[参考]ASCII对照表 及 字符与二进制、十进制、16进制之间的转化(C/C++)
第1节 ASCII码对照表
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCⅡ)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
ASCII第一次以规范标准的型态发表是在1967年,最后一次更新则是在1986年,至今为止共定义了128个字符,其中33个字符无法显示(这是以现今操作系统为依归,但在DOS模式下可显示出一些诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符,控制字符的用途主要是用来操控已经处理过的文字,在33个字符之外的是95个可显示的字符,包含用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。
1.1 ASCII控制字符
|
二进制 |
十进制 |
十六进制 |
缩写 |
名称/意义 |
|
0000 0000 |
0 |
00 |
NUL |
空字符(Null) |
|
0000 0001 |
1 |
01 |
SOH |
标题开始 |
|
0000 0010 |
2 |
02 |
STX |
本文开始 |
|
0000 0011 |
3 |
03 |
ETX |
本文结束 |
|
0000 0100 |
4 |
04 |
EOT |
传输结束 |
|
0000 0101 |
5 |
05 |
ENQ |
请求 |
|
0000 0110 |
6 |
06 |
ACK |
确认回应 |
|
0000 0111 |
7 |
07 |
BEL |
响铃 |
|
0000 1000 |
8 |
08 |
BS |
退格 |
|
0000 1001 |
9 |
09 |
HT |
水平定位符号 |
|
0000 1010 |
10 |
0A |
LF |
换行键 |
|
0000 1011 |
11 |
0B |
VT |
垂直定位符号 |
|
0000 1100 |
12 |
0C |
FF |
换页键 |
|
0000 1101 |
13 |
0D |
CR |
归位键 |
|
0000 1110 |
14 |
0E |
SO |
取消变换(Shift out) |
|
0000 1111 |
15 |
0F |
SI |
启用变换(Shift in) |
|
0001 0000 |
16 |
10 |
DLE |
跳出数据通讯 |
|
0001 0001 |
17 |
11 |
DC1 |
设备控制一(XON 启用软件速度控制) |
|
0001 0010 |
18 |
12 |
DC2 |
设备控制二 |
|
0001 0011 |
19 |
13 |
DC3 |
设备控制三(XOFF 停用软件速度控制) |
|
0001 0100 |
20 |
14 |
DC4 |
设备控制四 |
|
0001 0101 |
21 |
15 |
NAK |
确认失败回应 |
|
0001 0110 |
22 |
16 |
SYN |
同步用暂停 |
|
0001 0111 |
23 |
17 |
ETB |
区块传输结束 |
|
0001 1000 |
24 |
18 |
CAN |
取消 |
|
0001 1001 |
25 |
19 |
EM |
连接介质中断 |
|
0001 1010 |
26 |
1A |
SUB |
替换 |
|
0001 1011 |
27 |
1B |
ESC |
跳出 |
|
0001 1100 |
28 |
1C |
FS |
文件分割符 |
|
0001 1101 |
29 |
1D |
GS |
组群分隔符 |
|
0001 1110 |
30 |
1E |
RS |
记录分隔符 |
|
0001 1111 |
31 |
