【操作系统】3.内存管理
1.程序分段和内存分区
程序执行需要首先加载到内存中,但完完整整的把一个很大的程序加载进去需要一块完整的地址空间,并且也不符合我们的直观感受,程序员眼中的内存是一个逻辑空间,这里面包括了一段程序、变量、栈等等,我们将一个程序进行分段,然后再存储到内存中

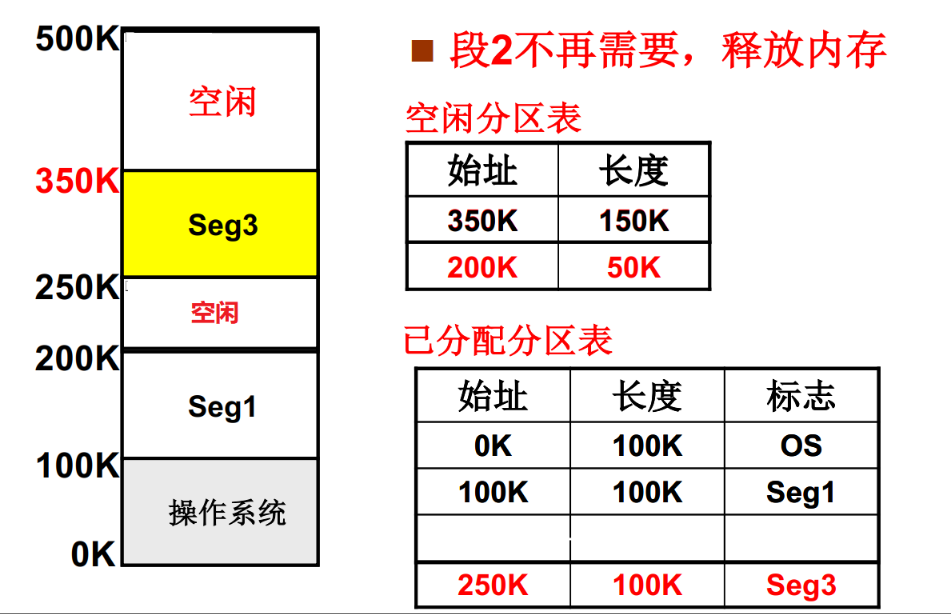
这里很容易想到对内存的处理方法就是分区,我们把内存分成很多区域,根据进程需要空间的大小去申请一块内存分区,在这个分区中存入我们程序已经分开好的段。但这里也会存在一个问题,就是内存碎片,我们可以看到假设进程2内存被释放后,内存中一共有200K长度的空闲空间,但是这时如果我们想把一个需要160K内存的进程加载进入内存,就无法实现了,因为没有一块完整的区域来给这个进程使用
2.页表、多级页表和块表
页表:为了解决内存分区带来的内存浪费问题,我们引入页表的概念,下面是一个16位地址机器,我们将内存分为4K大小的页,页中的地址仍然是逻辑地址,例如页号0x2240表示的逻辑页号是2240左移3位0x02,通过查找页表可以找到它对应的页框号(物理地址)为3,这样我们实现了通过页表来访问内存。这种方案下每个进程最多浪费一个页表的空间,比分区的利用率要高得多。

单级页表的问题:我们实际使用中,如果有32位地址,分页大小为4K(212),则我们每个程序需要220次个4字节地址的页表来将自己的逻辑地址和物理地址对应起来,需要4M内存,因为每个进程的页表中只能包含自己的内存地址,不能影响其他程序的运行,那么如果有100个进程运行就需要100个页表400M空间来对应它们的物理地址,但实际上大部分的逻辑地址都不会用到。
