

Kafka 的部署(单机和集群)和 SpringBoot 访问
Kafka 由 Scala 和 Java 编写,最初由 LinkedIn 开发,后来成为 Apache 顶级项目,是一种高吞吐量的分布式发布/订阅消息系统。
Kafka 不仅仅是一个消息队列,还支持实时数据处理,其高吞吐、可扩展和持久化特性使其在大数据领域广泛应用。
本篇博客不详细介绍 Kafka,主要聚焦于 Kafka 的快速搭建和使用,在本篇博客最后会提供源代码的下载。
kafka 官网地址:https://kafka.apache.org
一、单机搭建
我的虚拟机地址是 192.168.136.128 ,已经安装好了 docker 和 docker-compose
创建 /data/kafka_single 目录,在其下面创建两个子目录 data 和 ui ,并设置 777 权限,如下所示:
编写 docker-compose.yml 文件内容如下:
version: "3.2" services: kafka: image: bitnami/kafka:latest container_name: kafka restart: always ports: - "9092:9092" volumes: - ./data:/bitnami/kafka - /etc/localtime:/etc/localtime environment: # 节点id,通常设置值都是数字 - KAFKA_CFG_NODE_ID=0 # 节点角色,因为是单机部署,所以同时承担 controller 和 broker 两个角色 - KAFKA_CFG_PROCESS_ROLES=controller,broker # 用来进行选举的 Controller 节点,如果有多个 Controller 能够参与选举,则都需要写上 - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093 # 监听的端口:9092 是提供数据服务的端口,9093 是多个 Controller 之间选举的端口 - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 # 注意,这里要配置 docker 所在的服务器 ip 地址,不是 docker 内部的 ip 地址 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.136.128:9092 # 监听器名称和安全协议之间的映射 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # 控制器使用的侦听器名称 - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER # 用于 broker 之间通信的侦听器名称 - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT kafka-ui: container_name: kafka-ui image: provectuslabs/kafka-ui:latest restart: always ports: - 9090:8080 environment: # 启用动态配置,可通过向导界面配置kafka的连接信息 - DYNAMIC_CONFIG_ENABLED=true volumes: - ./ui:/etc/kafkaui
然后在 docker-compose.yml 文件所在目录运行 docker-compose up -d 启动服务即可。
我们部署了 KafkaUI 的 Web 可视化界面,根据上面的 yml 配置,访问 http://192.168.136.128:9090 即可。
对于 Kafka 的参数配置,可以参考官网介绍:https://kafka.apache.org/documentation/#brokerconfigs
对于 Broker 的配置项,比如从官网上看到一个配置 auto.create.topics.enable,将点(.)修改为下划线(_),然后在其前面加上 kafka_cfg 前缀,最后全部改为大写字母即可作为 docker 的环境变量进行配置,即 KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true,该配置项表示在使用 Kafka 收发消息时,如果 Topics 不存在,是否自动创建 Topics,官方默认配置就是 true。
对于 KafkaUI 来说,使用起来非常简单,这里就不做详细介绍,其官网地址是:https://docs.kafka-ui.provectus.io
这里也推荐一款客户端工具 OffsetExplorer(之前名称是 KafkaTool),使用起来也很方便,其官网地址是:https://www.kafkatool.com
二、集群部署
这里在一台虚拟机上,使用不同的端口部署 3 个 Kafka 节点,作为集群部署的演示。
创建 /data/kafka_cluster 目录,在其下面创建相关的子目录 ,并设置 777 权限,如下所示:
编写 docker-compose.yml 文件内容如下:
version: "3.2" services: kafka-1: container_name: kafka-1 image: bitnami/kafka:latest restart: always ports: - "9091:9091" environment: # KRaft settings - KAFKA_CFG_NODE_ID=0 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9099,1@kafka-2:9099,2@kafka-3:9099 - KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv # Listeners - KAFKA_CFG_LISTENERS=PLAINTEXT://:9091,CONTROLLER://:9099 # 注意:这里需要配置成 docker 所在的服务器的 ip 地址 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.136.128:9091 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT volumes: - ./data1:/bitnami/kafka - /etc/localtime:/etc/localtime kafka-2: container_name: kafka-2 image: bitnami/kafka:latest restart: always ports: - "9092:9092" environment: # KRaft settings - KAFKA_CFG_NODE_ID=1 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9099,1@kafka-2:9099,2@kafka-3:9099 - KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv # Listeners - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9099 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.136.128:9092 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT volumes: - ./data2:/bitnami/kafka - /etc/localtime:/etc/localtime kafka-3: container_name: kafka-3 image: bitnami/kafka:latest restart: always ports: - "9093:9093" environment: # KRaft settings - KAFKA_CFG_NODE_ID=2 - KAFKA_CFG_PROCESS_ROLES=controller,broker - KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka-1:9099,1@kafka-2:9099,2@kafka-3:9099 - KAFKA_KRAFT_CLUSTER_ID=abcdefghijklmnopqrstuv # Listeners - KAFKA_CFG_LISTENERS=PLAINTEXT://:9093,CONTROLLER://:9099 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.136.128:9093 - KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT volumes: - ./data3:/bitnami/kafka - /etc/localtime:/etc/localtime kafka-ui: container_name: kafka-ui image: provectuslabs/kafka-ui:latest restart: always ports: - 9090:8080 environment: - DYNAMIC_CONFIG_ENABLED=true volumes: - ./ui:/etc/kafkaui
然后在 docker-compose.yml 文件所在目录运行 docker-compose up -d 启动服务即可。
三、SpringBoot 收发消息
新建一个名称为 springboot_kafka 的 springboot 工程,里面包含 2 个子工程:kafka_producer 和 kafka_consumer
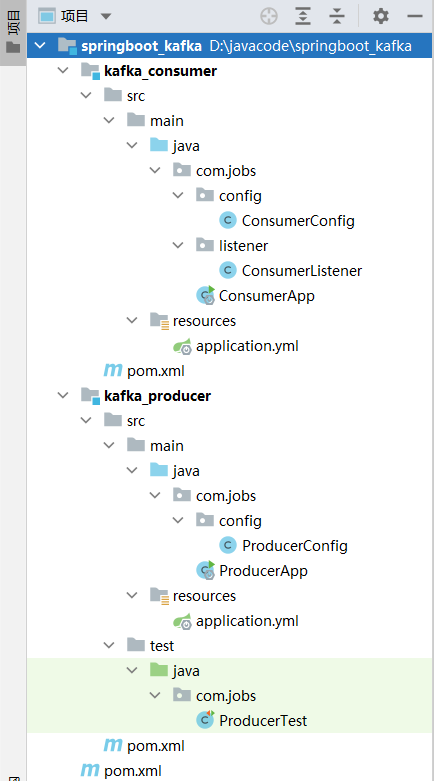
kafka_producer 是生产者,向 kafka 发送消息
kafka_consumer 是消费者,从 kafka 拉取消息进行处理
两个子工程的 pom 文件没有引用依赖包,全部继承使用父工程 pom 文件的依赖包,父工程 pom 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.jobs</groupId> <artifactId>springboot_kafka</artifactId> <version>1.0</version> <modules> <module>kafka_producer</module> <module>kafka_consumer</module> </modules> <packaging>pom</packaging> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.4.5</version> </parent> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> </dependency> <!--springboot 自带 kafka 依赖,引入该依赖包即可--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> </dependencies> </project>
Kafka_producer 生产者发送消息
kafka_producer 生产者,其 application.yml 配置文件内容如下:
spring: kafka: # kafka 服务器连接地址和端口,多个服务器之间使用英文逗号分隔 bootstrap-servers: 192.168.136.128:9092 producer: # key 和 value 使用 string 序列化和反序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer # 当遇到网络等相关问题时,最多重试 1 次 retries: 1 # 事务前缀,主要启动事务,则 ack 必须为 -1 或 all # 如果启用了事务,则其它相关方法上面,需要增加 @Transactional 注解 #transaction-id-prefix: ktx_ # acks=0 生产者在成功写入消息之前不会等待任何来自服务器的响应 # acks=1 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应 # acks= -1 或 all 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应 # 开启事务时,必须设置为 -1 或 all #acks: -1 # 有关 kafka 的相关配置内容,详见官网:https://kafka.apache.org/documentation/#configuration
kafka_producer 发送消息的代码在 ProcducerTest 测试类中编写,代码如下:
package com.jobs; import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.producer.RecordMetadata; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.support.SendResult; import org.springframework.util.concurrent.ListenableFutureCallback; @Slf4j @SpringBootTest public class ProducerTest { @Autowired private KafkaTemplate<String, Object> kafkaTemplate; /** * kafka 默认都是异步发送消息 * 如果向不存在的 topic 发送消息,默认会创建该 topic */ @Test void test1() { kafkaTemplate.send("Topic1", "hello kafka"); } /** * 