HDU-5927 Auxiliary Set 树形dp(暂定)(反正是dp)
Auxiliary Set
Time Limit: 9000/4500 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)
Total Submission(s): 1054 Accepted Submission(s): 330
Problem Description
Given a rooted tree with n vertices, some of the vertices are important.
An auxiliary set is a set containing vertices satisfying at least one of the two conditions:
∙It is an important vertex
∙It is the least common ancestor of two different important vertices.
You are given a tree with n vertices (1 is the root) and q queries.
Each query is a set of nodes which indicates the unimportant vertices in the tree. Answer the size (i.e. number of vertices) of the auxiliary set for each query.
Input
The first line contains only one integer T (T≤1000), which indicates the number of test cases.
For each test case, the first line contains two integers n (1≤n≤100000), q (0≤q≤100000).
In the following n -1 lines, the i-th line contains two integers ui,vi(1≤ui,vi≤n) indicating there is an edge between uii and vi in the tree.
In the next q lines, the i-th line first comes with an integer mi(1≤mi≤100000) indicating the number of vertices in the query set.Then comes with mi different integers, indicating the nodes in the query set.
It is guaranteed that ∑qi=1mi≤100000.
It is also guaranteed that the number of test cases in which n≥1000 or ∑qi=1mi≥1000 is no more than 10.
Output
For each test case, first output one line "Case #x:", where x is the case number (starting from 1).
Then q lines follow, i-th line contains an integer indicating the size of the auxiliary set for each query.
Sample Input
1 6 3 6 4 2 5 5 4 1 5 5 3 3 1 2 3 1 5 3 3 1 4
Sample Output
Case #1: 3 6 3
Hint
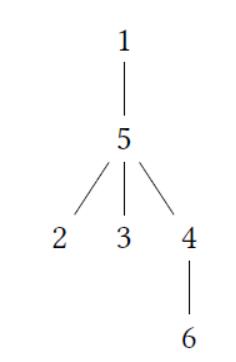 For the query {1,2, 3}:
•node 4, 5, 6 are important nodes For the query {5}:
•node 1,2, 3, 4, 6 are important nodes
•node 5 is the lea of node 4 and node 3 For the query {3, 1,4}:
•node 2, 5, 6 are important nodes
For the query {1,2, 3}:
•node 4, 5, 6 are important nodes For the query {5}:
•node 1,2, 3, 4, 6 are important nodes
•node 5 is the lea of node 4 and node 3 For the query {3, 1,4}:
•node 2, 5, 6 are important nodes
————————————随便写写——————————————
这道题看懂了就有了一个大概的思路,给出了不重要的点(以下简称um点)那剩下的自然就是重要的点(m点),然后继续推论,既然一个um点,如果是两个m点的lca的话,那就可以被归入到AS集。那么如果一个um点是两个及以上已被归入AS点集的um点(称为umas点)的lca的时候,那它必然可以被加入AS集,因为两个下辖的umas点必然有m点后代,而在这个um点出现之前他们是不能在图上联通的。
然后继续推理,那怎么样把之前点的判断结果用到后面点的判断中去,那结果就是把给的um点集按深度从大到小排列并判断,因为深度越小,越可能用到之前的判断,反之则行不通。
但是这个想法仍然对于每一个样例的一个um集需要用O(n)的时间来进行判定,所以估计比赛的时候就算是实现了也会tle。
然后看别人的标程的时候发现了一个非常巧妙的实现:
该实现基于以下前提:
一个点如果不是um点的话,那么就是m点
一个um点是叶节点的话,那么不能归到AS集中
然后通过这两个前提,就可以想出如下的解决方案:
对于一个点,如果是um点,且其有效子节点为0,则其父节点的有效子节点减1(因为这棵子树必然没有m点)
如果一个点的有效子节点数大于等于2,且所有的子节点已经被遍历,则其可被归入AS集。
这样子做有一个好处,即是没有检查m点,而是默认他们已存在,然后对于不符合要求的um点进行排除。
和上面提到的方法类似,子节点被遍历这个条件可以通过按深度一一处理um点即可,因为剩下的都是m点,是被默认存在的,如此一来,时间复杂度既是O(um点的数量)
代码实现中值得一提的是,因为要多次使用原数据,不能修改原数据,但是也不能在处理一个给出的um集的时候把原数据整个复制过来,因为这样就是O(n)时间。
处理方法:
1 我参考的代码:
用一个名为SON的数组存储这个要处理的um集的子树数量,更新的时候,如果更新到的父节点是um点,那这就是我们要做的事情,如果更新到的是m点,那反正m点的数据也不会被调用。而由于下次迭代的时候下一次um点的数据会直接覆盖,所以没有关系。
2 我的做法:
