快速掌握 Polly 组件的使用
最近这几年,国内互联网又创造出了一个高大尚的装逼名词:服务治理,让很多程序员初次听到后,感觉到一阵 高深莫测 玄幻懵逼(其实这是我个人在初次被面试时,被问道这个名词时的感觉),其实当我们把 服务治理 这个名词改为 服务管理 的话,大家就能够瞬间明白其本质和含义了。下面我们就继续使用 服务治理 这个名词,来介绍和分享开发技术吧。
一、服务治理简介
以目前流行的微服务架构为例,来介绍什么是服务治理。
首先我们需要明确什么情况下,需要进行服务治理?对于一个服务来说,如果它承担的业务职责比较简单,那么对其治理的必要性就不大,因为服务运行过程是相对透明的,即使出现问题也能很快发现、定位、回滚。只有当服务承担的业务职责变多、变大、变的越来越重要,服务治理才会变得很有必要。
对于单体结构的服务,服务治理的挑战更多是当单体架构由于承载的业务庞大,服务内部逻辑变得复杂,扩展性也变差。这时候往往不需要特别的服务治理手段,而是将单体服务拆分为微服务即可,也就是将原有单体服务架构向微服务架构转化。
对于微服务架构,由于服务数量众多,依赖关系复杂,且部署在不同的服务器上,因此管理和维护变得很困难。我们就必须要想办法进行管理控制,那么需要从哪些方面进行治理呢?
-
服务注册与发现:单体服务拆分为微服务后,如果微服务之间存在调用依赖,就需要得到目标服务的服务地址,也就是微服务治理的”服务发现“。要完成服务发现,就需要将服务信息存储到某个载体,载体本身即是微服务治理的”服务注册中心“,而存储到载体的动作即是”服务注册“。
-
运行可监控性:微服务部署在不同的服务器上,我们需要对众多服务间的调用关系、状态有清晰的掌控,包括调用拓扑关系、各服务节点运行存活状态、日志收集分析、异常调用追踪,网络实况监控等。
-
流量可控性:由于在不同的时间段,各个微服务的使用率不同,因此需要对不同的微服务进行限流和扩容。另外微服务本身存在不同版本,在版本更迭过程中,需要对微服务间调用流量进行控制,以完成微服务版本更迭的平滑,比如灰度发布。
-
安全可控性:不同微服务承载业务职责的重要性不同,对于基础服务,需要进行高可用保障,以及防攻击反制,对于业务敏感的微服务,需要进行权限身份验证等等。
对于微服务治理,传统的做法都是需要引入微服务开发框架,配合控制平台完成如上服务治理能力的建设。比如 .NET 常见的微服务开发框架有 Abp vNext,Java 有 Spring Cloud、Dubbo 等。
二、Polly 组件介绍
Polly 是第三方专门针对 .NET 研发的一种具有弹性的瞬时故障处理类库,它能够使开发人员以简单高效和线程安全的方式,采用不同的策略,发现和处理服务故障,是 .NET 服务治理框架中不可或缺的重要一环。
Polly 官网地址为:https://github.com/App-vNext/Polly (建议大家有空的话,可以去看看)
Polly 组件的处理策略分为两大类:被动处理策略 和 主动应对策略。
被动处理策略 有 重试、熔断、回滚。主动处理策略 有 超时,限流、缓存。
无论使用哪种策略,使用 Polly 的基本步骤,都是分为两步:
1 定义处理异常的策略,2 使用策略执行核心代码。
下面我们就针对这 6 种策略,分别简单的介绍一下常用方式吧,主要是起到一个抛砖引玉的效果。
下面我们就使用 .NET5 的控制台程序进行演示,首先需要通过 Nuget 安装 Polly 组件,如下图所示:
另外需要注意的是:限于篇幅,这里只展示最常使用的样例,更多使用方法请查看官网。
2.1 重试策略
我们在生产环境中,经常会由于高峰期网络带宽问题,服务器自身能够承受的请求并发数等原因,导致瞬时偶发性请求失败问题,
此时采用重试策略,能够在一定程度上有效解决绝大部分问题。
对于重试策略,我们经常调用的是 WaitAndRetry (等待一定的时间后再进行重试),下面我们就介绍一下这种使用方式:
//定义策略
//请求失败后,再请求 2 次
RetryPolicy policy = Policy.Handle<Exception>()
.WaitAndRetry(new[]
{
//重试第一次:过 1 秒后请求
TimeSpan.FromSeconds(1),
//如果第一次重试失败,则再过 2 秒后重试第二次
TimeSpan.FromSeconds(2)
},
(exception, timeSpan) =>
{
//每次重试前,都先执行一次这里的代码,这里打印出相隔时间和异常信息
//这里的 exception 是上次执行时抛出的异常对象
Console.WriteLine($"timespan:{timeSpan},exception:{exception.Message}");
});
//重试机制执行的代码,必须要用 try catch 进行包裹
try
{
policy.Execute(() =>
{
using (WebClient wc = new WebClient())
{
string fileurl = $"https://www.baidu.com/test.jpg";