带有回调函数的异步消息发送(可以监听消息发送是否成功) */ @Test void asyncSendMessageWithCallBack() throws Exception { kafkaTemplate.send("Topic1", "我的中文消息异步发送") .addCallback(new ListenableFutureCallback<SendResult<String, Object>>() { @Override public void onFailure(Throwable throwable) { log.error("发送消息失败:" + throwable.getMessage()); } @Override public void onSuccess(SendResult<String, Object> result) { RecordMetadata record = result.getRecordMetadata(); log.info("发送消息成功:" + record.topic() + "-" + record.partition() + "-" + record.offset()); } }); //为了能够收到回调消息,这里等待 1 秒钟再结束程序 Thread.sleep(1000); } /** * 同步发送消息 */ @Test void syncSendMessage() { try { SendResult<String, Object> result = kafkaTemplate.send("Topic1", "hello kafka").get(); RecordMetadata record = result.getRecordMetadata(); log.info("发送的 toppic 为:" + record.topic() + ",发送的分区为:" + record.partition() + ",发送的消息所在的 offset 为:" + record.offset()); } catch (Exception e) { log.error(e.getMessage()); } } /** * 发送多条消息给 Topic3 进行处理 */ @Test void test2() { for (int i = 0; i < 10; i++) { kafkaTemplate.send("Topic2", "hello kafka " + i); } } /** * 采用事务发送消息,代码中如果报错,则已经发送成功的消息将被撤回,消费者无法获取到消息。 * 注意:需要在 producer 程序的 application.yml 中,启用 transaction-id-prefix 配置,而且 acks 必须为 -1 * 其它的没有使用事务发送消息的方法,必须标注 */ @Test void test3() { kafkaTemplate.executeInTransaction(operations -> { operations.send("Topic3", "采用事务发送的消息"); //如果抛出异常,上面发出去的消息会撤回,消费者无法获取到消息 throw new RuntimeException("fail"); //return null; }); } }
对于 ProcducerConfig 配置类,里面主要是配置了监听器,对所有发送消息的状态进行监控,在实际项目中很少使用,这里只是展示一下:
package com.jobs.config; import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory; import org.springframework.kafka.support.ProducerListener; import org.springframework.stereotype.Component; @Slf4j @Component public class ProducerConfig { @Autowired ProducerFactory producerFactory; /** * 为 KafkaTemplate 设置一个监听器,监测消息发送的状态 */ @Bean public KafkaTemplate<String, Object> kafkaTemplate() { KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<String, Object>(producerFactory); kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() { @Override public void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) { log.info("发送成功: " + producerRecord.value()); } @Override public void onError(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata, Exception exception) { log.error("发送失败: " + producerRecord.value() + " ---> exception=" + exception.getMessage()); } }); return kafkaTemplate; } }
Kafka_consumer 消费者拉取和处理消息
kafka_consumer 消费者,其 application.yml 配置文件内容如下:
server: port: 8010 spring: kafka: # kafka 服务器连接地址和端口,多个服务器之间使用英文逗号分隔 bootstrap-servers: 192.168.136.128:9092 consumer: # 每个 consumer 必须被分配到一个组中 # 对于同一个 topic 来说,相同组内的多个 consumer 一定会拿到不同的消息 # 可以在 application.yml 中配置,也可以在消费者处理程序的 @KafkaListener 注解中配置 group-id: test # 是否启用自动提交 offset # 如果消息相对比较重要的话,建议自己手动提交。