用图片理解dfs和bfs
------------恢复内容开始------------
我们常听过广搜,深搜。那么他们到底是什么呢?
深搜就是深度优先的搜索方式,简称dfs。广搜就是宽度优先的搜索方式,简称bfs。
*1.下面让我们先来看一下深度搜索,也就是dfs。
先给出最初的定义:
一dfs遍历二叉树:![]()
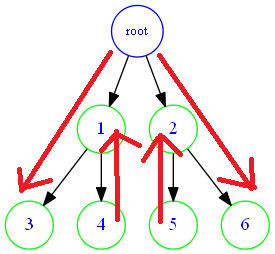
从根开始一直向下搜索,就像树根一直向下生长一样。直到搜到最底,就往回走,称为回溯。
这样我们就可以把整棵树都搜一遍。
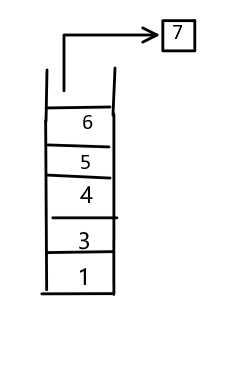
但是我们如何实现呢,这就需要先了解一下他的好搭档--栈。栈是一种存放数据的结构,遵循“先进后
出”的原则。如图:![]() 栈中原来包含1和2,现在我们把4放了进去。当我们从栈中取出来的时候,需要先把最上面的元素先取
