决策树学习
1.决策树是什么:
决策树 = 决策 + 树。
其核心思想是程序选择语句if else。
定义:先计算整体信息熵, 再去找信息增益最大的作为根/子节点,以此反复,直到属性穷尽。
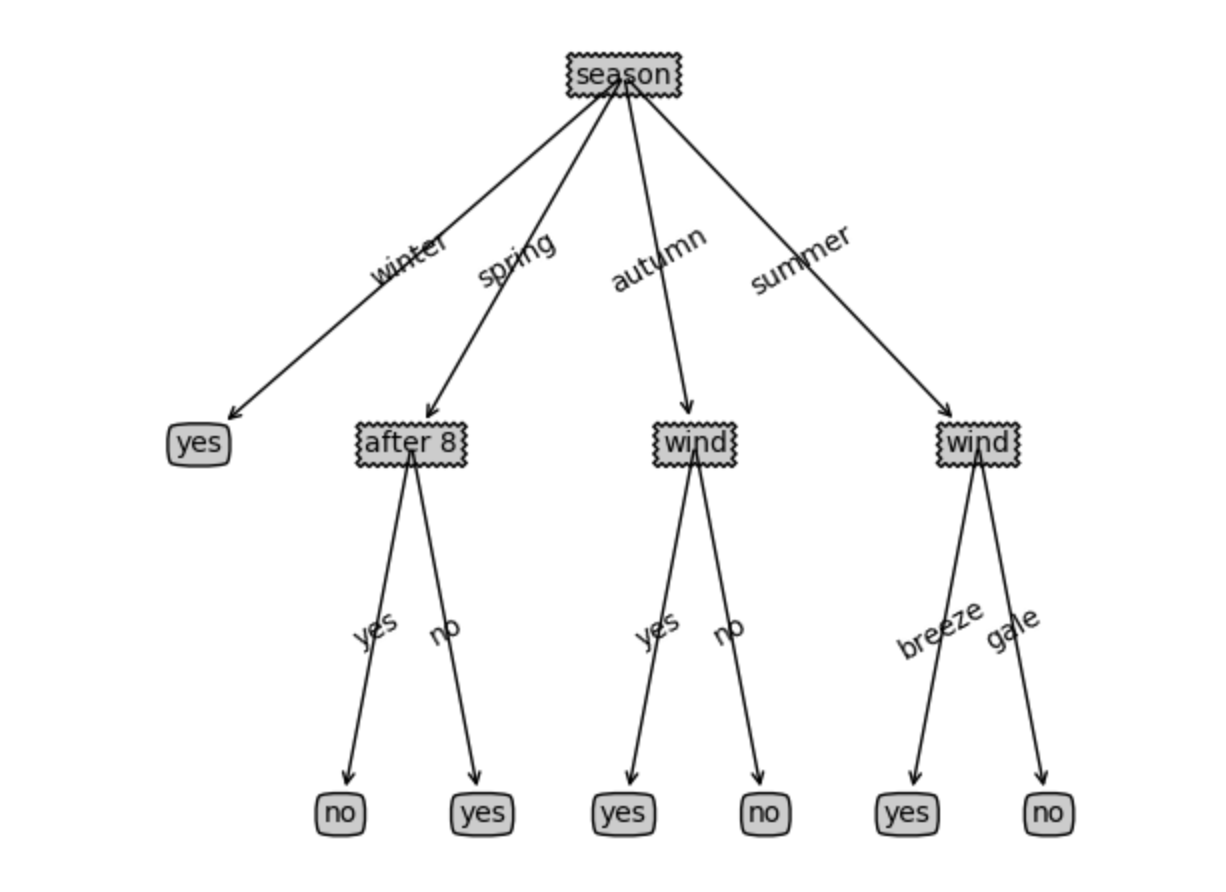
如下图:判断是否赖床的dtree模型。
2.过拟合和剪枝:
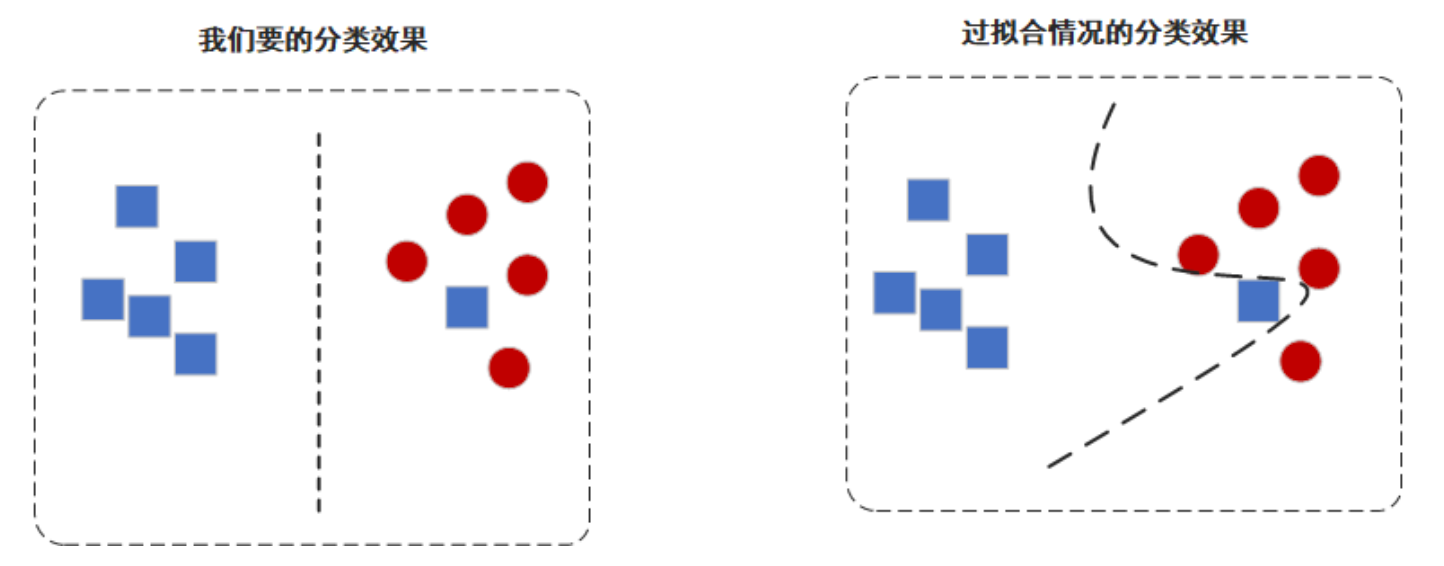
避免过拟合现象,追求普适性。
剪枝,即减少树的高度就是为了解决过拟合,
过拟合的情况下,决策树是能够对给定样本中的每一个属性有一个精准的分类的,但太过精准就会导致上面图中的那种情况,丧失了普适性。
而剪枝又分两种方法,预剪枝干,和后剪枝。这两种方法其实还是蛮好理解的,一种是自顶向下,一种是自底向上。我们分别来看看。
预剪枝
预剪枝其实你可以想象成是一种自顶向下的方法。在构建过程中,我们会设定一个高度,当达构建的树达到那个高度的时候呢,我们就停止建立决策树,这就是预剪枝的基本原理。
后剪枝
后剪枝呢,其实就是一种自底向上的方法。它会先任由决策树构建完成,构建完成后呢,就会从底部开始,判断哪些枝干是应该剪掉的。
注意到预剪枝和后剪枝的最大区别没有,预剪枝是提前停止,而后剪枝是让决策树构建完成的,所以从性能上说,预剪枝是会更块一些,后剪枝呢则可以更加精确。
3.决策树算法演变:
ID3决策树不足
用ID3算法来构建决策树固然比较简单,但这个算法却有一个问题,ID3构建的决策树会偏袒取值较多的属性。为什么会有这种现象呢?还是举上面的例子,假如我们加入了一个属性,日期。一年有365天,如果我们真的以这个属性作为划分依据的话,那么每一天会不会赖床的结果就会很清晰,因为每一天的样本很少,会显得一目了然。这样一来信息增益会很大,但会出现上面说的过拟合情况,你觉得这种情况可以泛化到其他情况吗?显然是不行的!
