Spring 使用 JdbcTemplate 操作数据库
之前我们使用 Java 操作数据库,要么使用自己封装的 Jdbc 工具类,要么使用 Mybatis。现在 Spring 自带的 JdbcTemplate 工具类使用起来也非常简单。如果你在实际开发中不想使用 Mybatis 的话,不妨可以使用 Spring 自带的 JdbcTemplate 工具类。
本篇博客主要演示 Spring 自带的两种 JdbcTemplate 工具类的使用,一种是必须按照 SQL 语句中的参数顺序,提供参数的 JdbcTemplate 工具类,一种是按照 SQL 语句中参数名称,提供参数的 NamedParameterJdbcTemplate 工具类。当然如果在实际开发中使用的话,强烈推荐使用 NamedParameterJdbcTemplate 工具类。另外在本篇博客最后会提供 Demo 的源代码。
一、搭建工程
新建一个 maven 项目,导入相关 jar 包,我导入的都是最新版本的 jar 包,内容如下:
有关具体的 jar 包地址,可以在 https://mvnrepository.com 上进行查询。
<dependencies>
<!--Spring 相关的 jar 包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.17</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.3.17</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.3.17</version>
<scope>test</scope>
</dependency>
<!--Mysql 和数据库连接池相关的 jar 包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--
其它相关 jar 包:
junit 单元测试方法编写所需要的 jar 包
commons-lang3 这个是 apache 提供的实用的公共类工具 jar 包
-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
</dependencies>
打开右侧的 Maven 窗口,刷新一下,这样 Maven 会自动下载所需的 jar 包文件。
搭建好的项目工程整体目录比较简单,具体如下图所示:
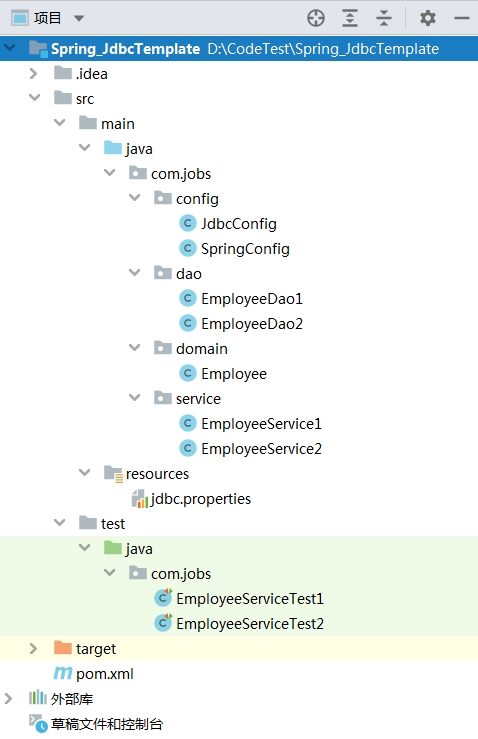
项目工程结构简单介绍:
config 包下存放的是 Spring 的配置类
dao 包下存放的是使用 JdbcTemplate 操作数据库的方法类
domain 包下存放是具体的 Java Bean 实体对象类
service 包下存放的是转调 dao 进行业务处理实现类
resources 目录下存放的是连接数据库的相关参数的配置文件
test 目录下是两个 Service 测试方法类,里面编写了间接测试两种 JdbcTemplate 数据库操作的方法
说明:本 Demo 主要通过对 Employee 表进行增删改查,演示 JdbcTemplate 和 NamedParameterJdbcTemplate 的使用。
二、相关配置细节
在本机的 mysql 中运行以下 sql 脚本,进行数据库环境的准备工作,内容如下:
CREATE DATABASE IF NOT EXISTS `testdb`;
USE `testdb`;
CREATE TABLE IF NOT EXISTS `employee` (
`e_id` int(11) NOT NULL AUTO_INCREMENT,
`e_name` varchar(50) DEFAULT NULL,
`e_salary` int(11) DEFAULT NULL,
PRIMARY KEY (`e_id`)
) ENGINE=InnoDB AUTO_INCREMENT=103 DEFAULT CHARSET=utf8;
INSERT INTO `employee` (`e_id`, `e_name`, `e_salary`) VALUES
(1, '侯胖胖', 25000),
(2, '杨磅磅', 23000),
(3, '李吨吨', 33000),
(4, '任肥肥', 35000),
(5, '乔豆豆', 32000),
(6, '任天蓬', 38000),
(7, '任政富', 40000);
在 resources 目录下的 jdbc.properties 文件配置数据库连接信息,内容如下:
mysql.driver=com.mysql.cj.jdbc.Driver
mysql.url=jdbc:mysql://localhost:3306/testdb?useSSL=false
mysql.username=root
mysql.password=123456