栈中原来包含1和2,现在我们把4放了进去。当我们从栈中取出来的时候,需要先把最上面的元素先取
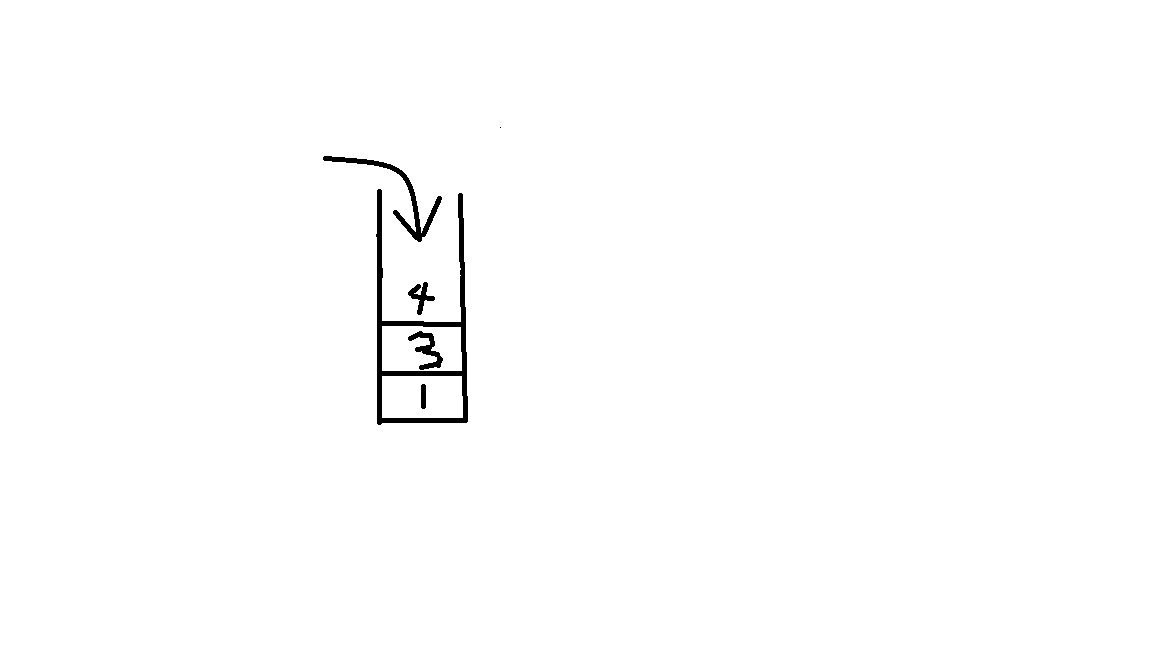 栈中原来包含1和2,现在我们把4放了进去。当我们从栈中取出来的时候,需要先把最上面的元素先取
栈中原来包含1和2,现在我们把4放了进去。当我们从栈中取出来的时候,需要先把最上面的元素先取出来,也就是先取出4。![]()
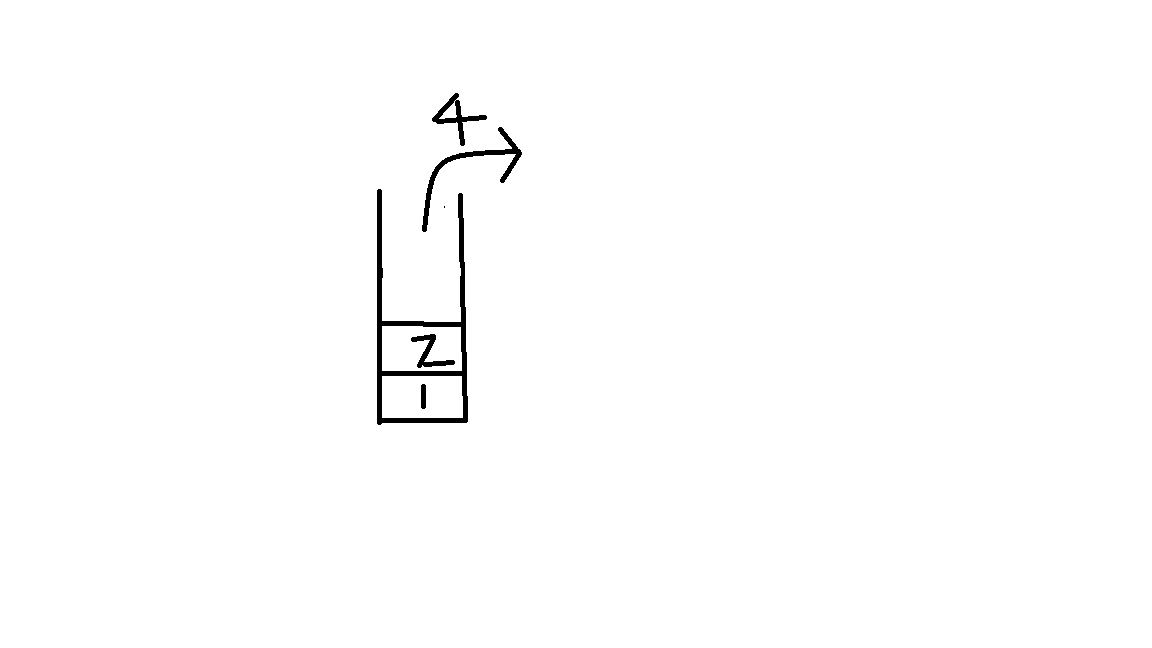
同样我们要把1取出来,就要先把2取出来。
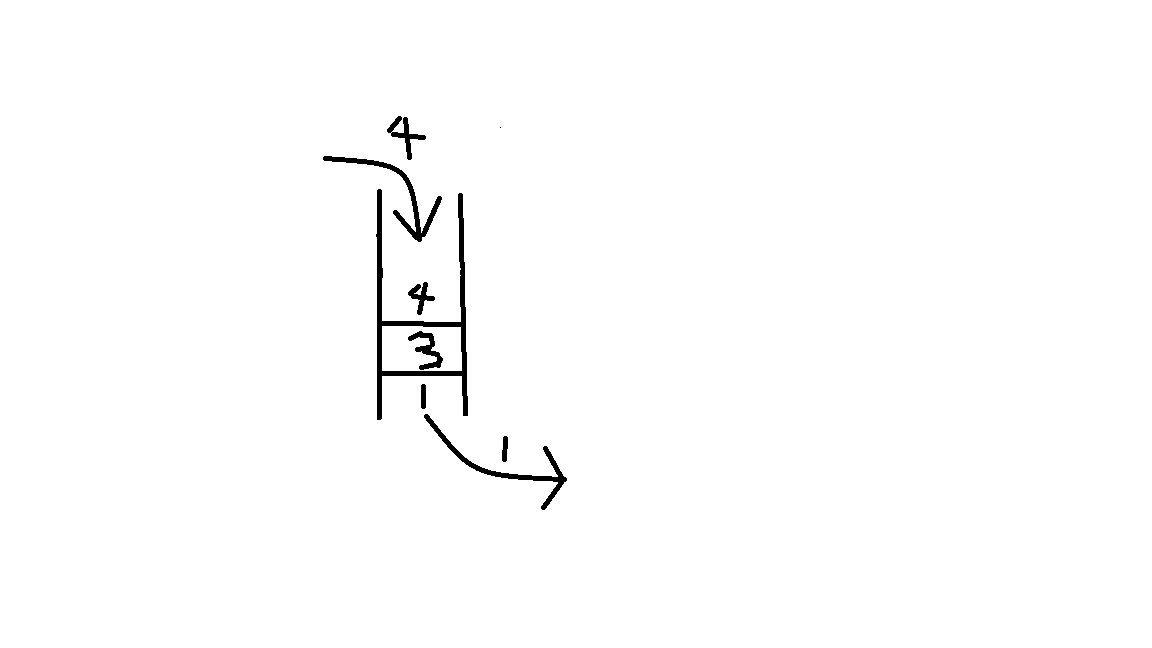
假如我们想要走一个迷宫,并走遍每个角落。从一个点出发,1,2,3,4分别记为往上,下,左,
右走。我们想走哪一步我们就先把他放进栈,走完我们就把他取出来。(这里把2放在上面是方便说