wc.DownloadFile(fileurl, @"c:\aaa.jpg");
Console.WriteLine("下载成功");
}
});
}
catch (Exception ex)
{
Console.WriteLine($"重试用完后打印的失败信息:{ex.Message}");
}
运行结果如下图所示:

可以看到一共请求了 3 次,前两次打印信息是由 policy 中定义的重试前要执行的代码打印的,
最后一次打印信息是由 catch 中的代码打印的。
2.2 熔断策略
当 A 服务调用 B 服务,但是 B 服务由于某种原因已经崩溃时,最好的处理方案就是在一段时间内不再调用 B 服务,A 服务直接返回异常信息,这样有利于快速响应,避免造成请求积压而导致 A 服务也崩溃,从而造成更大面积的崩溃连锁反应。过一段时间后,A 服务可以再次尝试请求 B 服务,验证 B 服务的可用性,如果可用则恢复调用关系,反之则继续维持不调用,这就是熔断策略。
结合上面对熔断的描述,我们发现熔断策略有 3 种状态:
- 正常状态:A 服务的每次请求都可以按照预期正常调用 B 服务。
- 熔断状态:A 服务在一段时间内,不再主动调用 B 服务,而是本身直接返回异常信息。
- 半熔断状态:熔断时间结束后,A 服务中仅有一个请求被允许尝试调用 B 服务(其它请求则继续熔断),如果请求成功,则 A 服务的所有请求都可以正常请求 B 服务(恢复到正常状态),否则继续开始新的一段时间的熔断状态。
我们在实际应用场景中,使用最多的是高级熔断机制(AdvancedCircuitBreaker),下面我们就介绍一下这种使用方式:
// 2 秒内,只要发起大于等于 5 次请求,如果失败率达到 80%,则发生熔断,熔断持续时间为 1 秒,
// 1 秒过后进行半熔断测试,如果请求成功,则恢复正常,否则继续熔断
CircuitBreakerPolicy policy = Policy.Handle<Exception>()
.AdvancedCircuitBreaker(0.8, TimeSpan.FromSeconds(2), 5, TimeSpan.FromSeconds(2),
(ex, ts) =>
{
//发生熔断时,执行此处的代码
Console.WriteLine($"{DateTime.Now} 发生了熔断:{ex.Message}");
},
() =>
{
//恢复正常时,执行此处的代码
Console.WriteLine($"{DateTime.Now} 完全恢复了");
},
() =>
{
//进行半熔断尝试请求
Console.WriteLine($"{DateTime.Now} 半熔断了");
});
for (int i = 0; i < 50; i++)
{
//熔断机制执行的代码,必须要用 try catch 进行包裹
try
{
policy.Execute(() =>
{
//故意抛出异常错误
throw new Exception($"序号{i}故意抛出异常错误");
});
}
catch (Exception ex)
{
Console.WriteLine($"{DateTime.Now} 序号{i}处理异常:{ex.Message}");
}
System.Threading.Thread.Sleep(100);
}
运行结果如下图所示:
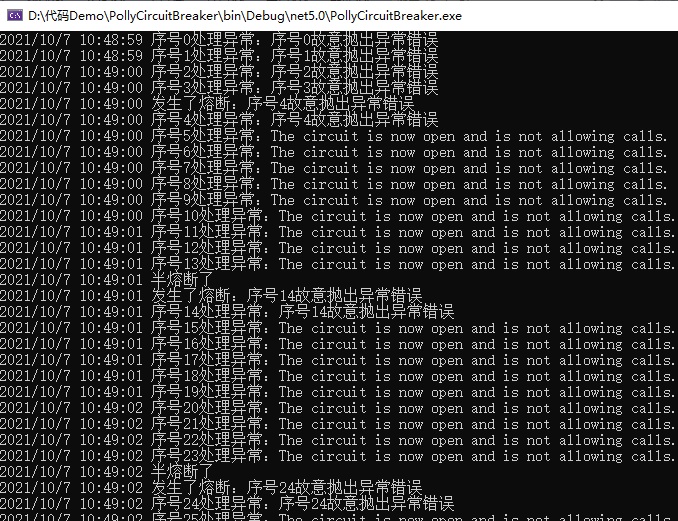
可以看到虽然我们设置的是 2 秒内请求 5 次,如果 80% 失败(也就是 4 次失败),就发生熔断,但实际上我们差不多 1 秒就达到了所设置条件的阈值,从而发生熔断 1 秒的效果,1 秒后进行半熔断尝试,没有成功,所以就继续进行触发新的 1 秒钟的熔断效果。
2.3 回滚策略
这种策略在名称上容易让大家跟回滚数据产生混淆,实际上它是当错误发生时,采用一个默认值或默认处理方案进行代替,我本人喜欢把这种机制叫做 默认值策略,我觉得这样的称呼比较直观,不容易让人产生混淆。下面我们就介绍一下这种使用方式:
假如我们请求一个接口,接口会返回 json 数据,包含状态码和描述信息,
如果接口无法调用的话,我们就直接返回一个默认的 json 字符串(状态码为 99),代码如下:
//定义策略
FallbackPolicy<string> policy = Policy<string>.Handle<Exception>()
.Fallback(JsonConvert.SerializeObject(new { status = 99, msg = "unknown error" }),
(result, context) =>
{
//当触发回滚机制时,先执行此处的代码
Console.WriteLine($"异常信息:{result.Exception.Message}");
});
//回滚机制执行的代码,不需要用 try catch 包裹。
string result = policy.Execute(() =>
{
throw new Exception("故意抛出异常");
