.net 大型分布式电子商务架构说明
2015-10-28 10:08 stulife 阅读(7875) 评论(1) 收藏 举报
背景
构建具备高可用,高扩展性,高性能,能承载高并发,大流量的分布式电子商务平台,支持用户,订单,采购,物流,配送,财务等多个项目的协作,便于后续运营报表,分析,便于运维及监控。
架构演变
基础框架剥离 -> 分库分表 -> 基础服务建设 -> 私有云建设 ->分布式操作系统
基础框架
整个公司无论有多少项目,需要沉淀最基础的框架,里面一般包含核心的分库分表规则,统一的数据库操作类库,统一的通讯类,统一的日志类,统一的加密算法,统一的基础服务sdk,公用的一些工具类等等。该框架用于定义最基础的公司架构,设计,统一最基础的技术及项目架构规范,拦截及监控最基础的核心调用等。框架命名一般比较简单,如京东,可以定义为jdf;淘宝,可以定义为tbf。
分库分表
分库分表为最常规的架构拆分方案。一般会从业务角度进行不同视角的拆分,如用户视角和商户视角。当然前提也需要业务方面或者其他技术力量的支持,不出现或者解决拆分后跨多个分库或者分表的表查询及查询结果合并问题。分库分表前也通过需要预估容量,预估性能。分库分表也经常会遇到全局id,或者分布式id自增且唯一的问题,这些都要预先在设计和架构层面要充分考虑。
用户视角如图所示
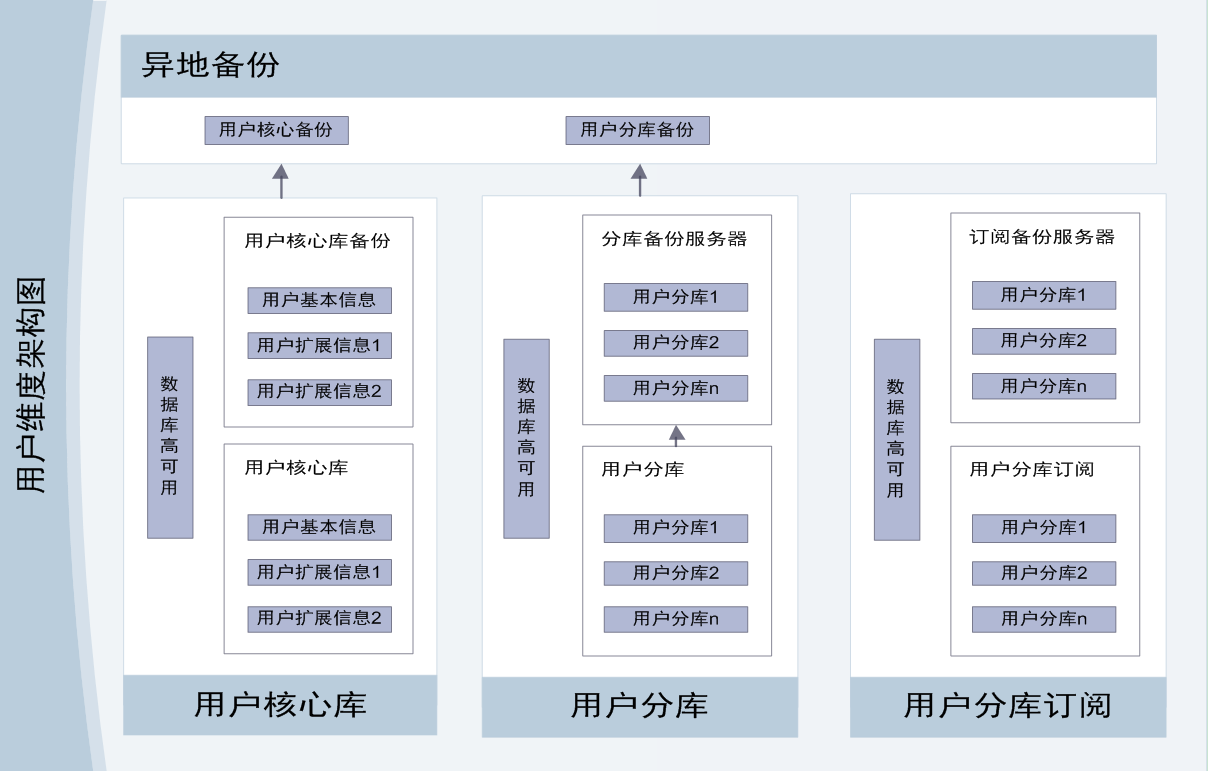
商户视角如图所示
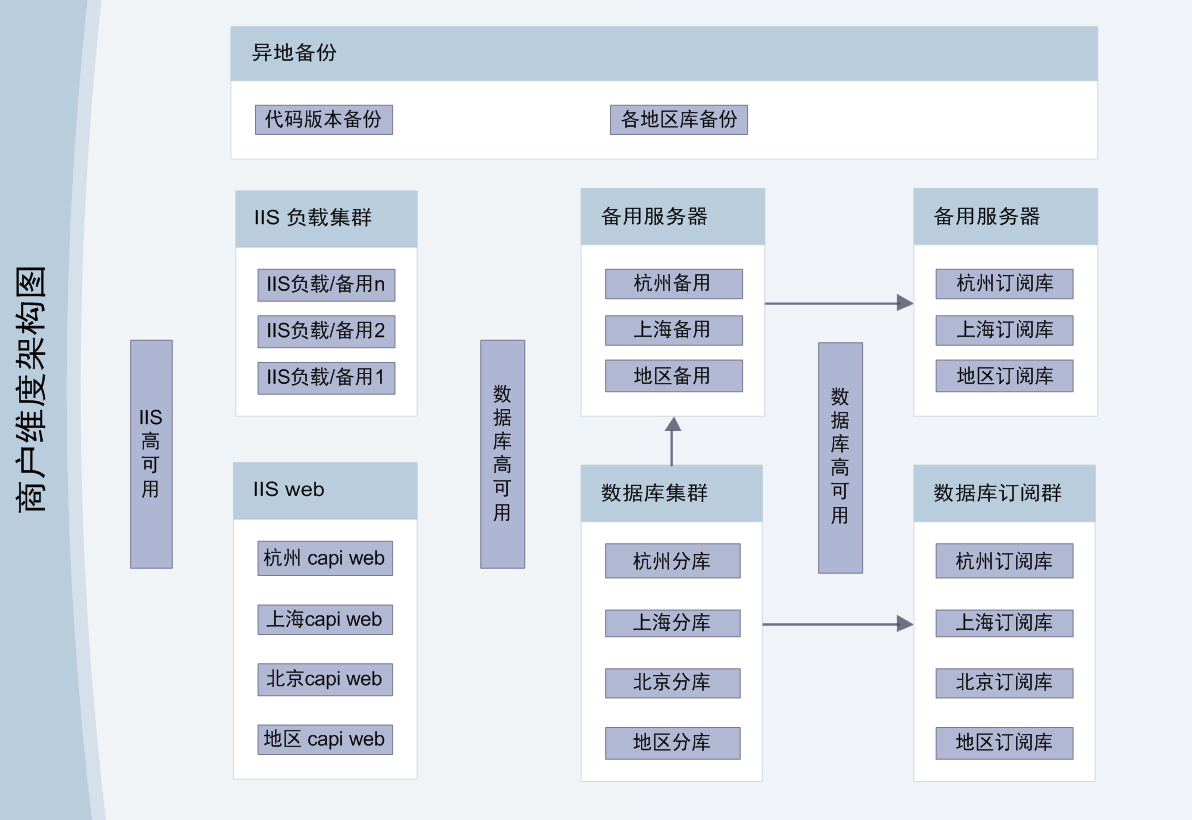
基础服务
基础服务是系统分布式的一个核心。它往往与操作系统基础组件相对应,只不过它是分布式的。如基础服务一般包含分布式存储,分布式缓存,分布式计算,分布式消息,分布式服务,分布式任务调度,分布式监控等。对应于操作系统的磁盘,内存,cpu,跨进行消息,进程,计划任务,系统监控等。
公司的基础服务暂时包含几块: 分布式缓存,业务消息队列,任务调度,监控平台,服务中心,分布式锁服务,配置中心。
基础服务如图所示

分布式缓存(暂未开源)
目前主要是解决核心几个页面的缓存问题,比如首页和列表页等,从而解决高频繁下频繁查询数据库的问题。一般来说缓存的内容越细越好,这样缓存的内容会比较多,对数据库的性能优化效果自然很佳。但是缓存越细,则关于缓存的清理工作就越细致,很容易代码编写过程中忘记清理缓存的情况,影响面和用户体验会很糟糕。