明,不必纠结),如图:![]()
最上面的是2,就是向下走的意思。下图表示我们要走迷宫的一部分(没有数字的是我们的起点):![]()
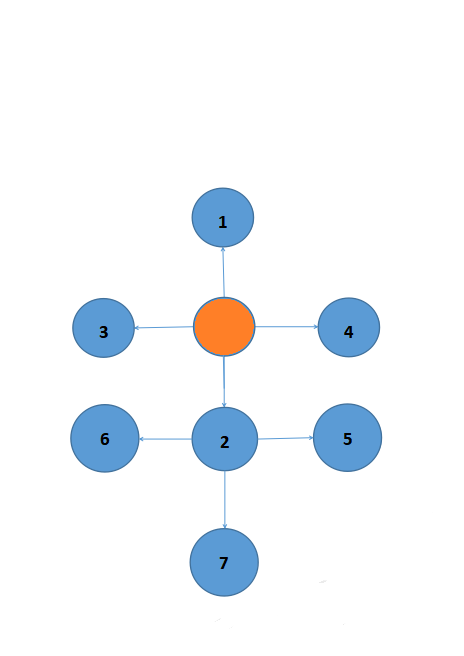
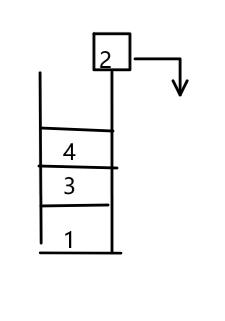
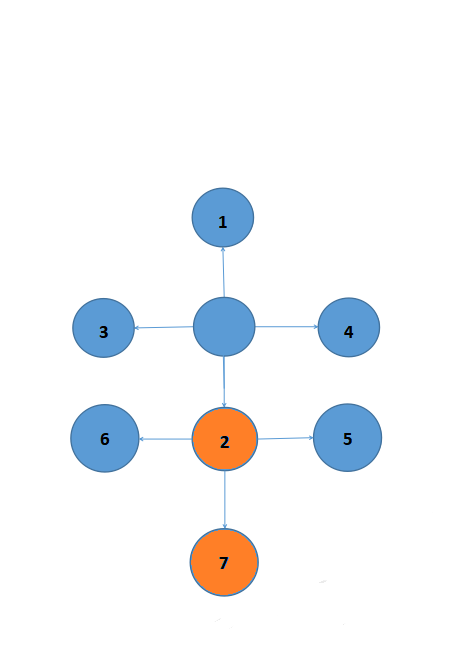
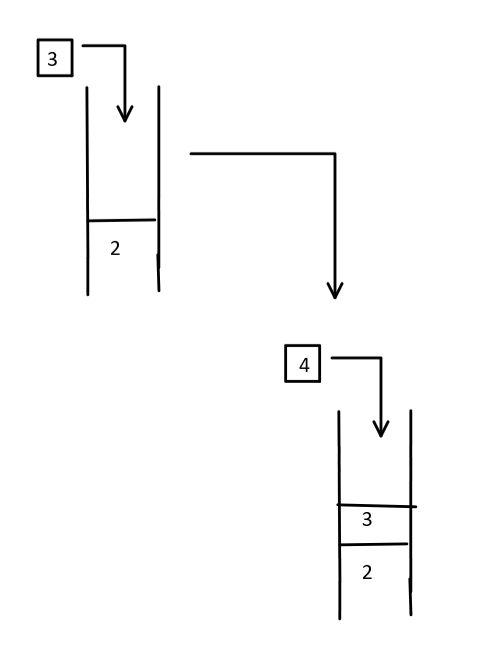
因为栈是“先进后出”的,我们要到达1,3,4这3个地点(同等于要把1,3,4取出来)。按照栈的结构,我们就要先把2取出来,即先走2这个方向。
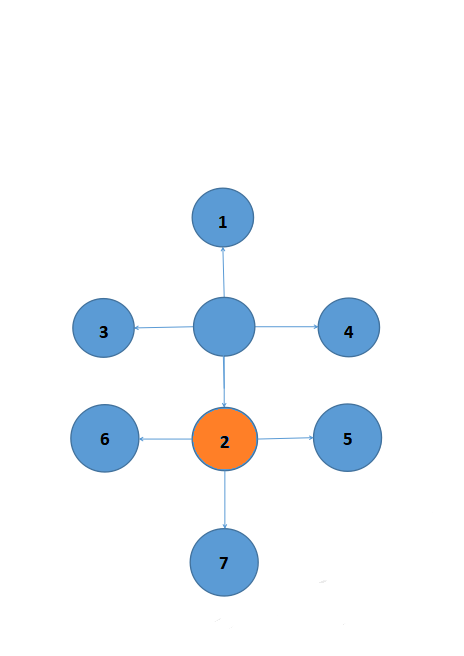
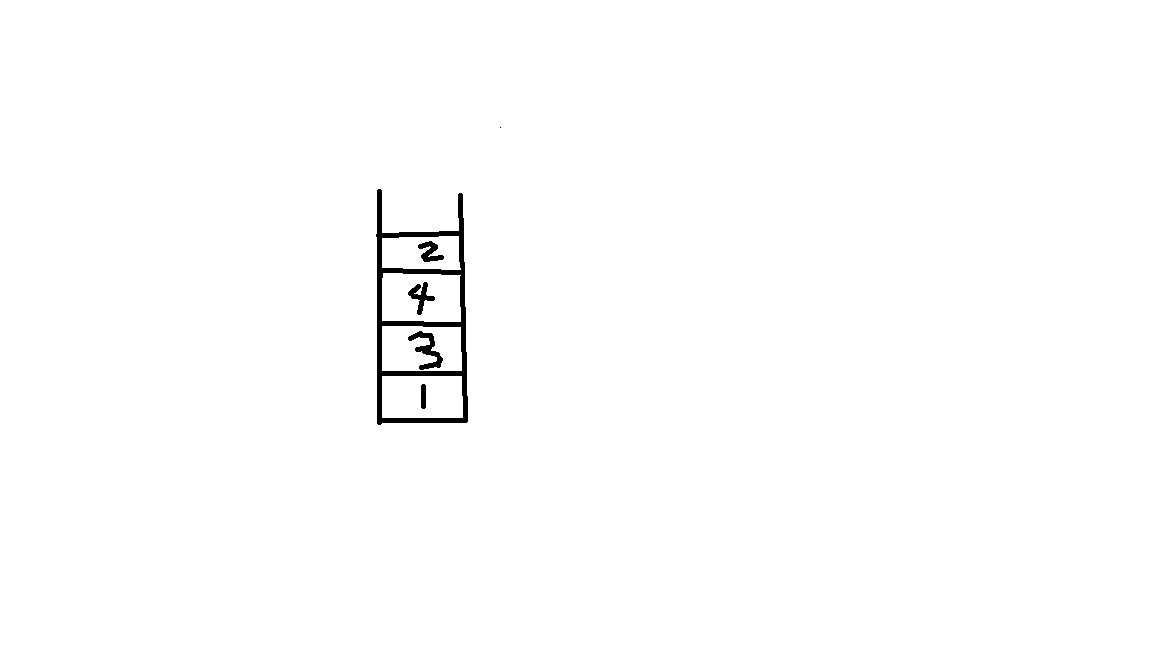
