使用 DSL 和 Java 操作 ElasticSearch
前面已经搭建好了单机版的 ElasticSearch 和 Kibana,接下来就可以通过 DSL 和 Java 代码操作 ElasticSearch。对于 ElasticSearch 来说,DSL(domain specific language )语言其实就是将 restful 请求和 Json 字符串相结合。Java 代码主要采用官方提供的 RestHighLevelClient 的 API 方法操作 ElasticSearch。本篇博客主要介绍有关索引库操作、文档操作、文档查询、聚合查询的相关细节内容,在博客最后会提供源代码下载。
ElasticSearch 官方帮助文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
一、搭建工程
新建一个 SpringBoot 工程,结构如下所示:
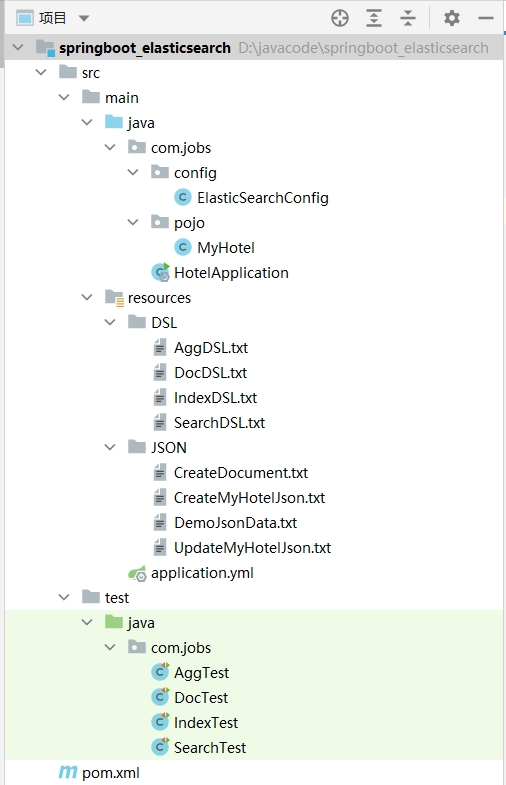
ElasticSearchConfig 主要是配置 RestHighLevelClient 实例对象,用于操作 ElasticSearch
MyHotel 实体类定义了索引库结构,用于作为数据载体,从索引库中获取数据进行展示
DSL 文件夹里面,主要存放用于操作 ElasticSearch 的常用 DSL 语句
JSON 文件夹里面,主要存放 RestHighLevelClient 向 ElasticSearch 发送的 DSL 语句中的 Json 内容
编写了 4 个测试类,分别用于演示 RestHighLevelClient 对索引库、文档、文档查询、聚合查询的操作代码
首先看一下 pom 文件的内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jobs</groupId>
<artifactId>springboot_elasticsearch</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<!--这里强制覆盖 es 依赖的版本号,
从 7.15 版本开始,官方废弃了 RestHighLevelClient 类
因此这里使用废弃 RestHighLevelClient 前的最后一个版本的依赖包
-->
<elasticsearch.version>7.14.2</elasticsearch.version>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--引入 rest high level client 操作 elasticsearch-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.8</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.4.5</version>
</plugin>
</plugins>
</build>
</project>
主要引入了 elasticsearch-rest-high-level-client 这个依赖,由于 SpringBoot 自带的操作 ElasticSearch 依赖版本较低,这里可以在 properties 配置中增加 elasticsearch.version 的配置,覆盖 SpringBoot 自带的ElasticSearch 依赖版本。
本博客在 application.yml 中自定义了 ElasticSearch 的连接信息配置:
# 自定义的 elasticsearch 配置内容
elasticsearch:
username: elastic
password: tdGiSi*fhwW0F60*i*Jc
# 连接的服务器 url,多个 url 之间用英文逗号分隔
urls: http://192.168.136.128:9200
在 ElasticSearchConfig 中读取配置,实例化 RestHighLevelClient 对象放入 Spring 容器中:
package com.jobs.config;
import org.apache.http.Header;
import org.apache.http.HttpHeaders;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
@Configuration
public class ElasticSearchConfig {
//用户名
@Value("${elasticsearch.username}")
private String username;
//密码
@Value("${elasticsearch.password}")
private String password;
//对于 yml 中的配置项,如果配置值是以英文逗号分隔,可直接转换为数组
@Value("${elasticsearch.urls}")
private String[] urls;
@Bean
public RestHighLevelClient restHighLevelClient() {
//设置用户名和密码
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(username, password));
//从 urls 数组中创建出多个 HttpHost 数组
ArrayList<HttpHost> hostlist = new ArrayList<>();
for (String url : urls) {
hostlist.add(HttpHost.create(url));
}
HttpHost[] hosts = hostlist.toArray(new HttpHost[hostlist.size()]);
RestClientBuilder builder = RestClient.builder(hosts);
builder.setHttpClientConfigCallback(s -> s.setDefaultCredentialsProvider(credentialsProvider));
//使用 RestHighLevelClient 操作 ElasticSearch 8 版本时,需要加上以下 header 后,操作索引文档才能不报错
builder.setDefaultHeaders(new Header[]{
new BasicHeader(HttpHeaders.ACCEPT,
"application/vnd.elasticsearch+json;compatible-with=7"),
new BasicHeader(HttpHeaders.CONTENT_TYPE,
"application/vnd.elasticsearch+json;compatible-with=7")});
RestHighLevelClient client = new RestHighLevelClient(builder);
return client;
}
}
下面列出 MyHotel 实体类的细节,该类主要用于承载从 ElasticSearch 查询出来的数据,打印和展示出来。
package com.jobs.pojo;
import lombok.Data;
@Data
public class MyHotel {
private Integer id;
//酒店名称
private String name;
//酒店地址
private String address;
//住宿价格
private Integer price;
//品牌
private String brand;