这种情况可能有两种方式解决,一种是架构上已经达到服务化和模块化层面,每个模块只处理自身相关的缓存。如用户服务,订单服务,商户服务,商品服务等,仅处理自身相关的缓存。那么缓存足够细,当然代码处理也能更加细致。另外一种是数据库或者其他层面的修改回调,批量清除相关的缓存;因为粒度很粗,但是可能会出现大量可用缓存被清理,造成部分雪崩效应。
所以我们经常会认为使用缓存很容易,但是用好缓存需要的是根据业务需求和许可设计缓存结构,尽量用好缓存,达到理想的性能;又或者我们只使用少量粗粒度的缓存,定义好缓存失效时间,部分代码清理部分缓存的方式来,这样能保证热点页面的较高性能; 但是这种情况下我们依然要注意缓存项不能太多,代码规范管理。
同时我们注意到业务的缓存会有一些特点,有些缓存具备高热点特性,有些缓存具备瞬间热点特性,有些缓存可以丢失,有些缓存尽量保证不丢失(否则可能造成雪崩效应)。故我们要根据实际业务不同,采用不同的存储介质。比如redis,memcache,ssdb等,应用场景都略微不同。而做为公司级的缓存中间件,应该适当的屏蔽这些存储特性,最好可以做到无缝配置,同时具备负载均衡,性能监控等等。
业务消息队列(开源地址: http://git.oschina.net/chejiangyi/Dyd.BusinessMQ 博文:http://my.oschina.net/u/2379842/blog/515860)
主要是解决业务间的高可靠性消息传递,及功能的异步化处理。这种消息队列必须有以下几点:承载高并发,业务消息不允许丢失,业务消息必须能支撑超大量的堆积而稳定,支持消息的回溯。一般公司可能会考虑企业服务总线(esb),但是针对电子商务瞬间高并发和大量消息堆积的需求,可能不太合适,而且esb包含的东西很多,属于重量级的解决方案,更适合一般企业项目,如企业的内部管理系统。当然一些公司可能也会使用activemq,rabbitmq,kafka,metaq,tbnotify等等,具体的会根据使用场景和实际业务需求选择。比如一些内存的消息中间件,不支持持久化,不支持消息堆积,不支持消息回溯,其实不适合当前公司的业务场景,故而放弃或者部分场景使用。
任务调度平台(开源地址:http://git.oschina.net/chejiangyi/Dyd.BaseService.TaskManager 博文:http://my.oschina.net/u/2379842/blog/484635)
主要是解决业务的后端任务挂载,隔离,定时调度,任务出错报警等。未来可以做到父子任务的关联,任务资源的自动分配和协调,任务的故障转移和均衡。那么网络爬虫,报表分析,弹性计算等资源型任务就可以适用了。