走到2之后,我们又多了5,6,7这3个新的目标。我们按上面那样,再把5,6,7放进栈中。
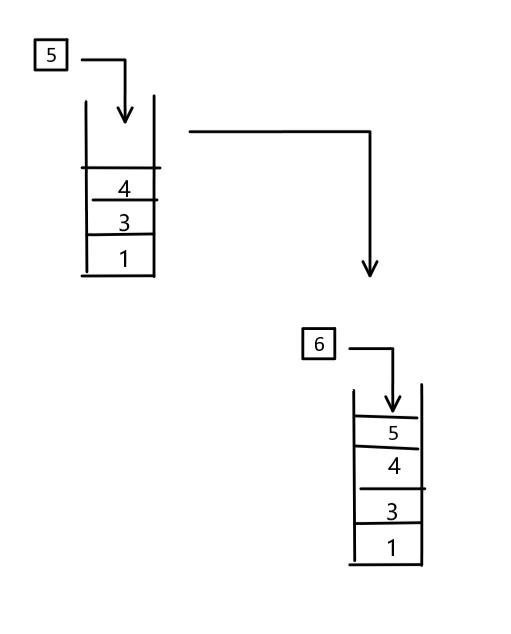
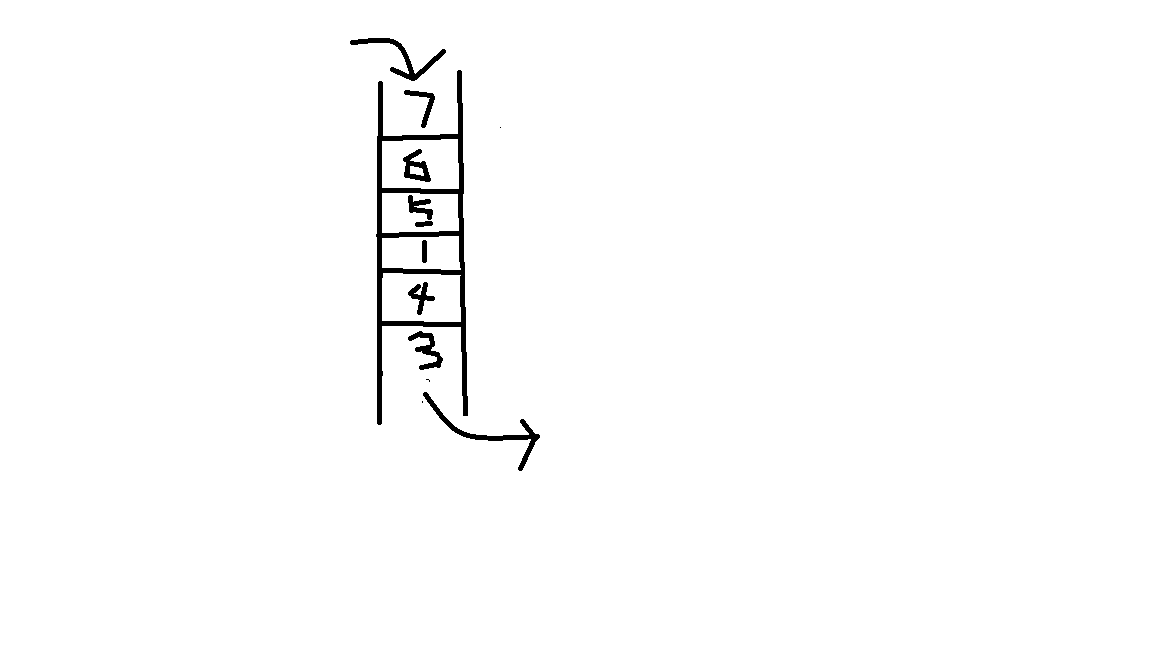
最后栈变成:
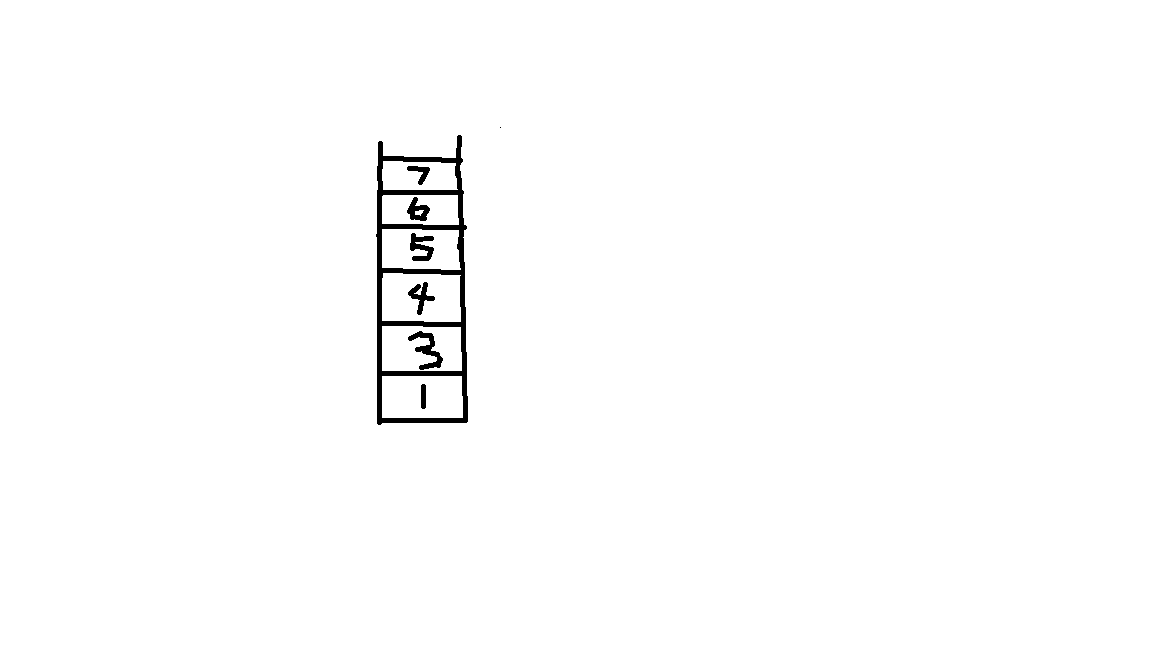
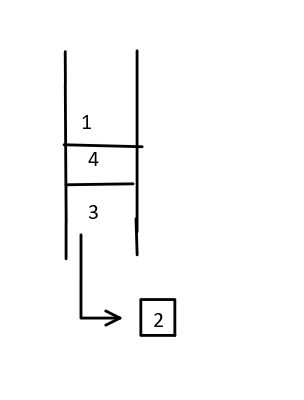
像上面那样,我们想要取出5,6,就要先取出7。
如此循环往复,我们就向下一直走,走到底。
所以dfs就像莽夫,认准一条路一直走,直到走到底。
dfs原理大致如此,具体操作我们可以使用c++里面的stack实现。(感兴趣可以百度了解一下)。还
有一种比较常用的方法,就是调用函数的递归。
下面是一个递归函数:
