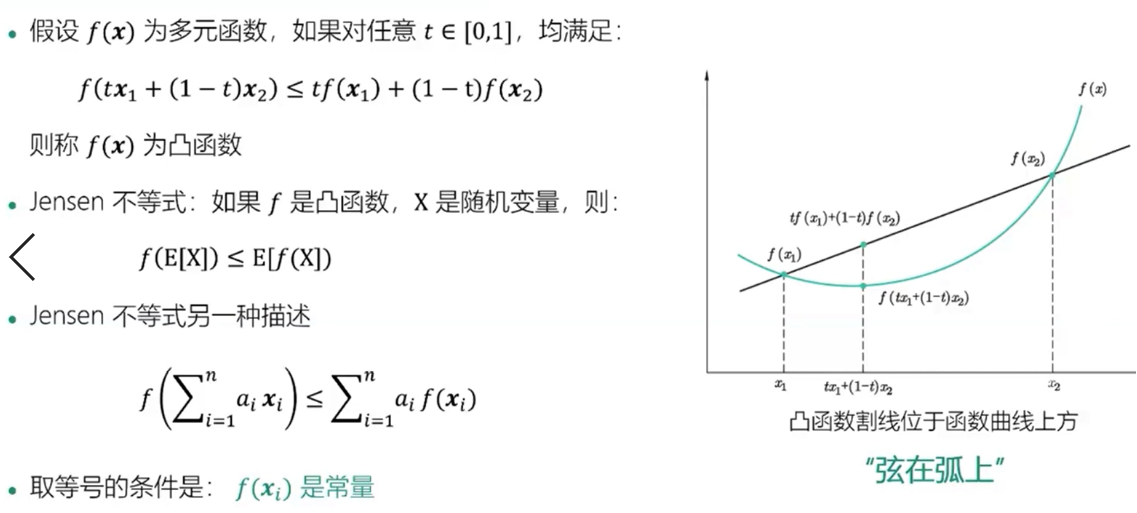
数学知识:凸函数与Jensen不等式
聚类的本质:将数据集中相似的样本进行分组的过程
每一个组成为一个簇,每个簇的样本对应一个潜在的类别
样本没有类别标签,一种典型的无监督学习方法
这些簇满足以下两个条件
相同簇的样本之间距离较近
不同簇的样本之间距离较远
聚类方法:层次聚类、K-Means、谱聚类
2、K-Means:基本原理、优化目标和求解方法
最初起源于信号处理,是一种比较流行的聚类方法
数据集为{xi}(i=1...n),将样本划分为k个簇,每个猝中心为cj(1≤j≤k)
优化目标:最小化所有样本点到所属簇中心的距离平方和
交替迭代法:(c,j差距较大适用)
固定c,优化r
固定r,优化c
算法流程
随机选择k个点作为初始中心
Repeat:将每个样本指派到最近的中心,形成k个类,重新计算每个类的中心为该类样本均值
直到中心不发生变化
3、高斯混合模型GMM:给类标签引入概率解释

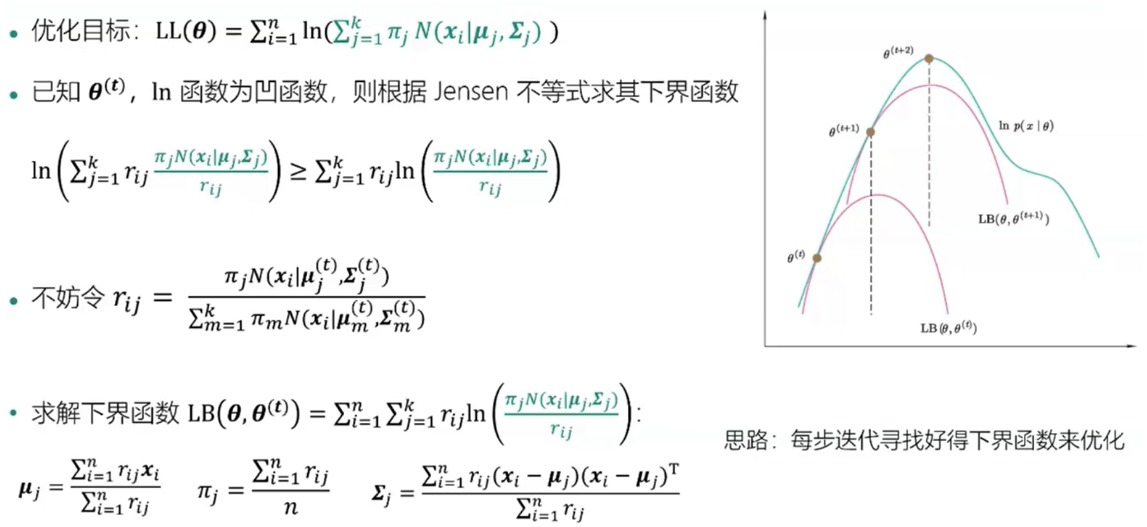
4、EM算法:一种求解隐变量概率模型的通用方法

5、实践案例:K-Means的python实现及在图像分割和新闻聚类中的应用
6、工具
NumPy:矩阵运算
Pandas:数据读取与预处理
Matplotlib:数据集可视化、聚类结果动画
Sklearn:中文新闻的向量化
Wordcloud:绘制聚类结果词云图
三、心得体会
通过这10节课的学习学到的肯定都只是皮毛,还需要之后继续的深入学习其中的核心要义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号