统一监控平台(开源地址:http://git.oschina.net/chejiangyi/Dyd.BaseService.Monitor 博文:http://my.oschina.net/u/2379842/blog/510655)
每个公司对监控的需求其实都不一样,一般会根据业务不同,根据架构不同,根据基础服务不同,会不同程度的抓取和集成一些性能指标,业务日志,错误日志,耗时性能,流量等等至监控平台。市面上有很多大而全的监控平台,其实也都提供了sdk做二次开发,目的也在于此。
毕竟业务不同,服务器环境不同,架构基础设施不同,自然关注的性能点和指标参数也都不一样,故从长远发展,监控平台对整个分布式系统的稳定性是具备关键性作用。大型的分布式电子商务系统,监控平台本身就是大量系统性能分析师的分析思路,分析技巧的总结和沉淀。当然中小型的企业,可以直接使用第三方监控工具,但是性能分析往往是事后的,非及时性的;又或者第三方的监控工具很多,却没有有效的整合在一起,真正分析性能的时候却一片茫然。又或者大型项目单个操作涉及的系统或服务很多,需要拿到分布式的调用堆栈和调用链…. 种种这些都难免需要公司沉淀自己的监控平台。
服务中心(暂未开源)
主要是解决多个项目之间的同步调用,项目的公用api下沉,及远程调用服务的负载均衡,性能监控,预警等等。当前其本质上是服务的管理,公开,协调,运维等,满足业务soa的架构设计。特别是未来对业务细化拆分,模块化,同步解耦起关键作用,类似淘宝的HSF。
分布式锁(开源地址:http://git.oschina.net/chejiangyi/XXF.BaseService.DistributedLock 博文:http://my.oschina.net/u/2379842/blog/511291)
分布式锁服务的应用即便在大型业务项目中都不应该经常使用,特别是对性能要求较高的功能,不建议使用或谨慎使用。任何使用分布式锁的功能建议进行codereview和使用论证。理论上分布式锁常用于基础设施服务的分布式协调,但是一些业务对一致性要求较高,特别对瞬间并发导致相同业务同时执行的要求特别高,需要采用分布式锁,否则不采用。
配置中心(暂未开源)