//所属城市
private String city;
//经纬度
private String location;
//距离
private Double distance;
}
二、索引库操作
索引库操作的 DSL 语句都存储在 IndexDSL.txt 文件中,IndexTest 类是相关的 Java 代码:
# 创建索引库
PUT /myhotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 查询索引库
GET /myhotel
# 修改索引库,添加新字段(索引库创建后,只能新增字段,无法进行其它操作)
PUT /myhotel/_mapping
{
"properties": {
"addScore": {
"type": "integer",
"index": false
}
}
}
# 删除索引库
DELETE /myhotel
package com.jobs;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.client.indices.PutMappingRequest;
import org.elasticsearch.cluster.metadata.MappingMetadata;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.ResourceUtils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Map;
@SpringBootTest
public class IndexTest {
@Autowired
private RestHighLevelClient client;
//创建索引库,如果不存在就创建
@Test
void createIndexTest() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("myhotel");
//读取 resourses/JSON/CreateMyHotelJson.txt 文件内容
File file = ResourceUtils.getFile("classpath:JSON/CreateMyHotelJson.txt");
String createJson;
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
createJson = br.readLine();
}
createIndexRequest.source(createJson, XContentType.JSON);
client.indices().create(createIndexRequest, RequestOptions.DEFAULT);
}
//判断索引库是否存在,true 表示存在,false 表示不存在
@Test
void existsIndexTest() throws IOException {
GetIndexRequest request = new GetIndexRequest("myhotel");
boolean isExists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(isExists ? "索引库已存在" : "索引库不存在");
}
//对索引库,只能新增字段,无法进行其它的操作
@Test
void updateIndexTest() throws Exception {
PutMappingRequest putMappingRequest = new PutMappingRequest("myhotel");
//读取 resourses/JSON/UpdateMyHotelJson.txt 文件内容
File file = ResourceUtils.getFile("classpath:JSON/UpdateMyHotelJson.txt");
String createJson;
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
createJson = br.readLine();
}
putMappingRequest.source(createJson, XContentType.JSON);
client.indices().putMapping(putMappingRequest, RequestOptions.DEFAULT);
System.out.println("索引库新增字段成功");
}
//查看索引库的数据结构 Json
@Test
void getIndexTest() throws IOException {
GetIndexRequest request = new GetIndexRequest("myhotel");
GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);
Map<String, MappingMetadata> mappings = response.getMappings();
String result = JSON.toJSONString(mappings, SerializerFeature.PrettyFormat);
System.out.println(result);
}
//删除索引库
@Test
void deleteIndexTest() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("myhotel");
client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println("删除索引库成功");
}
}
三、文档操作
文档的简单操作的 DSL 语句都存储在 DocDSL.txt 文件中,DocTest 类是相关的 Java 代码:
# 添加文档/全量更新文档
POST /myhotel/_doc/1
{
"id": 1,
"name": "北京海航大厦万豪酒店",
"address": "霄云路甲26号",
"price": 1302,
"brand": "万豪",
"city": "北京",
"location": "39.959861, 116.467363"
}
# 使用 PUT 也可以添加文档/全量更新文档
PUT /myhotel/_doc/1
{
"id": 1,
"name": "北京海航大厦万豪酒店",
"address": "霄云路甲26号",
"price": 1302,
"brand": "万豪",
"city": "北京",
"location": "39.959861, 116.467363"
}
# 根据文档 id 查询文档
GET /myhotel/_doc/1
# 根据文档 id 修改文档中的一部分字段
POST /myhotel/_update/1
{
"doc": {
"name": "侯胖胖任肥肥合资控股酒店",
"price": 666
}
}
# 删除文档
DELETE /myhotel/_doc/1
package com.jobs;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.jobs.pojo.MyHotel;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.ResourceUtils;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