1F |
US |
单元分隔符 |
|
0111 1111 |
127 |
7F |
DEL |
删除 |
1.2 ASCII可显示字符
|
二进制 |
十进制 |
十六进制 |
图形 |
二进制 |
十进制 |
十六进制 |
图形 |
二进制 |
十进制 |
十六进制 |
图形 |
|
0010 0000 |
32 |
20 |
(空格) |
0100 0000 |
64 |
40 |
@ |
0110 0000 |
96 |
60 |
` |
|
0010 0001 |
33 |
21 |
! |
0100 0001 |
65 |
41 |
A |
0110 0001 |
97 |
61 |
a |
|
0010 0010 |
34 |
22 |
" |
0100 0010 |
66 |
42 |
B |
0110 0010 |
98 |
62 |
b |
|
0010 0011 |
35 |
23 |
# |
0100 0011 |
67 |
43 |
C |
0110 0011 |
99 |
63 |
c |
|
0010 0100 |
36 |
24 |
$ |
0100 0100 |
68 |
44 |
D |
0110 0100 |
100 |
64 |
d |
|
0010 0101 |
37 |
25 |
% |
0100 0101 |
69 |
45 |
E |
0110 0101 |
101 |
65 |
e |
|
0010 0110 |
38 |
26 |
& |
0100 0110 |
70 |
46 |
F |
0110 0110 |
102 |
66 |
f |
|
0010 0111 |
39 |
27 |
' |
0100 0111 |
71 |
47 |
G |
0110 0111 |
103 |
67 |
g |
|
0010 1000 |
40 |
28 |
( |
0100 1000 |
72 |
48 |
H |
0110 1000 |
104 |
68 |
h |
|
0010 1001 |
41 |
29 |
) |
0100 1001 |
73 |
49 |
I |
0110 1001 |
105 |
69 |
i |
|
0010 1010 |
42 |
2A |
* |
0100 1010 |
74 |
4A |
J |
0110 1010 |
106 |
6A |
j |
|
0010 1011 |
43 |
2B |
+ |
0100 1011 |
75 |
4B |
K |
0110 1011 |
107 |
6B |
k |
|
0010 1100 |
44 |
2C |
, |
0100 1100 |
76 |
4C |
L |
0110 1100 |
108 |
6C |
l |
|
0010 1101 |
45 |
2D |
- |
0100 1101 |
77 |
4D |
M |
0110 1101 |
109 |
6D |
m |
|
0010 1110 |
46 |
2E |
. |
0100 1110 |
78 |
4E |
N |
0110 1110 |
110 |
6E |
n |
|
0010 1111 |
47 |
2F |
/ |
0100 1111 |
79 |
4F |
O |
0110 1111 |
111 |
6F |
o |
|
0011 0000 |
48 |
30 |
0 |
0101 0000 |
80 |
50 |
P |
0111 0000 |
112 |
70 |
p |
|
0011 0001 |
49 |
31 |
1 |
0101 0001 |
81 |
51 |
Q |
0111 0001 |
113 |
71 |
q |
|
0011 0010 |
50 |
32 |
2 |
0101 0010 |
82 |
52 |
R |
0111 0010 |
114 |