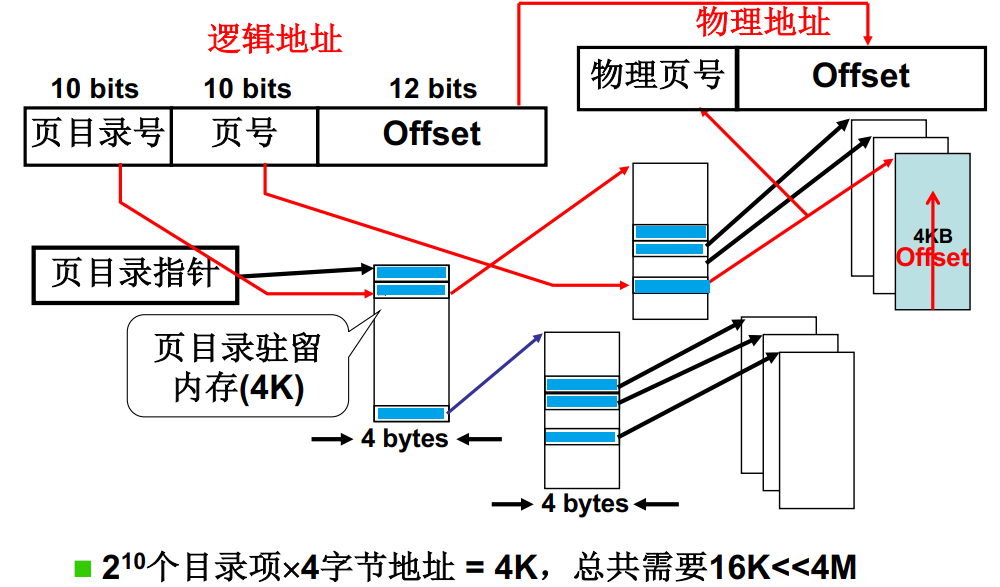
多级页表:我们引入多级页表的概念,多级页表就类似于章和节的关系,我们将前20位地址分为两部分,10位表示页目录号,10位表示页号。我们在内存中构建完整的页目录,这可以保证内存物理地址查找过程的连续性。
通过PCB查找该进程页目录指针;接下来通过页目录号查找该段物理内存所在的页目录,因为我们在内存中构建了完整的章目录,所以这段地址是连续的,可以一次定位完成;然后根据页号来定位对应的节目录,这里也是连续的,所以也可以一次定位;最后就找到了该段逻辑地址对应的物理地址,本次访存完成。
这种方式之所以可以节省内存,最大的原因是我们只载入完整的章目录,以及有内容的节目录。以下图为例,如果使用单级页表需要4M内存完整保存一个顺序页表;但是使用多级目录,我们只需要保存章目录4K,节目录3*4K也就是16K就可以完整表示该进程所需的物理地址了。
多级页表的问题:64位地址已经普及,这将会大大增加多级页表的层数,也会影响内存访问的速度
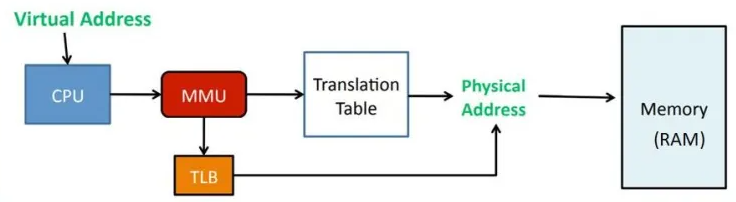
块表: Translation Lookaside Buffer 地址转换后援缓冲器。TLB就是页表的Cache,属于MMU的一部分,由于地址翻译开销很大,所以引入高速缓存来尝试直接获取物理地址绕过虚拟内存向物理内存转换,TLB中存储了一小部分内存映射关系。
由于TLB成本高所以一般容量都比较小,但是由于计算机程序的访问模式通常表现出局部性原理,即近期访问的地址往往在未来会再次访问。因此,较小的TLB可以容纳大部分频繁访问的映射关系,从而提供高命中率。这是因为相对较小的TLB更适合捕获短期局部性。