@SpringBootTest
public class DocTest {
@Autowired
private RestHighLevelClient client;
//添加文档,如果文档 id 已存在,则删除原来的文档,然后再新增,因此该方法也可以用作全量修改
@Test
void addDocTest() throws IOException {
//读取 resourses/JSON/CreateDocument.txt 文件内容
File file = ResourceUtils.getFile("classpath:JSON/CreateDocument.txt");
String json;
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
json = br.readLine();
}
JSONObject jsonObj = JSON.parseObject(json);
IndexRequest request = new IndexRequest("myhotel").id(jsonObj.getString("id"));
request.source(json, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
//根据文档 id 查询文档内容
@Test
void getDocByIdTest() throws IOException {
GetRequest request = new GetRequest("myhotel", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//获取并打印文档的 json 内容
String json = response.getSourceAsString();
System.out.println(json);
//转换成 MyHotel 并打印
MyHotel myHotel = JSON.parseObject(json, MyHotel.class);
System.out.println(myHotel);
}
//修改文档的部分字段
@Test
void updateDocPartTest() throws IOException {
UpdateRequest request = new UpdateRequest("myhotel", "1");
//这里修改【名称】和【价格】,字段名和字段值都是使用英文逗号分隔
request.doc("name", "侯胖胖任肥肥合资控股酒店", "price", "666");
client.update(request, RequestOptions.DEFAULT);
}
//删除文档
@Test
void deleteDocTest() throws IOException {
DeleteRequest request = new DeleteRequest("myhotel", "1");
client.delete(request, RequestOptions.DEFAULT);
}
//批量添加样例数据
//BulkRequest 可以添加各种请求,如 IndexRequest,UpdateRequest,DeleteRequest
@Test
void bulkRequestTest() throws IOException {
//读取 resourses/JSON/DemoJsonData.txt 文件内容
File file = ResourceUtils.getFile("classpath:JSON/DemoJsonData.txt");
//使用 BulkRequest 批量请求对象
BulkRequest request = new BulkRequest();
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String json = br.readLine();
JSONObject jsonObj;
while (StringUtils.isNotBlank(json)) {
jsonObj = JSON.parseObject(json);
//为 BulkRequest 添加请求对象
request.add(new IndexRequest("myhotel")
.id(jsonObj.getString("id"))
.source(json, XContentType.JSON));
json = br.readLine();
}
}
client.bulk(request, RequestOptions.DEFAULT);
}
}
四、文档查询
文档查询操作的 DSL 语句都存储在 SearchDSL.txt 文件中,SearchTest 类是相关的 Java 代码:
# 查询所有数据
GET /myhotel/_search
# 查询所有数据
GET /myhotel/_search
{
"query": {
"match_all": {}
}
}
# 查询单个字段
GET /myhotel/_search
{
"query": {
"match": {
"all": "朝阳如家"
}
}
}
# 查询多个字段
GET /myhotel/_search
{
"query": {
"multi_match": {
"query": "朝阳如家",
"fields": ["brand","name"]
}
}
}
# term 精确查询
GET /myhotel/_search
{
"query": {
"term": {
"city": {"value": "北京"}
}
}
}
# 范围查询
GET /myhotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 300
}
}
}
}
# 多条件 bool 查询
GET /myhotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "5km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
# 地理坐标距离查询
GET /myhotel/_search
{
"query": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
}
# 算分查询
GET /myhotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "朝阳"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}
# 查询结果排序
GET /myhotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
},
{
"id": "asc"
}
]
}
# 查询结果按照距离排序
GET /myhotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 31.034661,
"lon": 121.612282
},
"order": "asc",
"unit": "km"
}
}
]
}
# 查询结果分页
GET /myhotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 20,
"size": 10
}
# 查询结果高亮显示
GET /myhotel/_search
{
"query": {
"match": {
"all": "北广场"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