72 |
r |
|
0011 0011 |
51 |
33 |
3 |
0101 0011 |
83 |
53 |
S |
0111 0011 |
115 |
73 |
s |
|
0011 0100 |
52 |
34 |
4 |
0101 0100 |
84 |
54 |
T |
0111 0100 |
116 |
74 |
t |
|
0011 0101 |
53 |
35 |
5 |
0101 0101 |
85 |
55 |
U |
0111 0101 |
117 |
75 |
u |
|
0011 0110 |
54 |
36 |
6 |
0101 0110 |
86 |
56 |
V |
0111 0110 |
118 |
76 |
v |
|
0011 0111 |
55 |
37 |
7 |
0101 0111 |
87 |
57 |
W |
0111 0111 |
119 |
77 |
w |
|
0011 1000 |
56 |
38 |
8 |
0101 1000 |
88 |
58 |
X |
0111 1000 |
120 |
78 |
x |
|
0011 1001 |
57 |
39 |
9 |
0101 1001 |
89 |
59 |
Y |
0111 1001 |
121 |
79 |
y |
|
0011 1010 |
58 |
3A |
: |
0101 1010 |
90 |
5A |
Z |
0111 1010 |
122 |
7A |
z |
|
0011 1011 |
59 |
3B |
; |
0101 1011 |
91 |
5B |
[ |
0111 1011 |
123 |
7B |
{ |
|
0011 1100 |
60 |
3C |
< |
0101 1100 |
92 |
5C |
\ |
0111 1100 |
124 |
7C |
| |
|
0011 1101 |
61 |
3D |
= |
0101 1101 |
93 |
5D |
] |
0111 1101 |
125 |
7D |
} |
|
0011 1110 |
62 |
3E |
> |
0101 1110 |
94 |
5E |
^ |
0111 1110 |
126 |
7E |
~ |
|
0011 1111 |
63 |
3F |
? |
0101 1111 |
95 |
5F |
_ |
|
|
|
|
第2节 字符的进制转换
2.1 获取字符(8位)的上四位和下四位
举例1:字符‘a’,它对应的二进制(或称ASCII码)为0110 0001,该二进制的上四位为0110,下四位为0001,这两个二进制对应的十六进制为6和1。
举例2:字符‘d’,它对应的二进制(或称ASCII码)为0110 0100,该二进制的上四位为0110,下四位为0100,这两个二进制对应的十六进制为6和4。
源代码:
|
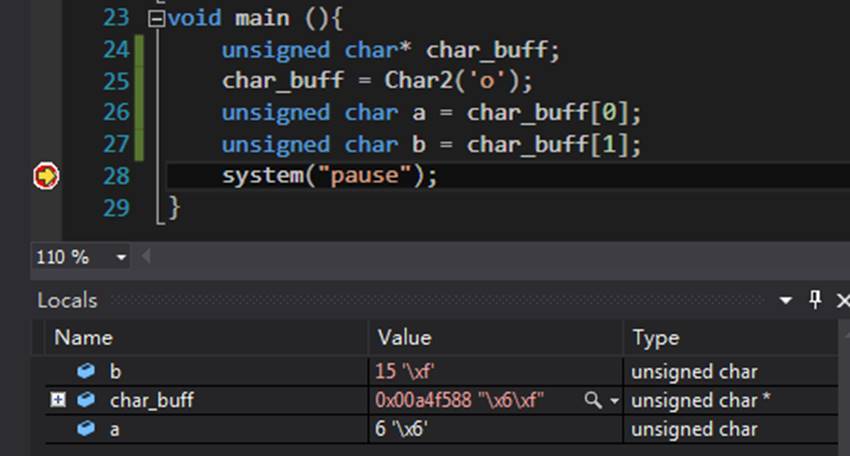
#include<iostream> // 核心函数 unsigned char* Char2(unsigned char ch){ static unsigned char szHex[2]; szHex[0] = ch/16; szHex[1] = ch%16; return &szHex[0]; } // 调试部分 void main (){ unsigned char* char_buff; char_buff = Char2('a'); system("pause"); } |
由于二进制不好输出,这里通过调试查看char_buff的结果:字符’o’的上四位a=’\x6’,下四位b=’\xf’。其中\x表示16进制,也就是说a的16进制数为6,b的十六进制数为f,各自对应的十进制数为6和15。
2.2 获取字符(上表中的‘图形’)所对应的 十六进制字符