# 初始化连接的数量
druid.initialSize=3
# 最大连接的数量
druid.maxActive=20
# 获取连接的最大等待时间(毫秒)
druid.maxWait=3000
在 config 包下,编写 Jdbc 连接数据库的配置类,两种 JdbcTemplate 的 Spring Bean 装载类,以及 Spring 的配置类:
package com.jobs.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.PropertySource;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import javax.sql.DataSource;
//通过 @PropertySource 注解,加载 jdbc.properties 文件的配置信息
@PropertySource("classpath:jdbc.properties")
public class JdbcConfig {
//通过 @Value 注解,获取 jdbc.properties 文件中相关 key 的配置值
@Value("${mysql.driver}")
private String driver;
@Value("${mysql.url}")
private String url;
@Value("${mysql.username}")
private String userName;
@Value("${mysql.password}")
private String password;
@Value("${druid.initialSize}")
private Integer initialSize;
@Value("${druid.maxActive}")
private Integer maxActive;
@Value("${druid.maxWait}")
private Long maxWait;
//让 Spring 装载 druid 具有数据库连接池的数据源
@Bean
public DataSource getDataSource() {
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
ds.setInitialSize(initialSize);
ds.setMaxActive(maxActive);
ds.setMaxWait(maxWait);
return ds;
}
//让 Spring 装载 JdbcTemplate 对象
@Bean("jdbcTemplate1")
public JdbcTemplate getJdbcTemplate(@Autowired DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
//让 Spring 装载 NamedParameterJdbcTemplate 对象
@Bean("jdbcTemplate2")
public NamedParameterJdbcTemplate getJdbcTemplate2(@Autowired DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}
}
package com.jobs.config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
@Configuration
@ComponentScan("com.jobs")
@Import(JdbcConfig.class)
public class SpringConfig {
}
三、其它细节相关
首先列出 domain 包下 Employee 实体类细节,内容如下:
注意:这里的 Employee 类的各个字段,保持跟数据库表 employee 的相应字段一致。因为这样做的话,后续返回实体类对象或实体类对象列表时,在两种 JdbcTemplate 工具类中,都可以使用 BeanPropertyRowMapper 自动进行数据库表字段与实体类字段的映射赋值,使用起来非常方便,大大提高了开发效率。
package com.jobs.domain;
public class Employee {
private Integer e_id;
private String e_name;
private Integer e_salary;
public Employee() {
}
public Employee(Integer e_id, String e_name, Integer e_salary) {
this.e_id = e_id;
this.e_name = e_name;
this.e_salary = e_salary;
}
//此处省略了 get 和 set 方法的细节....
