
机器学习--模型提升
一、说在前面
机器模型中,模型在使用的时候往往会出现误差,如何调整来减小误差就涉及到了模型提升的方法。
二、笔记
模型提升
1、模型提升的方法
模型误差的来源
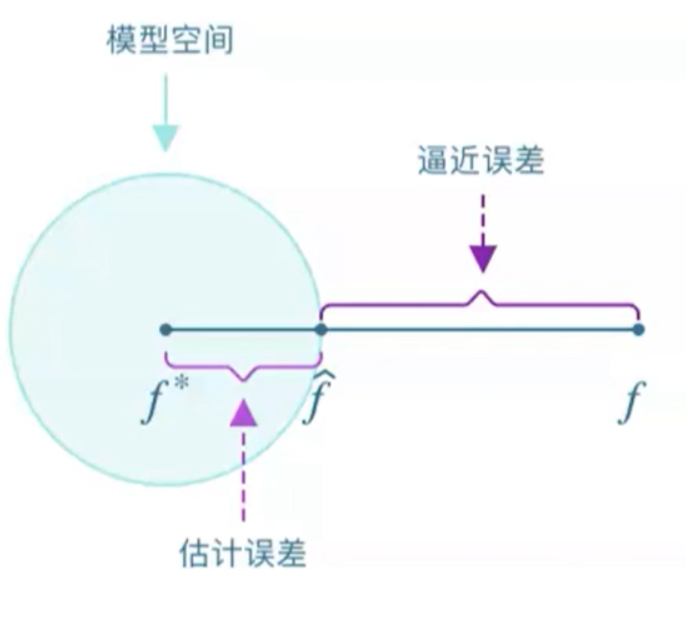
训练集D={xi,yi}(i=1...n)由函数f产生
假设空间H中理论上最好的函数为f^
用训练集D得到的函数f*=argmaxL(w)f∈H
逼近误差:模型空间与f的距离
估计误差:训练到的函数与模型空间最好的函数的距离
非线性模型
从线性模型到非线性模型
线性回归:多项式回归
支持向量机:给定的核函数组合,基本属于“猜测”
决策树:空间划分的思想来处理非线性数据
深度学习
感知机:线性回归+简单的非线性映射
多层感知机:多层神经元的组合,多个简单非线性函数的复合
深度学习:层数很大
模型集成
训练多个弱模型,组合成一个“强”模型,每一个弱模型有擅长的领域
2、决策树:将问题问到点子上
贪心算法
不纯度:表示落在当前节点的样本类别分布的均衡程度
节点分裂后,节点的不纯度应该更低(类分布更不均衡)
选择特征及对应分隔点,使得分裂前后的不纯度下降最大
节点不纯度的度量
Gini指数
节点t的Gini指数Gini(t)=1-(c=1...c求和)[p(c|t)]²
其中,p(c|t)是在节点t中第c类样本的相对频率,c为类的个数
当样本均匀分布在每一个类中,Gini指数为1-1/c,说明不纯度大
当样本都分布在统一各类中,Gini指数为0,说明不纯度小
例如D2{(1,2,3) (4,5)} Gini(D2)=1-((3/5)²+(2/5)²)=0.480
信息熵
用来描述信息不确定度的概念
节点t的信息熵为Entropy(t)=1-(c=1...c)p(c|t)log2p(c|t)
当样本均匀分布在每一个类中时,熵为log2C,说明不纯度大
当所有的样本属于同一个类是,熵为0,说明不纯度小
误分率
当按照多数类来预测当前节点的类别时,被错误分类的数据的比例
节点t的误分率为Error(t)=1-max(p(1|t),p(2|t),...,p(C|t))
3、随机森林:独立思考的重要性
最典型的Bagging算法:“随机”是其核心,“森林”意在说明它是通过组合多棵决策树来构建模型
主要特点:
对样本进行有放回抽样
对特征进行随机抽样
应用场景:市场营销、股票市场分析、金融欺诈检测、基因组数据分析和疾病风险预测
4、AdaBoost:站在前人的肩膀上前进
基本思想:通过改变样本权重串行地训练多个基分类器
每个基分类器带权重样本集下进行训练
根据其在训练样本中的加权误差来确定基分类器模型的权重
后一个分类器更加关注前一个分类器分错的样本
5、实践案例:决策树、随机森林和AdaBoost的Python实现,基于树模型的个人信用风险评估
三、心得体会
由于我在算法这方面不是很精通,在老师讲解的时候真的感觉到了力不从心,贪心算法这个算法听过很多次,但是从来没有去了解过具体的情况,反映出来一个很真实的问题,算法这方面还有很长的路要走。
模型提升
1、模型提升的方法模型误差的来源训练集D={xi,yi}(i=1...n)由函数f产生假设空间H中理论上最好的函数为f^用训练集D得到的函数f*=argmaxL(w)f∈H逼近误差:模型空间与f的距离估计误差:训练到的函数与模型空间最好的函数的距离
非线性模型从线性模型到非线性模型线性回归:多项式回归支持向量机:给定的核函数组合,基本属于“猜测”决策树:空间划分的思想来处理非线性数据
深度学习感知机:线性回归+简单的非线性映射多层感知机:多层神经元的组合,多个简单非线性函数的复合深度学习:层数很大
模型集成训练多个弱模型,组合成一个“强”模型,每一个弱模型有擅长的领域
2、决策树:将问题问到点子上贪心算法
不纯度:表示落在当前节点的样本类别分布的均衡程度节点分裂后,节点的不纯度应该更低(类分布更不均衡)选择特征及对应分隔点,使得分裂前后的不纯度下降最大
节点不纯度的度量Gini指数节点t的Gini指数Gini(t)=1-(c=1...c求和)[p(c|t)]²其中,p(c|t)是在节点t中第c类样本的相对频率,c为类的个数当样本均匀分布在每一个类中,Gini指数为1-1/c,说明不纯度大当样本都分布在统一各类中,Gini指数为0,说明不纯度小
例如D2{(1,2,3) (4,5)} Gini(D2)=1-((3/5)²+(2/5)²)=0.480信息熵用来描述信息不确定度的概念节点t的信息熵为Entropy(t)=1-(c=1...c)p(c|t)log2p(c|t)当样本均匀分布在每一个类中时,熵为log2C,说明不纯度大当所有的样本属于同一个类是,熵为0,说明不纯度小
误分率当按照多数类来预测当前节点的类别时,被错误分类的数据的比例节点t的误分率为Error(t)=1-max(p(1|t),p(2|t),...,p(C|t))
3、随机森林:独立思考的重要性最典型的Bagging算法:“随机”是其核心,“森林”意在说明它是通过组合多棵决策树来构建模型主要特点:对样本进行有放回抽样对特征进行随机抽样应用场景:市场营销、股票市场分析、金融欺诈检测、基因组数据分析和疾病风险预测
4、AdaBoost:站在前人的肩膀上前进基本思想:通过改变样本权重串行地训练多个基分类器每个基分类器带权重样本集下进行训练根据其在训练样本中的加权误差来确定基分类器模型的权重后一个分类器更加关注前一个分类器分错的样本
5、实践案例:决策树、随机森林和AdaBoost的Python实现,基于树模型的个人信用风险评估