举例3:(续例1)字符‘a’,它对应的16进制为61,若要在屏幕输出两个字符6和1,需要将‘a’转化为两个字符,这两个字符的ASCII码为0011 0110,0011 0001。
举例4:字符‘o’,它对应的16进制为6F,若要在屏幕输出两个字符6和F,需要将‘o’转化为两个字符,这两个字符的ASCII码为0011 0110,0100 0110。
|
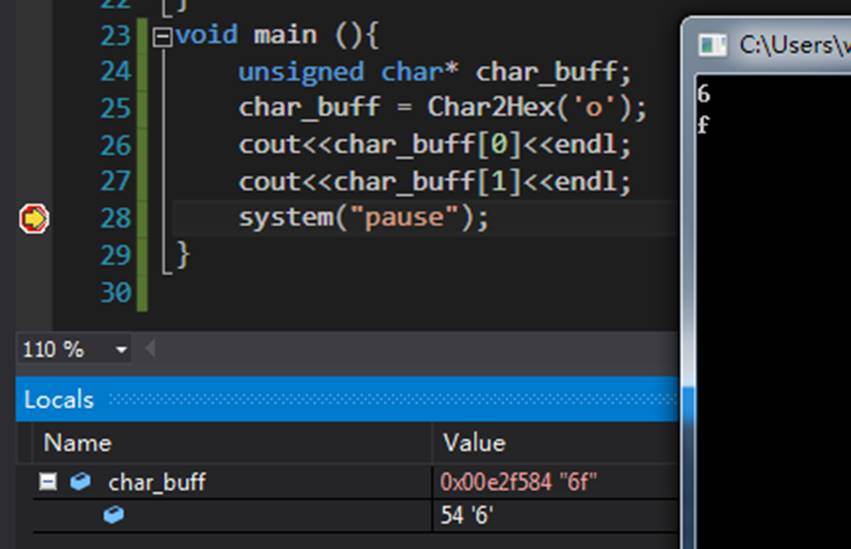
#include<stdlib.h> using namespace std; unsigned char* Char2Hex(unsigned char ch){ unsigned char byte[2],i; static unsigned char szHex[2]; byte[0] = ch/16; // 获得ch字符(8位)的上四位 byte[1] = ch%16; // 获得ch字符(8位)的下四位 for(i=0; i<2; i++){ if(byte[i] >= 0 && byte[i] <= 9) szHex[i] = '0' + byte[i]; else szHex[i] = 'a' + byte[i] - 10; } return &szHex[0]; } void main (){ unsigned char* char_buff; char_buff = Char2Hex('o'); cout<<char_buff[0]<<endl; cout<<char_buff[1]<<endl; system("pause"); } |
输出结果:
2.3 获取字符对应的十六进制字符的第二种方法(傻瓜式)
根据2.1节的获取8进制字符的上4位、下4位的方法,我联想到了一个新的方法来获取其16进制的字符。结果同2.2节,但原理很简单:
举例5:字符‘o’,它的ASCII码为0110 1111,上四位0110,下四位1111,这两个二进制对应的十进制分别为6和15。只需将6和15通过一个unsigned char数组进行映射即可获得两个字符6和F。
这个unsigned char数组的构造为:char_map[17] = "0123456789ABCDEF"; 具体代码如下。结果与2.2节一致。
|
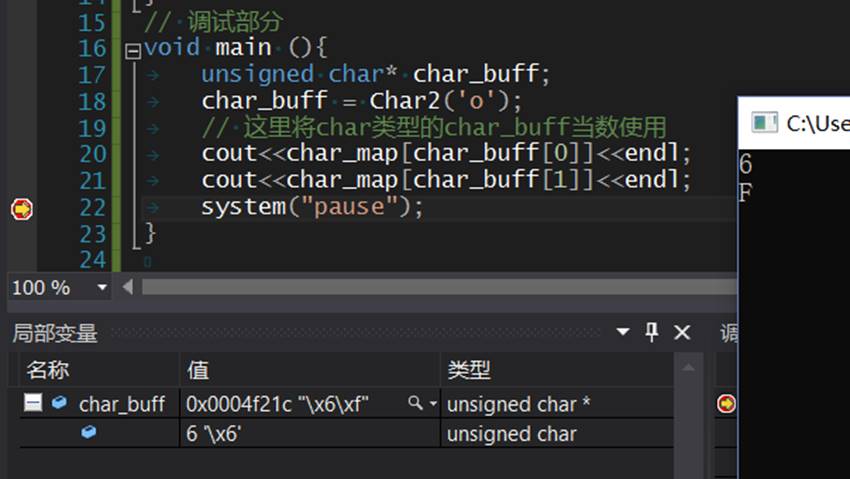
#include<iostream> #include<stdlib.h> using namespace std; // 用一个字符数组做映射 unsigned char char_map[17] = "0123456789ABCDEF"; //unsigned char char_map[16] = {'0','1','2','3','4','5','6','7','8','9', // 'A','B','C','D','E','F'}; // 核心函数 仍然是2.1节中的代码 unsigned char* Char2(unsigned char ch){ static unsigned char szHex[2]; szHex[0] = ch/16; szHex[1] = ch%16; return &szHex[0]; } // 调试部分 void main (){ unsigned char* char_buff; char_buff = Char2('o'); // 这里将char类型的char_buff当数使用 cout<<char_map[char_buff[0]]<<endl; cout<<char_map[char_buff[1]]<<endl; system("pause"); } |
输出结果:
2.4 递归的方法获取字符对应的二进制字符
举例6:字符‘a’,它对应的ASCII码为0011 0110,没错我就是要在屏幕上输出0011 0110!!!