3.段页结合的内存管理
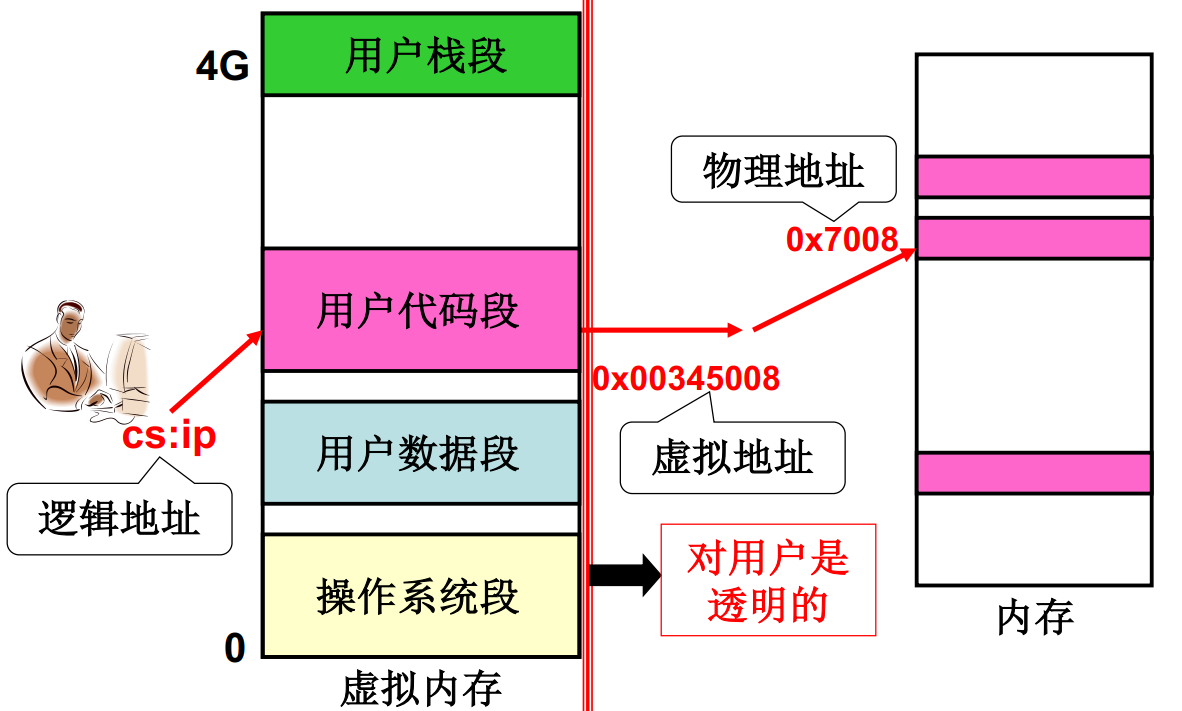
程序员希望可以使用分段的方式编写程序,内存需要通过分页的方式增加使用率,所以引出段页结合的内存管理方式。程序员看到的是程序的逻辑地址 段号+偏移,例如0x00345008,经过内存分页映射表后操作系统找到实际的页框号物理内存0x7008
4.内存换页
在程序员眼中的内存是一段完整的4G空间内存,并且程序被分成多个段加载到内存中,但内存不可能把自己完整交给一个程序,为了实现程序分段的思想,并且满足内存分页的内存管理方式,这里就引出了内存换页的思想,即我们4G的虚拟内存实际上只对应了一小部分物理内存。我们访问虚拟内存0G-1G时,将这部分映射到物理内存,访问虚拟内存3G-4G时,再把这部分映射到物理内存
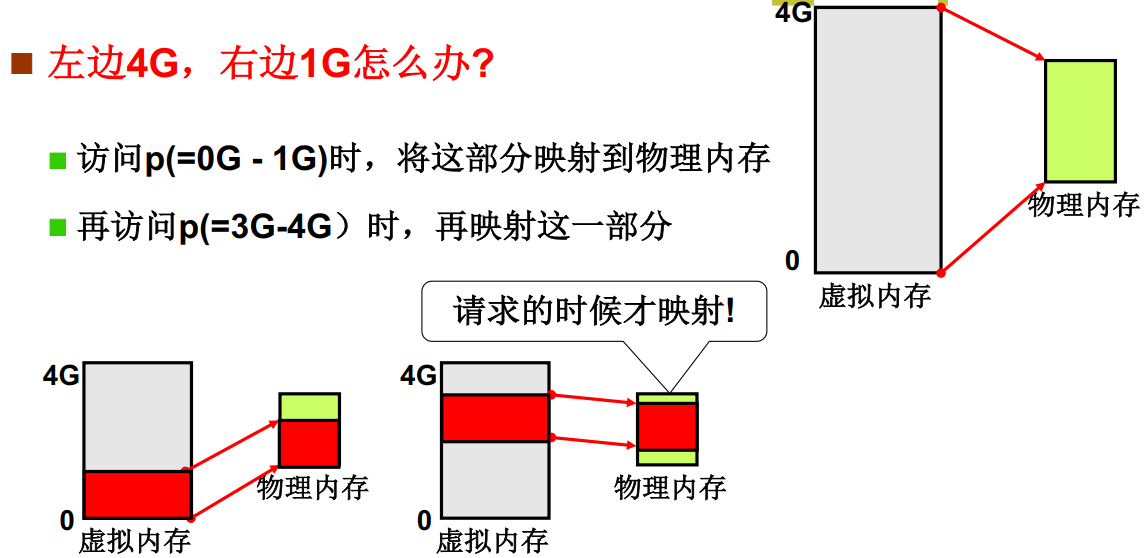
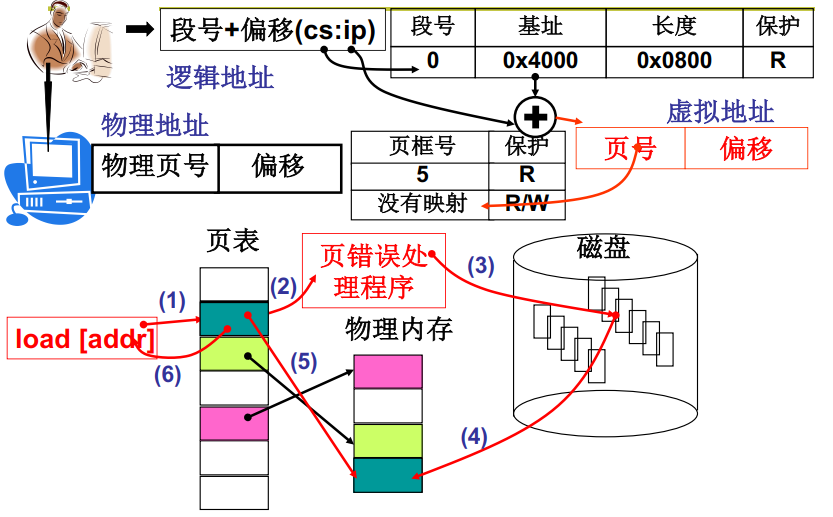
- load [addr] 程序读到逻辑地址段号通过查表找到基址,加上偏移量就是内存的虚拟地址
- MMU通过虚拟地址基值计算出虚拟地址的逻辑页号并查找对应的页框号
- 页表项中没有记录该段虚拟地址对应的物理地址页框号说明缺页(Page Fault),发出0x14中断请求
- cpu处理中断请求,在磁盘中找到需要的页,加载到物理内存并且在页表项中修改映射关系
- 再次执行 load [addr]
5.内存换出
当主存空间不足,并且要读取的内存在磁盘中而非物理内存中,或者主存中某个片段长时间没有被使用的时候,操作系统会把主存中该页换出到磁盘上,以释放主存的空间给其他进程使用,更好利用主存资源