@Override
public String toString() {
return "Employee{" +
"e_id=" + e_id +
", e_name='" + e_name + '\'' +
", e_salary=" + e_salary +
'}';
}
}
dao 层中两种 JdbcTemplate 工具类的使用细节:
package com.jobs.dao;
import com.jobs.domain.Employee;
import org.apache.commons.lang3.StringUtils;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Repository;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
@Repository
public class EmployeeDao1 {
@Resource(name = "jdbcTemplate1")
private JdbcTemplate jdbcTemplate;
//添加员工,返回受影响的行数
public Integer add(Employee emp) {
String sql = "insert into employee(e_id,e_name,e_salary) values(?,?,?)";
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
Object[] params = {emp.getE_id(), emp.getE_name(), emp.getE_salary()};
Integer result = jdbcTemplate.update(sql, params);
return result;
}
//修改员工信息,返回受影响的行数
public Integer update(Employee emp) {
String sql = "update employee set e_name=?,e_salary=? where e_id=?";
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
Object[] params = {emp.getE_name(), emp.getE_salary(), emp.getE_id()};
Integer result = jdbcTemplate.update(sql, params);
return result;
}
//获取员工的数量
public Long getEmployeeCount() {
String sql = "select count(*) from employee";
Long result = jdbcTemplate.queryForObject(sql, Long.class);
return result;
}
//根据员工 id 查询员工信息
public Employee getEmployeeById(Integer eid) {
String sql = "select e_id,e_name,e_salary from employee where e_id = ?";
//自定义数据库的行数据,与 JavaBean 的字段属性映射解析器
RowMapper<Employee> rm = (rs, rowNum) -> {
Employee emp = new Employee();
emp.setE_id(rs.getInt("e_id"));
emp.setE_name(rs.getString("e_name"));
emp.setE_salary(rs.getInt("e_salary"));
return emp;
};
return jdbcTemplate.queryForObject(sql, rm, eid);
}
//查询出所有员工,按照id升序排列
public List<Employee> selectAll() {
String sql = "select e_id,e_name,e_salary from employee order by e_id";
//如果数据库字段名称,与 JavaBean 的字段的名称完全一致的情况下,可以简化代码
List<Employee> emplist = jdbcTemplate.query(sql,
new BeanPropertyRowMapper<Employee>(Employee.class));
return emplist;
}
//根据条件,查询员工
public List<Employee> selectByCondition(String name, Integer salaryStart, Integer salaryEnd) {
StringBuilder sql = new StringBuilder();
List<Object> paramList = new ArrayList<>();
sql.append(" select e_id,e_name,e_salary from employee where 1=1");
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
if (StringUtils.isNotBlank(name)) {
sql.append(" and (e_name like CONCAT('%',?,'%'))");
paramList.add(name);
}
if (salaryStart != null) {
sql.append(" and e_salary >= ?");
paramList.add(salaryStart);
}
if (salaryEnd != null) {
sql.append(" and e_salary <= ?");
paramList.add(salaryEnd);
}
sql.append(" order by e_id");
//如果数据库字段名称,与 JavaBean 的字段的名称完全一致的情况下,可以简化代码
//注意:这里传递的 SQL 参数列表,需要将 List 转换为 Array ,否则会报错
List<Employee> emplist = jdbcTemplate.query(sql.toString(),
new BeanPropertyRowMapper<Employee>(Employee.class), paramList.toArray());
return emplist;
}
//传入一个或多个id,删除指定的员工
public Integer deleteByIds(Integer... empids) {
StringBuilder sql = new StringBuilder();
List<Object> paramList = new ArrayList<>();
sql.append("delete from employee");
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
//这里故意使用参数传递,展示 JdbcTemplate 的参数使用方式
if (empids != null && empids.length > 0) {
sql.append(" where e_id in (");
for (int i = 0; i < empids.length; i++) {
if (i == 0) {
sql.append("?");
} else {
sql.append(",?");
}
paramList.add(empids[i]);
}
sql.append(")");
} else {
//如果没有传递员工 id 的话,就不删除任何数据