具体的代码贴在下面,注释写的很清楚,需要的话可以仔细研究一下。
其实这与“中序二叉树遍历“算法类似
|
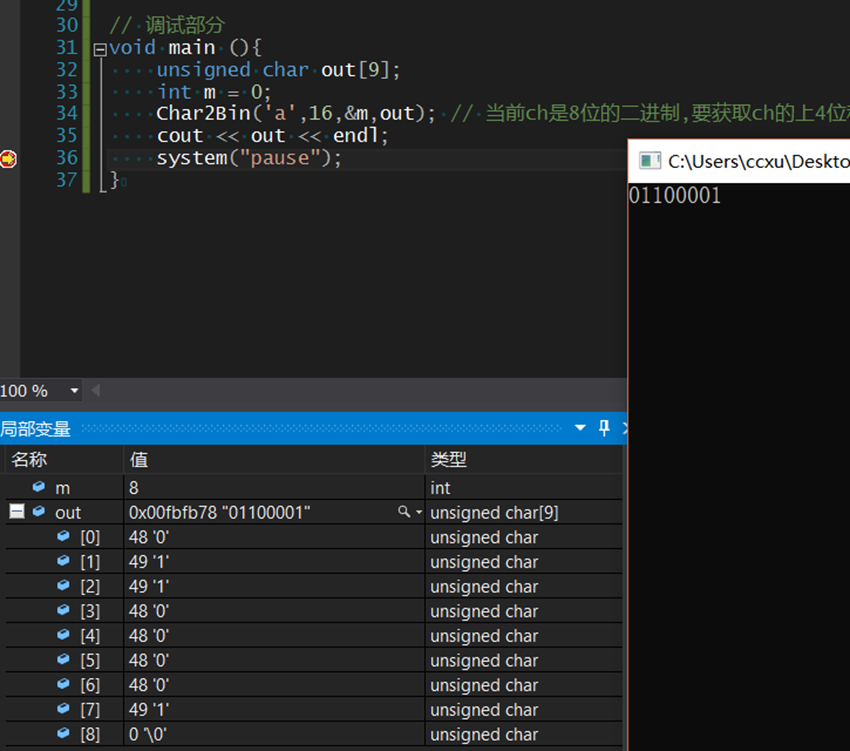
#include<iostream> #include<stdlib.h> using namespace std; // 核心函数 // ch:传入的字符; n:除数,n:除数,它等于当前ch可能到的最大值的根; // m:指针,用于索引数组,初始值为0; out_bin[]:输出的二进制字符串 void Char2Bin(unsigned char ch,int n, int *m, unsigned char out_bin[]){ if (n>4){ // ch/n和ch%n是为4位的二进制(最大值可以用4位的二进制表示,实际它还是unsigned char类型的,占用8位) // 要获取4位二进制的上2位和下二位,除数n=2^(4/2)=4 Char2Bin(ch/n,n/4,m,out_bin); Char2Bin(ch%n,n/4,m,out_bin); } else if (n>2){ // ch/n和ch%n是2位的二进制 // 要获取它的上1位和下一位,除数n=2^(2/2)=2 Char2Bin(ch/n,n/2,m,out_bin); Char2Bin(ch%n,n/2,m,out_bin); } else{ // 当前ch是2位的二进制,只需将其转化为0和1即可 out_bin[(*m)++] = ch/2 + '0'; out_bin[(*m)++] = ch%2 + '0'; return; // 到这里必须返回,否则都会运行最后一行再返回,造成冗余 } out_bin[8] = '\0'; // 字符数组最后以'\0'结尾就会变成字符串, // 可以参考 http://www.runoob.com/cplusplus/cpp-strings.html }
// 调试部分 void main (){ unsigned char out[9]; int m = 0; Char2Bin('a',16,&m,out); // 当前ch是8位的二进制,要获取ch的上4位和下4位,所以除数n=2^(8/2)=16 cout << out << endl; system("pause"); } |
输出结果:
对于文章内容,博主尽量做到真实可靠,并对所引用的内容附上原始链接。但也会出错,如有问题,欢迎留言交流~
若标题前没有“[转]”标记,则代表该文章为本人(司徒鲜生)所著,转载及引用请注明出处,谢谢合作!
本站首页:http://www.cnblogs.com/stxs/
最新博客见CSDN:https://blog.csdn.net/qq_45887327

 浙公网安备 33010602011771号
浙公网安备 33010602011771号