C4.5决策树
针对ID3决策树的这个问题,提出了另一种算法C4.5构建决策树。
C4.5决策树中引入了一个新的概念,之前不是用信息增益来选哪个属性来作为枝干嘛,现在我们用增益率来选!

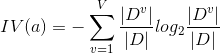
这里面,IV(a)这个,当属性可选的值越多(比如一年可取365个日期)的时候,它的值越大。
而IV(a)值越大,增益率显然更小,这就出现新问题了。C4.5决策树跟ID3决策树反过来,它更偏袒属性可选值少的属性。这就很麻烦了,那么有没有一种更加公正客观的决策树算法呢?有的!!
CART 决策树
上面说到,ID3决策树用信息增益作为属性选取,C4.5用增益率作为属性选取。但它们都有各自的缺陷,所以最终提出了CART,目前sklearn中用到的决策树算法也是CART。CART决策树用的是另一个东西作为属性选取的标准,那就是基尼系数。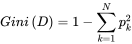
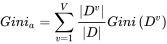
第一条公式中pk表示的是每个属性的可选值,将这些可选值计算后累加。这条公式和信息增益的结果其实是类似的,当属性分布越平均,也就是信息越模糊的时候,基尼系数值会更大,反之则更小。但这种计算方法,每次都只用二分分类的方式进行计算。比如说上面例子中的季节属性,有春夏秋冬四个可选值(春,夏,秋,冬)。那么计算春季的时候就会按二分的方式计算(春,(夏,秋,冬))。而后面其他步骤与ID3类似。通过这种计算,可以较好得规避ID3决策树的缺陷。
使用CART决策树的好处是可以用它来进行回归和分类处理
4.实例和可视化:
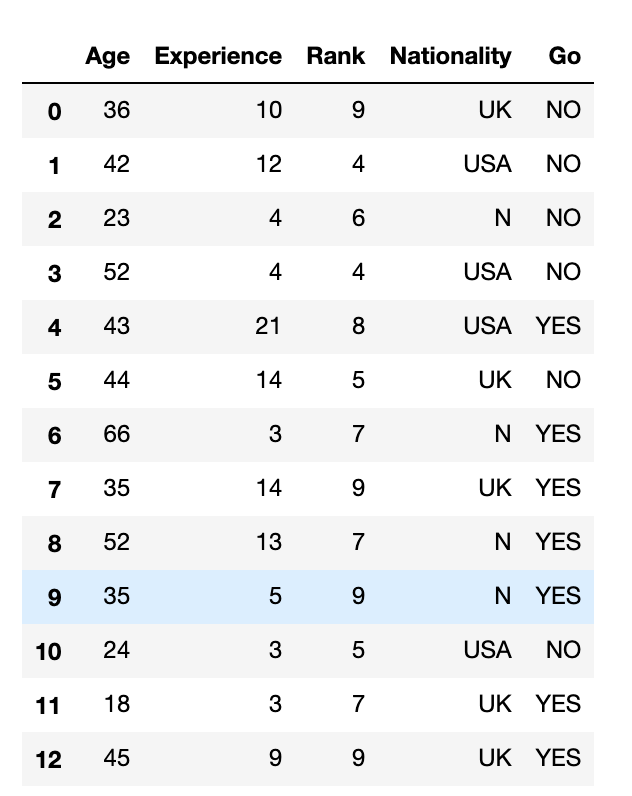
利用sklearn实例化一个决策树,调参决策树模型的各个参数,并且使用sklearn模型对上一节中的例子训练出一个决策树模型,然后用Graphviz让决策树模型可视化。
dataset如图
代码处理如图:

$ dot out.dot -T pdf -o out.pdf
得到最后可视化的dtree.