sql.append(" where 1=2");
}
//注意:这里传递的 SQL 参数列表,需要将 List 转换为 Array ,否则会报错
Integer result = jdbcTemplate.update(sql.toString(), paramList.toArray());
return result;
/*
//这是没有使用参数的实现方案,比较简单一些
if (empids != null && empids.length > 0) {
String idsql = StringUtils.join(empids, ",");
sql.append(" where e_id in (").append(idsql).append(")");
} else {
//如果没有传递员工 id 的话,就不删除任何数据
sql.append(" where 1=2");
}
Integer result = jdbcTemplate.update(sql.toString());
return result;
*/
}
}
package com.jobs.dao;
import com.jobs.domain.Employee;
import org.apache.commons.lang3.StringUtils;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.stereotype.Repository;
import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Repository
public class EmployeeDao2 {
@Resource(name = "jdbcTemplate2")
private NamedParameterJdbcTemplate jdbcTemplate;
//添加员工,返回受影响的行数
public Integer add(Employee emp) {
String sql = "insert into employee(e_id,e_name,e_salary) values(:id,:name,:salary)";
//使用 NamedParameterJdbcTemplate 操作数据库,需要提供 sql 语句中对应的参数和值,顺序无所谓
//注意:参数名称不需要加冒号
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("salary", emp.getE_salary());
paramMap.put("id", emp.getE_id());
paramMap.put("name", emp.getE_name());
Integer result = jdbcTemplate.update(sql, paramMap);
return result;
}
//修改员工信息,返回受影响的行数
public Integer update(Employee emp) {
String sql = "update employee set e_name=:name,e_salary=:salary where e_id=:id";
//使用 NamedParameterJdbcTemplate 操作数据库,需要提供 sql 语句中对应的参数和值,顺序无所谓
//注意:参数名称不需要加冒号
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("salary", emp.getE_salary());
paramMap.put("id", emp.getE_id());
paramMap.put("name", emp.getE_name());
Integer result = jdbcTemplate.update(sql, paramMap);
return result;
}
//获取员工的数量
public Long getEmployeeCount() {
String sql = "select count(*) from employee";
Long result = jdbcTemplate.queryForObject(sql, new HashMap<>(), Long.class);
return result;
}
//根据员工 id 查询员工信息
public Employee getEmployeeById(Integer eid) {
String sql = "select e_id,e_name,e_salary from employee where e_id =:id";
//自定义数据库的行数据,与 JavaBean 的字段属性映射解析器
RowMapper<Employee> rm = (rs, rowNum) -> {
Employee emp = new Employee();
emp.setE_id(rs.getInt("e_id"));
emp.setE_name(rs.getString("e_name"));
emp.setE_salary(rs.getInt("e_salary"));
return emp;
};
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("id", eid);
return jdbcTemplate.queryForObject(sql, paramMap, rm);
}
//查询出所有员工,按照id升序排列
public List<Employee> selectAll() {
String sql = "select e_id,e_name,e_salary from employee order by e_id";
//如果数据库字段名称,与 JavaBean 的字段的名称完全一致的情况下,可以简化代码
List<Employee> emplist = jdbcTemplate.query(sql,
new BeanPropertyRowMapper<Employee>(Employee.class));
return emplist;
}
//根据条件,查询员工
public List<Employee> selectByCondition(String name, Integer salaryStart, Integer salaryEnd) {
StringBuilder sql = new StringBuilder();
Map<String, Object> paramMap = new HashMap<>();
sql.append(" select e_id,e_name,e_salary from employee where 1=1");
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
if (StringUtils.isNotBlank(name)) {
sql.append(" and (e_name like CONCAT('%',:name,'%'))");
paramMap.put("name", name);
}
if (salaryStart != null) {
sql.append(" and e_salary >= :start");
paramMap.put("start", salaryStart);
}
if (salaryEnd != null) {
sql.append(" and e_salary <= :end");
paramMap.put("end", salaryEnd);
}
sql.append(" order by e_id");
//如果数据库字段名称,与 JavaBean 的字段的名称完全一致的情况下,可以简化代码