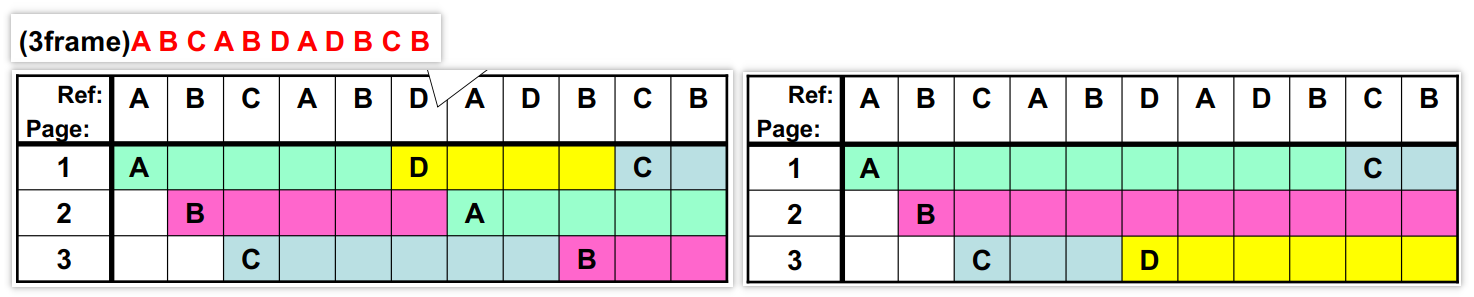
下面介绍FIFO和MIN页面置换,假设我们的物理内存有3个页,其他内容保存在磁盘上,按照ABCABDADBCB的顺序读取内容
FIFO是先进先出的思想读到D的时候由于物理内存没有D的映射,所以把最先进入的A换出,但是可以看到接下来马上又要使用A,这里不太合适
MIN是最远使用的最先被淘汰,我们看到在需要读取D的时候,接下来又使用了ABD,而C是最远使用的,所以我们让C换出给D,这种方式最优,但没办法知道之后要读取的物理内存是哪些
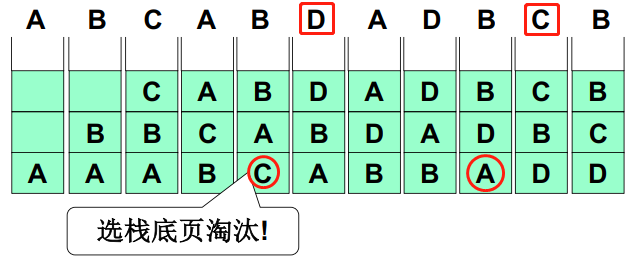
LRU是将最长时间没有使用的页换出,下面给出一个通过维护页码栈来实现内存换出的方式,可以发现它与MIN的顺序竟然完全相同,但是这种实现方式开销较大,需要大量修改指针
LRU的近似实现,由于准确实现最长时间页换出开销较大,所以提出一种近似实现方案,使用循环队列来记录当前的引用情况,近似实现长时间未使用的淘汰
- 访问一个页的时候,将这个页的引用设置为1
- 换出页的时候,如果是1就将其清0并继续向下扫描,如果是0就淘汰该页
该方案存在一个问题,在缺页很少的情况下
- 所有引用设置都是1,假设换页指针指向位置1,此时需要换出页时换出页指针开始工作,它需要把所有的页引用都先减1,此时所有页引用都为0;然后进行第二轮换出页,位置1的引用是0,所以淘汰位置1的页
- 因为换页很少所以所有引用又会被设置为1,此时如果再进行换页,他一定会从位置2开始扫描一轮,然后把位置2换页