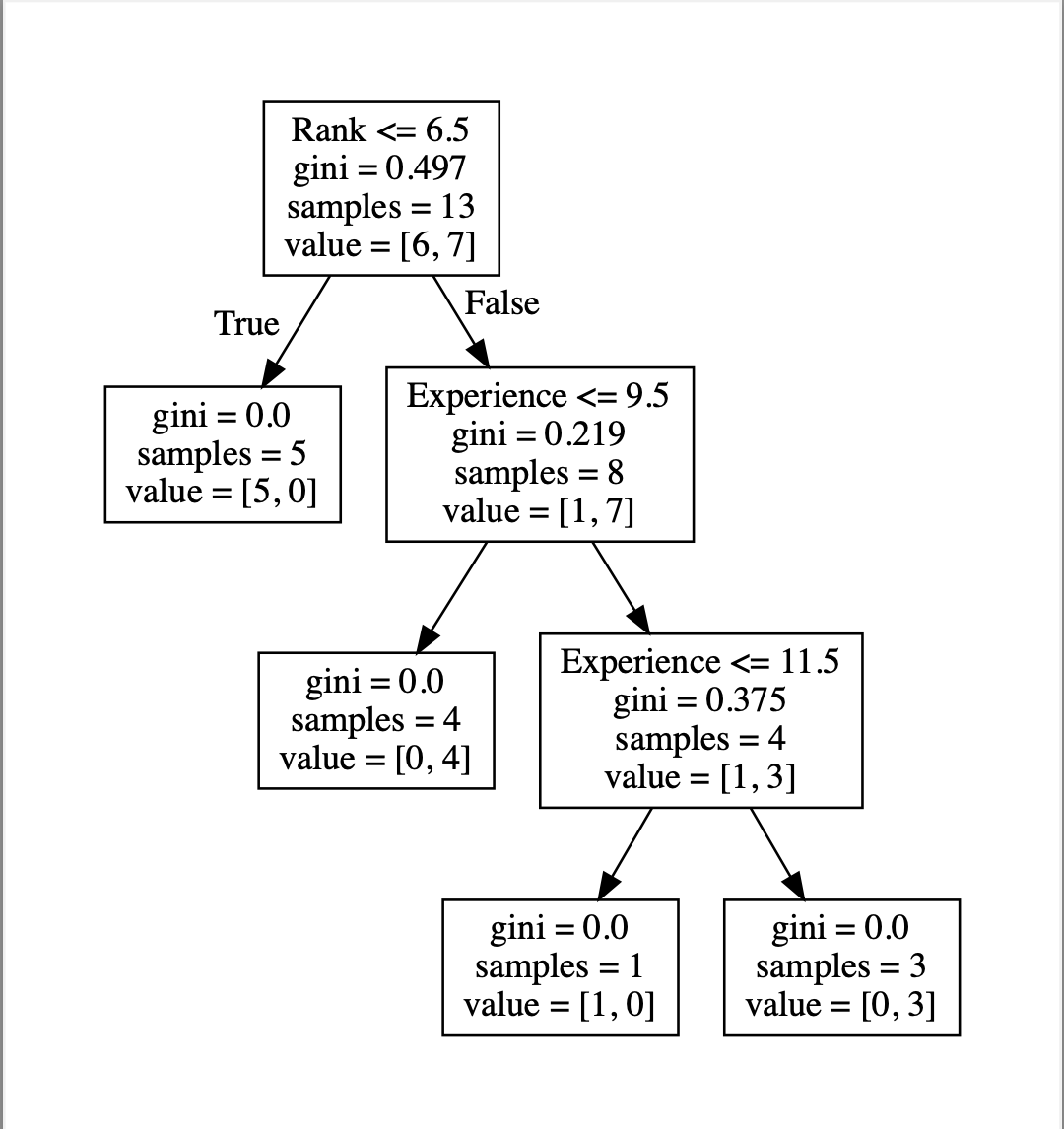
预测

4.个人感悟:
决策树基于gini系数进行生成,调节节点深度,形成最短树,避免过拟合,结果生成不唯一。
(部分转录,FYI)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号