package com.jobs;
import com.alibaba.fastjson.JSON;
import com.jobs.pojo.MyHotel;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.lucene.search.function.CombineFunction;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.Map;
@SpringBootTest
public class SearchTest {
@Autowired
private RestHighLevelClient client;
//查询所有数据,elasticsearch 默认分页,每页 10 条,查询出第 1 页的结果
@Test
void matchAllTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//多字段查询,尽量少用,因为字段越多,性能越差,
//建议将多字段使用 copyto 合并到一个新字段,针对新字段进行查询
@Test
void MutiMatchTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.multiMatchQuery("朝阳如家", "name", "brand"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//单字段查询(之前创建索引库时,将 name 和 brand 使用 copyto 合并到了 all 字段中)
//因此这里针对 all 字段的查询,相当于针对 name 和 brand 两个字段的查询
@Test
void matchSingleTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.matchQuery("all", "朝阳如家"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//term 精确查询
@Test
void matchTermTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.termQuery("city", "北京"));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//range 范围查询
@Test
void matchRangeTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.rangeQuery("price").gte(200).lte(500));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//多条件 bool 组合查询
//must 和 should 参与评分,filter 和 mustNot 不存与评分
//最常使用的是 must 和 filter 这两个组合
@Test
void boolTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("city", "北京"))
.filter(QueryBuilders.rangeQuery("price").gte(200).lte(500)));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//分页查询,对查询结果进行排序
@Test
void sortAndPageTest() throws IOException {
int page = 3, size = 6;
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.matchAllQuery());
//排序
request.source().sort("price", SortOrder.ASC);
//分页
request.source().from((page - 1) * size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//查询指定中心点 5 公里范围内的数据,查询结果按照距离由小到大排序
@Test
void matchDistanceTest() throws IOException {
//中心点:纬度,经度
String myPoint = "31.21,121.5";
SearchRequest request = new SearchRequest("myhotel");
//查询在中心点在 5 公里范围内的数据
request.source().query(
QueryBuilders.geoDistanceQuery("location")
.point(new GeoPoint(myPoint))
.distance(5, DistanceUnit.KILOMETERS));
//按照与中心点的距离,从小到到大升序排列
request.source().sort(SortBuilders
.geoDistanceSort("location", new GeoPoint(myPoint))
.order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response, "location");
}
//算法函数查询,给自己认为比较重要的数据增加分数,在结果中可以靠前排列
//需要注意:使用算分函数查询时,不要指定排序字段,因为一旦指定排序字段,就不再进行算分。
@Test
void funcTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
//设置一些查询条件,比如查询上海价格在 200 到 600 的酒店,
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city", "上海"));
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(200).lte(600));
//在查询出来的酒店中,我想让如家酒店的算法和排名靠前一些,
//给【速8酒店】的分数,增加10分,采用【原始分+函数分】之和的方式,计算得分,分值越大,排名越靠前
FunctionScoreQueryBuilder functionScoreQuery =
QueryBuilders.functionScoreQuery(boolQuery,
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("brand", "速8"),
ScoreFunctionBuilders.weightFactorFunction(10))})
.boostMode(CombineFunction.SUM);
request.source().query(functionScoreQuery);
//对于 elasticsearch 来说,默认就是按照算分排序的
//算分函数,可以让自定义控制相关数据的分数算法
//如果一旦指定了排序字段的话,elasitcsearch 就不再进行算分,不会按照算分排序了。
//request.source().sort("price", SortOrder.ASC);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
//关键字高亮查询
@Test
void highlightTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.matchQuery("all", "朝阳如家"));
//当查询字段与高亮字段不一致时,需要使用 requireFieldMatch 为 false 才能高亮显示
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
processResponse(response);
}
private void processResponse(SearchResponse response) {
processResponse(response, null);
}
//处理和展示结果,sortField 表示对结果进行排序的字段
private void processResponse(SearchResponse response, String sortField) {
SearchHits searchHits = response.getHits();
//获取查询到的总条数
long total = searchHits.getTotalHits().value;
System.out.println("查询到的总数为:" + total);
//获取查询结果
SearchHit[] hits = searchHits.getHits();
if (hits.length > 0) {
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
MyHotel myhotel = JSON.parseObject(json, MyHotel.class);
//如果有高亮结果的话,获取和处理高亮的数据
Map<String, HighlightField> map = hit.getHighlightFields();
if (map != null && map.size() > 0) {
//想获取名称中高亮的结果
HighlightField highlightField = map.get("name");
if (highlightField != null &&
highlightField.getFragments().length > 0) {
String hName = highlightField.getFragments()[0].toString();
//替换对象中的名称数据
myhotel.setName(hName);
}
}
//如果有距离排序的话,获取距离数据
if (StringUtils.isNotBlank(sortField) &&
sortField.equalsIgnoreCase("location")) {
Object[] sortValues = hit.getSortValues();
if (sortValues != null && sortValues.length > 0) {
myhotel.setDistance((double) sortValues[0]);
}
}
System.out.println(myhotel);
}
}
}
}
五、聚合查询
常用聚合查询操作的 DSL 语句都存储在 AggDSL.txt 文件中,AggTest 类是相关的 Java 代码:
# 按照 brand 进行聚合统计,默认按照统计值降序排列
GET /myhotel/_search
{
# size 值为 0 表示不要返回具体的每条数据,
# 查询结果中只需要返回统计数据即可
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
# 设置排序规则,按照统计值升序排列
# 不指定排序的规则的话,默认按照统计值降序排列
GET /myhotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"_count": "asc"
}
}
}
}
}
# 先查询出价格小于200的数据,根据查询的结果再按照 brand 进行聚合统计
GET /myhotel/_search
{
"query": {
"range": {
"price": {
"lte": 200
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
# 嵌套聚合,stats 可以聚合出 min,max,sum,avg
GET /myhotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"priceAgg.min": "asc"
}
},
"aggs": {
"priceAgg": {
"stats": {
"field": "price"
}
}
}
}
}
}
# 嵌套聚合,换一种写法求 min,max,sum,avg
# 此种写法,可以自定义查询部分聚合信息,比如:只查询 avg
GET /myhotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20,
"order": {
"minAgg": "asc"
}
},
"aggs": {
"minAgg": {
"min": {
"field": "price"
}
},
"maxAgg":{
"max": {
"field": "price"
}
},
"sumAgg":{
"sum": {
"field": "price"
}
},
"avgAgg":{
"avg": {
"field": "price"
}
}
}
}
}
}
package com.jobs;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.BucketOrder;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.*;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class AggTest {
@Autowired
private RestHighLevelClient client;
//对价格在 200 到 500 之间的酒店,按照品牌统计数量,取前 10 条统计信息
//默认情况下,是按照统计的数字,从大到小倒序排列
@Test
void aggTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.rangeQuery("price").gte(200).lte(500));
//表示不要返回文档记录数据
request.source().size(0);
//表示返回聚合统计数据,默认情况下按照统计数量的倒序排列
request.source().aggregation(AggregationBuilders
//给统计聚合的字段,自定义一个字段名称,后面需要使用
.terms("brandAgg").field("brand").size(10));
//如果想按照统计数量的升序排列的话,代码如下:
//request.source().aggregation(AggregationBuilders
// .terms("brandAgg").field("brand").size(10)
// .order(BucketOrder.count(true)));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//获取返回的聚合数统计数据
Aggregations aggregations = response.getAggregations();