void func(int i){ //上部分 func(i); //下部分 }
如果我们把函数展开:
void func(int i){ //上部分 func(i){ //上部分 func(i){ //上部分 func(i){ //上部分 ......一直循环下去 //下部分 } //下部分 } //下部分 } //下部分 }
我们可以发现,递归是先把上部分内容实现完,再实现下部分内容。
结合上面的二叉树,让我们把“上部分”改为“访问左子树”,“下部分”改为“访问右子树”:
void tree(int i){ //访问1(左) tree(i){ //访问3(左) //访问4(右) } //访问1(右) }
可以看到,他和二叉树从上往下走基本一致。
*2.下面就介绍bfs--也就是我们常说的广度搜索。同样让我们看看二叉树怎么走:
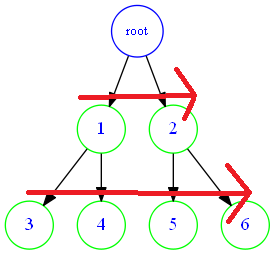
先把每一行走完,再到下一行。就是先把最近的路走了。
就像我们眼镜掉了,在地上找,肯定是要把最近的先找了。周围摸过了,再走远一点。广度搜索就是
如此。
像dfs一样,bfs也有一个好搭档。他就是队列:
队列和栈一样,也是一种存放数据的结构。不过他是遵从“先进先出”的原则。
如图,数据4从上面进,数据1从下面出。
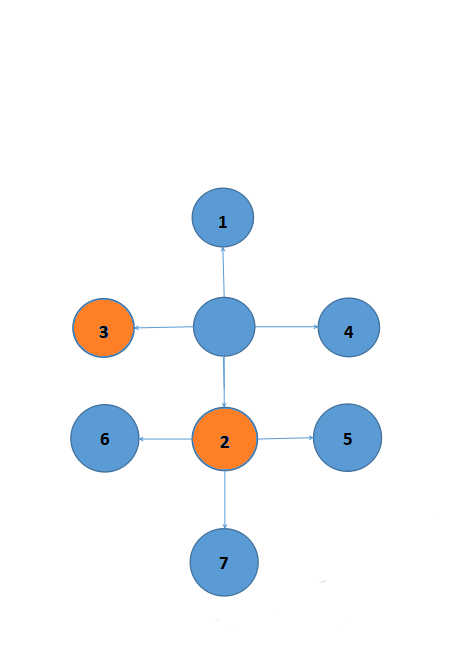
就以上面的例子为例,我的眼镜掉了,我要找到它。1,2,3,4分别代表向上,下,左,右找。同样,我们把我们的目标放进队列,找完一个地方就把对应的数字取出来。这次我们先向下找,就是(先把2放进队列,再把3,4,1依次放进队列)。
可惜2这个地方没有找到眼镜,我只能找下一处。(2没找到,把2取出来)
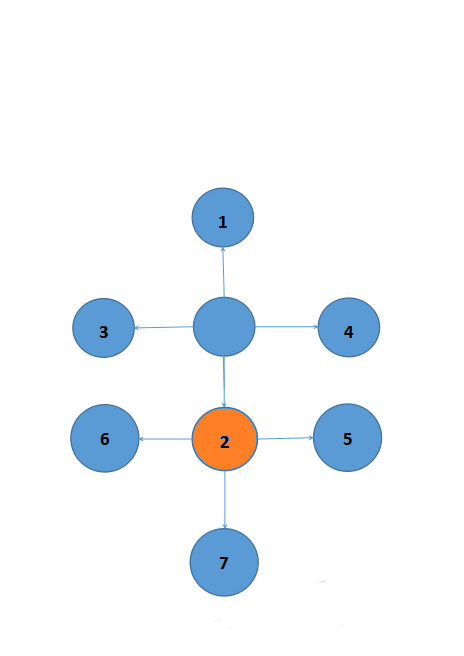
