字节顺序(大端小端)
字节序
字节顺序,又称端序或尾序(英语:Endianness),在计算机科学领域中,指在电脑内存中或在数字通信链路中,组成多字节数据的排列顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如在C语言中,一个类型为int的变量x地址为0x100,那么x的四个字节将被存储在存储器的0x100 0x101 0x102 0x103位置。
大端小端
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
还有个更通俗的理解,就是,一串数字0x12345678,低位的78放在低位的内存,就是小端;低位的78放在高位的内存就是大端。
Windows和Linux在x86-64下是小端
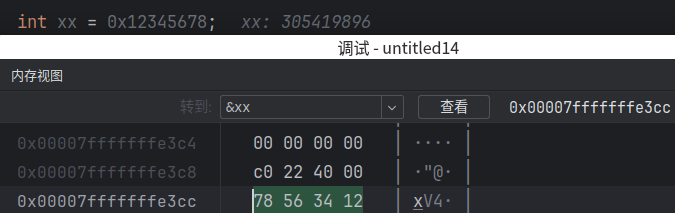
大端逻辑上是反过来的,但是小端看起来是反过来的。实际上这与我们排列内存的习惯有关,正常思维,肯定是按照从小到大展示内存,比如上面的例子,xx变量第一个地址是0x7fffffffe3cc,然后是0x7fffffffe3cd依次展示,但是书写的数字0x12345678正好反过来,我们最先看到的12是最高位,所以小端虽然逻辑上是低位数字放低地址,高位数字放高位地址,但是因为展示顺序是先低地址,感觉上反过来了。
网络字节序
网络序使用的是大端标准。对我们有什么影响呢? 如果是同一平台(网络传输双方都是大端或是小端),双方可以不用考虑大小端,直接发送接收就可以(当然这是不标准的)。因为数据发送就是发送,是一个数据流,1000发送过去,接收也是1000,数据没有变化。但是如果不同的平台,比如1000在我的平台保存序列就是0001,那么发送就是0001,接收也是0001,如果是同一平台,我认为0001就是1000,没有问题;如果是不同平台,我认为0001是1(0001),那么数据就乱了。所以网络字节序规定了一个标准,大家都按照这样存储,都按照这样转换,不同平台就可以互通了。
判断大小端
int a = 1;
if (*((char*)&a) == 1)
{
cout << "little";
}
赋值1给a,a是一个int类型,占用4个字节,如果是小端,那么1应该先放到低地址;如果是大端,那么 1应该放到高地址。(char*)&a是把a的指针强转成一个char的指针,那么默认指的位置也就是低地址,低地址的第一个字节如果保存的是1,就是小端,如果不是1,就是大端。
注意
- 字节序只是针对多个字节组合表示一个数据的情形,如果数据是char,就使用了一个字节,是不需要考虑字节序的
- 在数据传输和保存中,不管大端小端,数据都是按照字节从低位地址向高位地址存放的,也就是所有相邻的char类型数据传输,也不用考虑字节序。
上面两点需要确认清楚其不同,第一条意思是一个字节内的数据,不需要考虑字节序,比如一个字节的数据保存为1,不管是在大端还是小端,都保存在这个字节中,都是0000 0001,不会说在同一个字节中,保存数据也会反过来变成1000 0000。
第二条意思是,如果传递的是ascii这种数据,也不需要考虑字节序,比如传递的是abcd,那么不管大端还是小端都是保存为abcd,并不会不同字节间调换顺序。想想也知道,如果不同的数据之间也要按照大端小端,因为字符串长度不知,发送数据时如何反转呢?
转换函数(大小端转换)
这些函数是把本机数据从大端转化成小端,或者从小端转化成大端。
htobe16:h表示host(本机),to表示too(转化),be表示大端(big endian),16表示转换16位的数据(2字节)。
htole16:很明显le表示小端
#include <endian.h>
uint16_t htobe16(uint16_t host_16bits);
uint16_t htole16(uint16_t host_16bits);
uint16_t be16toh(uint16_t big_endian_16bits);
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint32_t htole32(uint32_t host_32bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t htobe64(uint64_t host_64bits);
uint64_t htole64(uint64_t host_64bits);
uint64_t be64toh(uint64_t big_endian_64bits);
uint64_t le64toh(uint64_t little_endian_64bits);
转换函数(网络字节序与本机字节序)
htonl:h表示host(本机),to表示too(转换),n表示network(网络),l表示long(32位数据,4字节)。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
https://zh.wikipedia.org/wiki/字节序
https://www.ruanyifeng.com/blog/2016/11/byte-order.html
https://blog.csdn.net/XiyouLinux_Kangyijie/article/details/72991235
https://linux.die.net/man/3/htobe32
https://linux.die.net/man/3/htons

 浙公网安备 33010602011771号
浙公网安备 33010602011771号