List<Employee> emplist = jdbcTemplate.query(sql.toString(),
paramMap, new BeanPropertyRowMapper<Employee>(Employee.class));
return emplist;
}
//传入一个或多个id,删除指定的员工
public Integer deleteByIds(Integer... empids) {
StringBuilder sql = new StringBuilder();
Map<String, Object> paramMap = new HashMap<>();
sql.append("delete from employee");
//使用 JdbcTemplate 操作数据库,参数顺序需要跟 sql 语句中的参数顺序,保持一致
//这里故意使用参数传递,展示 JdbcTemplate 的参数使用方式
if (empids != null && empids.length > 0) {
sql.append(" where e_id in (");
for (int i = 0; i < empids.length; i++) {
if (i == 0) {
sql.append(":id" + i);
} else {
sql.append(",:id" + i);
}
paramMap.put("id" + i, empids[i]);
}
sql.append(")");
} else {
//如果没有传递员工 id 的话,就不删除任何数据
sql.append(" where 1=2");
}
Integer result = jdbcTemplate.update(sql.toString(), paramMap);
return result;
/*
//这是没有使用参数的实现方案,比较简单一些
if (empids != null && empids.length > 0) {
String idsql = StringUtils.join(empids, ",");
sql.append(" where e_id in (").append(idsql).append(")");
} else {
//如果没有传递员工 id 的话,就不删除任何数据
sql.append(" where 1=2");
}
Integer result = jdbcTemplate.update(sql.toString());
return result;
*/
}
}
下面列出 service 包下的两个业务处理类,由于本 Demo 的业务很简单,所以这里只是对相应 dao 层两个类的对应方法转调:
package com.jobs.service;
import com.jobs.dao.EmployeeDao1;
import com.jobs.domain.Employee;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class EmployeeService1 {
@Autowired
private EmployeeDao1 employeeDao1;
//添加员工,返回受影响的行数
public Integer add(Employee emp) {
return employeeDao1.add(emp);
}
//修改员工信息,返回受影响的行数
public Integer update(Employee emp) {
return employeeDao1.update(emp);
}
//获取员工的数量
public Long getEmployeeCount() {
return employeeDao1.getEmployeeCount();
}
//根据员工 id 查询员工信息
public Employee getEmployeeById(Integer eid) {
return employeeDao1.getEmployeeById(eid);
}
//查询出所有员工,按照id升序排列
public List<Employee> selectAll() {
return employeeDao1.selectAll();
}
//根据条件,查询员工
public List<Employee> selectByCondition(String name, Integer salaryStart, Integer salaryEnd) {
return employeeDao1.selectByCondition(name, salaryStart, salaryEnd);
}
//传入一个或多个id,删除指定的员工
public Integer deleteByIds(Integer... empids) {
return employeeDao1.deleteByIds(empids);
}
}
package com.jobs.service;
import com.jobs.dao.EmployeeDao2;
import com.jobs.domain.Employee;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class EmployeeService2 {
@Autowired
private EmployeeDao2 employeeDao2;
//添加员工,返回受影响的行数
public Integer add(Employee emp) {
return employeeDao2.add(emp);
}
//修改员工信息,返回受影响的行数
public Integer update(Employee emp) {
return employeeDao2.update(emp);
}
//获取员工的数量
public Long getEmployeeCount() {
return employeeDao2.getEmployeeCount();
}
//根据员工 id 查询员工信息
public Employee getEmployeeById(Integer eid) {
return employeeDao2.getEmployeeById(eid);
}
//查询出所有员工,按照id升序排列
public List<Employee> selectAll() {
return employeeDao2.selectAll();
}
//根据条件,查询员工
public List<Employee> selectByCondition(String name, Integer salaryStart, Integer salaryEnd) {
return employeeDao2.selectByCondition(name, salaryStart, salaryEnd);
}
//传入一个或多个id,删除指定的员工
public Integer deleteByIds(Integer... empids) {
return employeeDao2.deleteByIds(empids);
}
}
四、成果测试验证
最后我们在 test 目录下创建两个测试类,测试验证上面编写的代码成果:
package com.jobs;
import com.jobs.config.SpringConfig;
import com.jobs.domain.Employee;
import com.jobs.service.EmployeeService1;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class EmployeeServiceTest1 {
//对 JdbcTemplate 的使用,进行测试
@Autowired
private EmployeeService1 employeeService1;