Terms brandAgg = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
if (buckets.size() > 0) {
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println("brand:" + brandName + ",count:" + docCount);
}
}
}
//对价格在 200 到 500 之间的酒店,
//按照品牌统计总数,最小价格,最大价格,总价格之和,平均价格
//并且查询的结果数据,按照最小价格升序排列
@Test
void aggStatsTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.rangeQuery("price").gte(200).lte(500));
//表示不要返回文档记录数据
request.source().size(0);
TermsAggregationBuilder termsAggregationBuilder =
//给统计聚合的字段,自定义一个字段名称,后面需要使用
AggregationBuilders.terms("brandAgg").field("brand")
//查询结果按照 priceAgg.min 升序排列
.order(BucketOrder.aggregation("priceAgg.min", true))
//给子聚合统计的字段,自定义一个字段名称,后面需要使用
.subAggregation(AggregationBuilders.stats("priceAgg").field("price"));
//表示返回聚合统计数据,默认情况下按照统计数量的倒序排列
request.source().aggregation(termsAggregationBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//获取返回的聚合数统计数据
Aggregations aggregations = response.getAggregations();
Terms brandAgg = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
if (buckets.size() > 0) {
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
//获取子聚合统计数据
Stats priceAgg = bucket.getAggregations().get("priceAgg");
String min = priceAgg.getMinAsString();
String max = priceAgg.getMaxAsString();
String sum = priceAgg.getSumAsString();
String avg = priceAgg.getAvgAsString();
System.out.println("brand:" + brandName + ",count:" + docCount +
",最小:" + min + ",最大:" + max + ",总和:" + sum + ",平均:" + avg);
}
}
}
//换一种写法
//对价格在 200 到 500 之间的酒店,
//按照品牌统计总数,最小价格,最大价格,总价格之和,平均价格
//并且查询的结果数据,按照最小价格升序排列
@Test
void aggregationTest() throws IOException {
SearchRequest request = new SearchRequest("myhotel");
request.source().query(QueryBuilders.rangeQuery("price").gte(200).lte(500));
//表示不要返回文档记录数据
request.source().size(0);
TermsAggregationBuilder termsAggregationBuilder =
//给统计聚合的字段,自定义一个字段名称,后面需要使用
AggregationBuilders.terms("brandAgg").field("brand")
//查询结果按照 minAgg 统计值升序排列
.order(BucketOrder.aggregation("minAgg", true));
MinAggregationBuilder minAgg = AggregationBuilders.min("minAgg").field("price");
MaxAggregationBuilder maxAgg = AggregationBuilders.max("maxAgg").field("price");
SumAggregationBuilder sumAgg = AggregationBuilders.sum("sumAgg").field("price");
AvgAggregationBuilder avgAgg = AggregationBuilders.avg("avgAgg").field("price");
termsAggregationBuilder.subAggregation(minAgg);
termsAggregationBuilder.subAggregation(maxAgg);
termsAggregationBuilder.subAggregation(sumAgg);
termsAggregationBuilder.subAggregation(avgAgg);
//表示返回聚合统计数据,默认情况下按照统计数量的倒序排列
request.source().aggregation(termsAggregationBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//获取返回的聚合数统计数据
Aggregations aggregations = response.getAggregations();
Terms brandAgg = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
if (buckets.size() > 0) {
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
//获取子聚合统计数据
Aggregations bucketAgg = bucket.getAggregations();
Min min = bucketAgg.get("minAgg");
Max max = bucketAgg.get("maxAgg");
Sum sum = bucketAgg.get("sumAgg");
Avg avg = bucketAgg.get("avgAgg");
System.out.println("brand:" + brandName + ",count:" + docCount +
",最小:" + min.getValueAsString() +
",最大:" + max.getValueAsString() +
",总和:" + sum.getValueAsString() +
",平均:" + avg.getValueAsString());
}
}
}
}
本盘博客的源代码下载地址为:https://files.cnblogs.com/files/blogs/699532/springboot_elasticsearch.zip

 浙公网安备 33010602011771号
浙公网安备 33010602011771号