- 这意味着它退化成了FIFO先入先出,它失去了LRU的特性

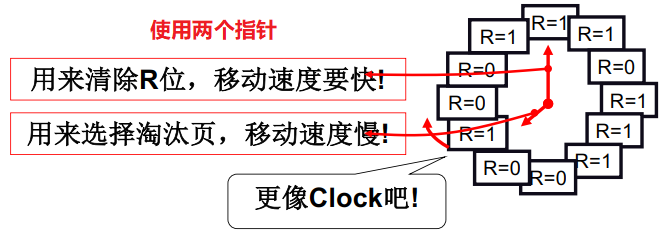
LRU的核心思想是近似的找到最长时间未使用的页,引出Clock算法,我们可以用两个指针来实现这个思想
- 清除R位的1:这个指针速度很快,快速的把R位清除来保证所有是1的描述一定在最近一段时间使用过
- 如果是0就换页:这个指针负责淘汰,如果该位置是0则表示在清楚R位指针旋转一周的周期内该内存页未被使用过
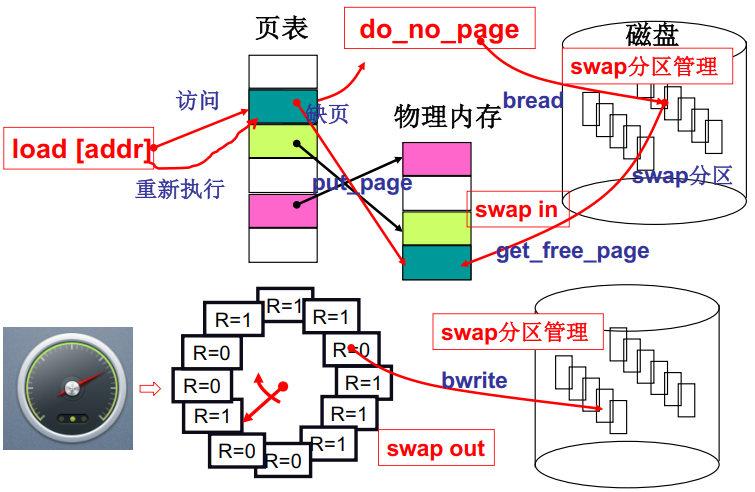
最后完整的内存管理应该是如下图所示的样子,cpu读取一条指令,根据CS:IP确定该指令在虚拟内存中的位置,MMU根据逻辑页号找到查找对应页框号,MMU发现缺页触发0x14中断,进行中断处理在磁盘中找到需要的内容并加载到物理内存中,修改页表项,接下来cpu重新读取该指令进行CS:IP - 虚拟内存 - 物理内存的访存,本次访存完成
6.内存页框的分配
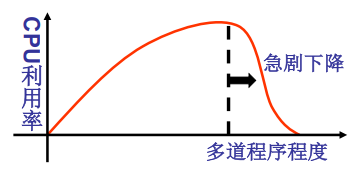
随着程序数量增加CPU利用率会上升,但程序数量过多的时候每个进程分配到的页就会太少,进程的缺页率增大到一定程度就会导致进程总会需要等待调页完成,最后导致CPU一直在等待系统IO,利用率降低,这会导致颠簸(thrashing),所以内存页框的分配也是一个需要考虑的问题,但一个简单的操作系统可以暂时不考虑这些。结合第1.2.3章内容,一个基本的操作系统已经完成了

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步