我们想在2周围再找,先把5,6,7定为我们的目标(放进队列)。
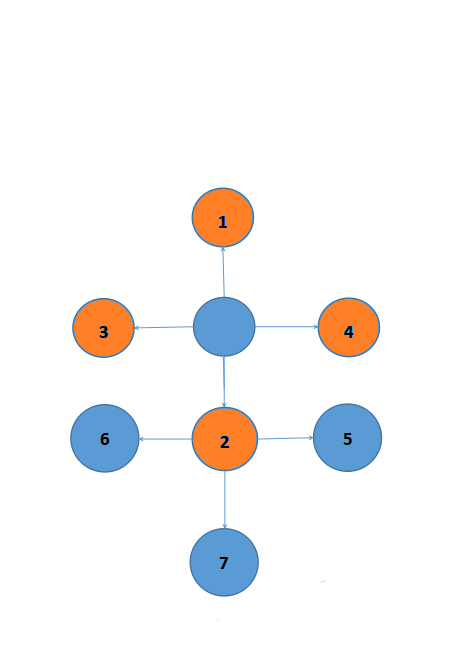
想要找5,6,7,我们就要把3先找了(先把3取出来),不然越走离眼镜越远了。
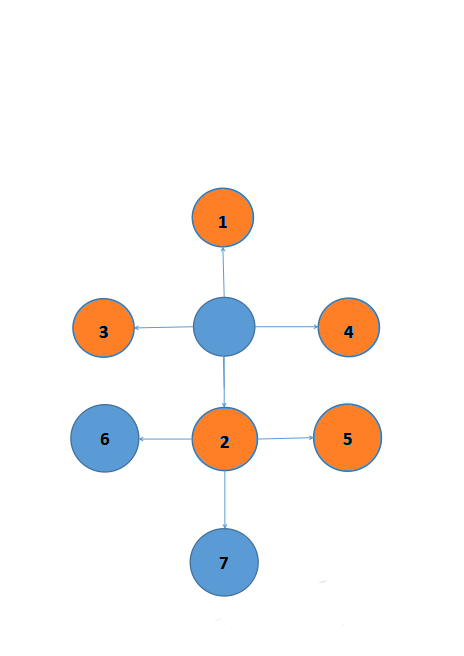
同理不断找下去,
终于我们四周都找遍了,还是没找到。只能再找5。
终于在5找到了,bfs也结束了。
实现bfs,要使用c++的队列才能实现。(接下来请自行百度)
LAST:从dfs,bfs的性质,我们可以看出,
dfs因为可以使用递归,使用比较方便,比如我要走遍迷宫的每一个角落,就可以用dfs。
再比如,我要找到迷宫最近的存档点,这时bfs就能发挥他的用处了。
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号