//添加员工,返回受影响的行数
@Test
public void add() {
Employee emp1 = new Employee(100, "候菲特", 50000);
Integer result1 = employeeService1.add(emp1);
System.out.println(result1);
Employee emp2 = new Employee(101, "任盖茨", 60000);
Integer result2 = employeeService1.add(emp2);
System.out.println(result2);
Employee emp3 = new Employee(102, "李政富", 70000);
Integer result3 = employeeService1.add(emp3);
System.out.println(result3);
}
//修改员工信息,返回受影响的行数
@Test
public void update() {
Employee emp = new Employee(100, "任首富", 80000);
Integer result = employeeService1.update(emp);
System.out.println(result);
}
//获取员工的数量
@Test
public void getEmployeeCount() {
long result = employeeService1.getEmployeeCount();
System.out.println(result);
}
//根据员工 id 查询员工信息
@Test
public void getEmployeeById() {
Employee emp = employeeService1.getEmployeeById(100);
System.out.println(emp);
}
//查询出所有员工,按照id升序排列
@Test
public void selectAll() {
List<Employee> emplist = employeeService1.selectAll();
for (Employee emp : emplist) {
System.out.println(emp);
}
}
//根据条件,查询员工
@Test
public void selectByCondition() {
String name = "任";
int start = 30000;
int end = 60000;
List<Employee> emplist = employeeService1.selectByCondition(name, start, end);
for (Employee emp : emplist) {
System.out.println(emp);
}
}
//传入一个或多个id,删除指定的员工
@Test
public void deleteByIds() {
int result = employeeService1.deleteByIds(100, 101, 102);
System.out.println(result);
}
}
package com.jobs;
import com.jobs.config.SpringConfig;
import com.jobs.domain.Employee;
import com.jobs.service.EmployeeService2;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class EmployeeServiceTest2 {
//对 NamedParameterJdbcTemplate 的使用,进行测试
@Autowired
private EmployeeService2 employeeService2;
//添加员工,返回受影响的行数
@Test
public void add() {
Employee emp1 = new Employee(100, "候菲特", 50000);
Integer result1 = employeeService2.add(emp1);
System.out.println(result1);
Employee emp2 = new Employee(101, "任盖茨", 60000);
Integer result2 = employeeService2.add(emp2);
System.out.println(result2);
Employee emp3 = new Employee(102, "李政富", 70000);
Integer result3 = employeeService2.add(emp3);
System.out.println(result3);
}
//修改员工信息,返回受影响的行数
@Test
public void update() {
Employee emp = new Employee(100, "任首富", 80000);
Integer result = employeeService2.update(emp);
System.out.println(result);
}
//获取员工的数量
@Test
public void getEmployeeCount() {
long result = employeeService2.getEmployeeCount();
System.out.println(result);
}
//根据员工 id 查询员工信息
@Test
public void getEmployeeById() {
Employee emp = employeeService2.getEmployeeById(100);
System.out.println(emp);
}
//查询出所有员工,按照id升序排列
@Test
public void selectAll() {
List<Employee> emplist = employeeService2.selectAll();
for (Employee emp : emplist) {
System.out.println(emp);
}
}
//根据条件,查询员工
@Test
public void selectByCondition() {
String name = "任";
int start = 30000;
int end = 60000;
List<Employee> emplist = employeeService2.selectByCondition(name, start, end);
for (Employee emp : emplist) {
System.out.println(emp);
}
}
//传入一个或多个id,删除指定的员工
@Test
public void deleteByIds() {
Integer[] eidArr = new Integer[]{100, 101, 102};
int result = employeeService2.deleteByIds(eidArr);
System.out.println(result);
}
}
到此为止,两种 JdbcTemplate 的使用方式已经介绍完毕,非常简单,本 Demo 的源代码已经详细测试,没有任何问题。
在实际开发中强烈推荐使用 NamedParameterJdbcTemplate 工具类。
本 Demo 的源代码下载地址为:https://files.cnblogs.com/files/blogs/699532/Spring_JdbcTemplate.zip

 浙公网安备 33010602011771号
浙公网安备 33010602011771号