如果是不太重要的信息(如日志信息),建议使用自动提交 enable-auto-commit: false # 当 kafka 中没有初始 offset 或 offset 超出范围时将自动重置 offset # earliest: 重置为分区中最小的 offset; # latest: 重置为分区中最新的 offset (从监听的时刻开始,当消费分区中有新数据时,才会进行消费); # none: 只要有一个分区不存在已提交的 offset,就抛出异常; auto-offset-reset: latest # key 和 value 使用 string 序列化和反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: # record 当每一条记录被消费者监听器处理之后提交 # batch 当每一批 poll() 的数据被消费者监听器处理之后提交 # time 当每一批 poll() 的数据被消费者监听器处理之后,距离上次提交时间大于 time 时提交 # count 当每一批 poll() 的数据被消费者监听器处理之后,被处理 record 数量大于等于 count 时提交 # count_time 两种条件:time 或者 count 有一个条件满足时提交 # manual 当每一批 poll() 的数据被消费者监听器处理之后, 手动调用 Acknowledgment.acknowledge() 后提交 # manual_immediate 手动调用 Acknowledgment.acknowledge() 后立即提交 ack-mode: manual_immediate # 消费监听接口监听的主题不存在时,默认会报错,所以设置为false忽略错误 missing-topics-fatal: false # 如果设置为 single,消费处理程序使用 ConsumerRecord 接收,表示单条消息 # 如果设置为 batch,消费处理程序使用 ConsumerRecords 接收,表示多条消息 type: single # 有关 kafka 的相关配置内容,详见官网:https://kafka.apache.org/documentation/#configuration
kafka_consumer 拉取和处理消息的代码在 ConsumerListener 类中编写,代码如下:
package com.jobs.listener; import lombok.extern.slf4j.Slf4j; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.support.Acknowledgment; import org.springframework.stereotype.Component; @Slf4j @Component public class ConsumerListener { //逐个处理 Topic1 中的每条消息,使用 ConsumerRecord 表示获取到一条消息 @KafkaListener(topics = {"Topic1"}, errorHandler = "consumerErrorHandler") public void listener1(ConsumerRecord<String, Object> record, Acknowledgment ack) { log.info("toppic 名称:" + record.topic() + ",分区为:" + record.partition() + ",消息内容为:" + record.value()); //如果想要测试异常处理,可以取消以下代码注释 //Integer result = 1 / 0; //因为在 application.yml 配置的 enable-auto-commit 为 false,因此需要手动提交确认 offset ack.acknowledge(); } //批量处理 Topic2 中的消息,使用 ConsumerRecords 表示获取到的多条消息 //注意:需要将 application.yml 中的 listener.type 修改为 batch @KafkaListener(topics = {"Topic2"}, errorHandler = "consumerErrorHandler") public void listener2(ConsumerRecords<String, Object> records, Acknowledgment ack) { for (ConsumerRecord<?, ?> record : records) { log.info("toppic 名称:" + record.topic() + ",分区为:" + record.partition() + ",消息内容为:" + record.value()); } ack.acknowledge(); } //接收 producer 事务提交的消息 //如果 producer 发送过程中报错,已经发送成功的消息,将被撤销,consumer 将获取不到消息 @KafkaListener(topics = {"Topic3"}, errorHandler = "consumerErrorHandler") public void listener3(ConsumerRecord<String, Object> record, Acknowledgment ack) { log.info("toppic 名称:" + record.topic() + ",分区为:" + record.partition() + ",消息内容为:" + record.value()); ack.acknowledge(); } }
ConsumerConfig 配置类,配置了异常处理的方法(在消费消息的方法上面通过 @KafkaListener 注解的 errorHandler 属性进行配置),代码如下:
package com.jobs.config; import lombok.extern.slf4j.Slf4j; import org.springframework.context.annotation.Bean; import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler; import org.springframework.stereotype.Component; @Slf4j @Component public class ConsumerConfig { //消费异常处理方法,可以配置在所有的消费者监听程序上 //在 @KafkaListener 注解的 errorHandler 属性 @Bean public ConsumerAwareListenerErrorHandler consumerErrorHandler() { return (message, exception, consumer) -> { log.error("触发了消息异常处理程序,消息内容:" + message.getPayload() + ",消费异常信息:" + exception.getMessage()); return null; }; } }
以上就是 Kafka 的简单使用介绍,能够确保快速运用到实际项目中。有关 Kafka 的深入学习和运用请参考官网或其它资料。
经过多个项目的实践经验来看,我个人认为:如果【重要业务】需要使用到消息队列的话,推荐使用 RabbitMQ 或 RocketMQ。对于【非核心业务】如实时日志采集、实时数据统计展示、大数据场景,推荐使用 kafka。
毕竟每种技术都有自己最适合的领域,这里不做过多的讨论,以上观点仅供参考。
本篇博客的源代码下载地址为:https://files.cnblogs.com/files/blogs/699532/springboot_kafka.zip


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!