用map来存储需要用到的数据,调用的时候先查询map里该目录值,如果没有,则从原数据里加入后处理,如果有,则直接处理。
————————————参考代码——————————————
![]()
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<vector>
#include<algorithm>
#include<string>
#include<queue>
#include<climits>
#include<map>
#define file_in freopen("input.txt","r",stdin)
#define MAX 100005
#define math 1000
#define ll long long
using namespace std;
struct node {
int fa;
int son = 0;
vector<int>child;
};
int depp[MAX], SON[MAX];
int cmp(int a, int b)
{
return depp[a] > depp[b];
}
void dfs(int cur, int fa,int dep, vector<node>&tre, vector<vector<int>>&sto)
{
depp[cur] = dep;
tre[cur].fa = fa;
for (int i = 0; i < sto[cur].size(); i++)
if (sto[cur][i] != fa)
{
tre[cur].child.push_back(sto[cur][i]);
tre[cur].son++;
dfs(sto[cur][i],cur, dep + 1, tre, sto);
}
}
int main(void)
{
//file_in;
int num;
scanf("%d", &num);
for (int i = 0; i < num; i++)
{
printf("Case #%d:\n", i + 1);
int n, q;
scanf("%d %d", &n, &q);
vector<vector<int>>sto(n+5);
for (int i = 0; i < n - 1; i++)
{
int a, b;
scanf("%d %d", &a, &b);
sto[a].push_back(b);
sto[b].push_back(a);
}
vector<node>tre(n+5);
dfs(1,0,1,tre,sto);
while (q--)
{
int m,ans;
scanf("%d", &m);
ans = n - m;
vector<int>che(m);
for (int i = 0; i < m; i++)
scanf("%d", &che[i]);
sort(che.begin(), che.end(), cmp);
for (int i = 0; i < m; i++)
SON[che[i]] = tre[che[i]].son;
for (int i = 0; i < m; i++)
{
if (SON[che[i]] >= 2)
ans++;
else if (SON[che[i]]==0)
SON[tre[che[i]].fa]--;
}
cout <<ans<<endl;
}
}
}
————————————————————————my code————————————————————————————————
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<vector>
#include<algorithm>
#include<string>
#include<queue>
#include<climits>
#include<map>
#define file_in freopen("input.txt","r",stdin)
#define MAX 100005
#define math 1000
#define ll long long
using namespace std;
struct node {
int fa;
int son = 0;
vector<int>child;
};
int depp[MAX];
int cmp(int a, int b)
{
return depp[a] > depp[b];
}
void dfs(int cur, int fa,int dep, vector<node>&tre, vector<vector<int>>&sto)
{
depp[cur] = dep;
tre[cur].fa = fa;
for (int i = 0; i < sto[cur].size(); i++)
if (sto[cur][i] != fa)
{
tre[cur].child.push_back(sto[cur][i]);
tre[cur].son++;
dfs(sto[cur][i],cur, dep + 1, tre, sto);
}
}
int main(void)
{
//file_in;
int num;
scanf("%d", &num);
for (int i = 0; i < num; i++)
{
printf("Case #%d:\n", i + 1);
int n, q;
scanf("%d %d", &n, &q);
vector<vector<int>>sto(n+5);
for (int i = 0; i < n - 1; i++)
{
int a, b;
scanf("%d %d", &a, &b);
sto[a].push_back(b);
sto[b].push_back(a);
}
vector<node>tre(n+5);
dfs(1,0,1,tre,sto);
while (q--)
{
int m,ans;
scanf("%d", &m);
ans = n - m;
vector<int>che(m);
for (int i = 0; i < m; i++)
scanf("%d", &che[i]);
sort(che.begin(), che.end(), cmp);
map<int,int>SON;
for (int i = 0; i < m; i++)
{
if (SON.find(che[i]) == SON.end())
SON[che[i]] = tre[che[i]].son;
if (SON[che[i]] >= 2)
ans++;
else if(SON[che[i]]==0)
{
if (SON.find(tre[che[i]].fa) == SON.end())
SON[tre[che[i]].fa] = tre[tre[che[i]].fa].son;
SON[tre[che[i]].fa]--;
}
}
printf("%d\n",ans);
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号