正则表达式lookahead
由于之前更改了自动删除索引脚本,让保留半个月的数据,有一些无用的索引都没有自动删除,现在需要手动删一下,尤其是那些数据为0的索引。
在服务器查看了一下,有4个日期的索引是空的,乘以数据类别7就是28个,但是由于所有索引有将近200个,如果通过肉眼去挑出这28个再复制粘贴,工作量很大、很无聊而且很容易出错,由于索引都是日期格式yyyy_mm_dd结尾,就想着用正则匹配的方法把它们找出来,再在sublime编辑一下去服务器执行。
1. 正则表达式 $结尾符
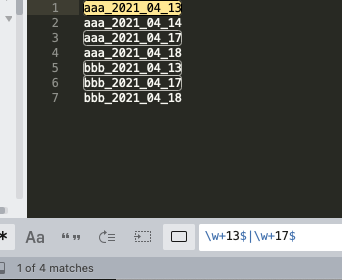
我们都知道结尾符号在正则表达式是$,如果有多个情况,则用|相连,如要匹配以13或17结尾的行,用
\w+13$|\w+17$
2. lookahead
那匹配不以xx结尾的呢??正则表达式似乎很难做到,但不是做不到,先要了解Lookahead的概念,可以戳此链接Lookahead 看官方文档。Lookahead有分negative和positive两种。
1. Negative lookahead:
如果是要找出包含某些字符,但是这些字符后面紧跟的不能是某些字符的字符串。 格式是用括号括起来,?!开头。如q(?!u), 可以匹配所有q后面不是u的字符, 如qa, qb, qc, Iraq等等。对于Iraq,引擎会先匹配到q, 然后发现进入了一个negtative lookahead, 接下来匹配u字符,但是Iraq后面是个空格,所以不满足lookahead,再加上是个negative的,负负得正所以会返回q.
2. Positive lookahead:
某些字符后紧跟某些字符的字符串,格式是用括号括起来,?=开头。如表达式q(?=u), 可以匹配qu, 等同于表达式qu。
要挑出不以xx结尾的行,很明显要用Negative lookahead。
3. 不以xx开头、结尾, 不包含xx的正则表达式
了解了概念之后,就可以动手写表达式了。
1. 不以17, 18开头的行
^(?!17|18).*$ 2. 不包含17, 18的行, 如下可匹配到1,2,5行。
^((?!17|18).)*$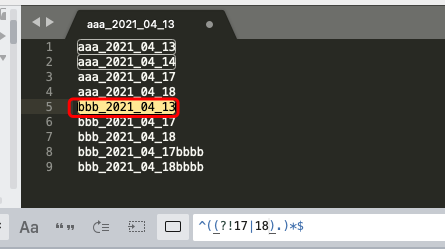
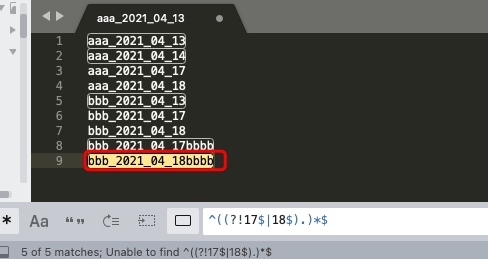
3. 不以17, 18结尾的行, 如下可匹配到1,2,5, 8, 9行。
^((?!17$|18$).)*$
4. 解释
接下来以上述3的正则表达式 ^((?!17$|18$).)*$ 为例,做出解释:
1. ^表示从行首开始匹配
2. 第一个左括号(表示分组开始
3. 第二个左括号(表示lookahead开始
4. ?!表示是个negative lookahead
5. 17$表示以17结尾,17$|18$表示以17或18结尾
6. )表示negative lookahead结束
7. .表示匹配非\n的任意字符,由于每个字符后面其实是有个空格的,这个.一定不能少
8. )表示分组结束
9. *表示把最后一个匹配到的值放入\1变量
10. 在$行尾结束匹配
参考: Stack Overflow-- Regular expression to match a line that doesn't contain a word
附今天整个操作步骤:
1. curl 'localhost:9200/_cat/indices?v'| sort -k 2, 先把所有索引拷贝到sublime
2. 用sublime的csv工具把第二列索引列拷贝出来
3. 用正则表达式^((?!(04_13$|04_14$|04_17$|04_18$)).)*$, 把不是这几个日期的行全部替换成空
4. 把空行替换成空
5. 用csv工具在每列列头插入 curl -XDELETE es:9200/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号