主要是解决多项目之间的配置聚合及统一管理,同时具备配置的及时更新。若集成任务调度服务可以做到配置的负载均衡和配置的故障转移等。为什么要解决公司的项目配置?公司项目从页面前端,采购,物流,配送,财务,b2b等具有多个项目,多个项目各自同样具有多个服务,多个后台任务,这些程序都互相独立,且部分需要负载均衡(未来数量将达到上千个数量)但是又经常需要公用同一套配置体系。若每个程序都配置同一个配置信息,那么未来做某个配置信息的迁移或者更新,运维和开发人员根本不知道哪里需要更新。故配置的聚集管理在大型项目中是非常有必要的。而且基于配置中心也可以实现热切换,自动故障转移,软性负载等分布式的服务管理能力。
以上这些仅仅是目前公司根据业务发展需要使用的一些基础服务,当然很多公司也会根据自身的业务需求使用分布式存储,分布式搜索引擎等,也会根据自身对基础服务的可靠性要求,稳定性要求选择不同的开源基础服务框架进行改造,或者直接使用或者二次封装。从架构师的视角,针对业务发展,要谨慎选择,又要谨慎考虑是否需要重复造轮子。
文中介绍的相关基础服务可加入开源QQ群: .net开源基础服务,238543768 一起交流心得。
私有云、混合云建设
很多创业公司初期,特别是电子商务类型的公司,可以会优先考虑第三方云计算平台来搭建整个平台和架构,自然更多的可能是基于成本,资源,人手方面考虑。但是当公司发展到一定程度,建立自己的机房可能是非常必要的选择。个人认为云计算的服务器(ecs)达到60-100台集群的时候,考虑搭建公司的机房已经非常有必要了,而当机房的物理机器达到20台的时候,可能也需要考虑放弃单纯的kvm,转而使用openstack及配合使用docker,container等容器技术会更加合适。
公司对私有云的建设主要是偏重于物理机的资源合理利用,及私有云的有效,灵活管理,甚至必要的情况下,修改openstack的源代码,配合前端的流量和压力情况进行扩容和缩容,更加深层次的自动的负载均衡和自动的故障切换等等。
分布式操作系统
分布式操作系统本身是一种概念思想的,本身未必具体的如何做的执行步骤。个人认为它更偏向于在云计算平台搭建后的资源更加有效整合,及平台在解决业务能力的稳定性和扩展能力;从架构师的视角看,也许更多的站在更高的层次全局的俯视整个平台架构,一个整体的电子商务的分布式操作系统和解决方案,而非仅仅是云计算平台。在这个阶段我们可以尝试修改openstack的源码和基础服务的源码,两者无缝结合起来,做到高流量时候自动的扩容及低流量时的自动缩容,做到资源的动态调配合。
(本说明基于当前公司的实际情况的部分架构简要说明,未涉及工作流,搜索引擎,大数据挖掘等其他方面,仅作参考)
本文转自车江毅:http://my.oschina.net/u/2379842/blog/521950

 浙公网安备 33010602011771号
浙公网安备 33010602011771号