});
Console.WriteLine($"返回结果为:{result}");
运行结果如下图所示:

可以看到当执行代码出错时,返回了回滚策略中所定义的默认值。
其实我个人感觉这种回滚策略,貌似没啥太大的用处,我们平时使用 try catch 代码就可以实现了,代码如下所示:
string result;
try
{
throw new Exception("故意抛出异常");
}
catch(Exception ex)
{
result = = JsonConvert.SerializeObject(new { status = 99, msg = "unknown error" });
Console.WriteLine($"异常信息:{result.Exception.Message}");
}
Console.WriteLine($"返回结果为:{result}");
2.4 超时策略
这种策略很容易理解,但是使用起来却并不是那么方便。
超时策略分为乐观超时和悲观超时,如果代码在执行过程中,可以通过人工干预实现取消执行,则为乐观超时,否则就是悲观超时。
乐观超时可以通过传入的 CancellationToken 是否为 true 来决定是否取消执行。我们还是通过代码来介绍吧:
1 乐观超时 demo
//设置超时时间为 2 秒
TimeoutPolicy policy = Policy.Timeout(2, TimeoutStrategy.Optimistic,
(context, timespan, task) =>
{
//当代码执行超时发生时,先执行这里的代码
Console.WriteLine($"代码执行超时了 {timespan.TotalSeconds} 秒");
});
//超时策略执行的代码,需要使用 try catch 包裹
try
{
//实例化一个 CancellationToken ,乐观超时的执行,需要传入这个参数
//当代码执行超时后,策略会自动给该实例的 IsCancellationRequested 赋值为 true
CancellationToken ct = new CancellationToken();
policy.Execute((canceltoken) =>
{
for (int i = 0; i < 1000; i++)
{
//这里可以编写执行业务逻辑的代码
.....
//可以根据不断检测这个状态是否为 true,来决定是否取消代码执行
//2 秒后 canceltoken.IsCancellationRequested 自动变为 True
if (canceltoken.IsCancellationRequested)
{
//这里有机会可以编写取消执行的业务逻辑代码
......
//使用该方法抛出超时异常,从而终止循环,触发超时策略定义的方法执行
canceltoken.ThrowIfCancellationRequested();
}
else
{
Console.WriteLine(canceltoken.IsCancellationRequested);
System.Threading.Thread.Sleep(1000);
}
}
}, ct);
}
catch (Exception ex)
{
Console.WriteLine($"catch中的异常信息:{ex.Message}");
}
运行结果如下图所示:
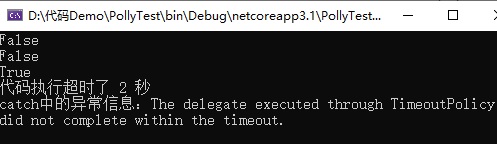
从上面的代码和执行结果可以看出:乐观超时策略,必须通过人工的方式来取消代码执行。通过循环判断所传入的 CancellationToken 中的属性 IsCancellationRequested 为 true 时,来决定进行代码取消执行。
2 悲观超时 demo
//设置超时时间为 2 秒
TimeoutPolicy policy = Policy.Timeout(2, TimeoutStrategy.Pessimistic,
(context, timespan, task) =>
{
//当代码执行超时发生时,先执行这里的代码
Console.WriteLine($"代码执行超时了 {timespan.TotalSeconds} 秒");
});
//超时策略执行的代码,需要使用 try catch 包裹
try
{
policy.Execute(() =>
{
for (int i = 0; i < 10; i++)
{
Console.WriteLine(DateTime.Now);
System.Threading.Thread.Sleep(1000);
}
Console.WriteLine("代码执行完成");
});
}
catch (Exception ex)
{
Console.WriteLine($"catch中的异常信息:{ex.Message}");
}
运行结果如下图所示:
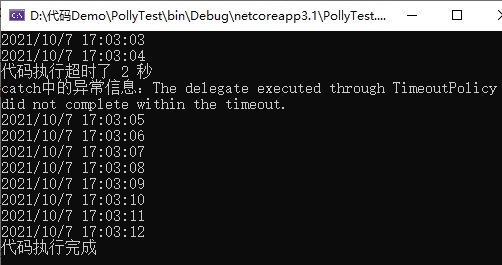
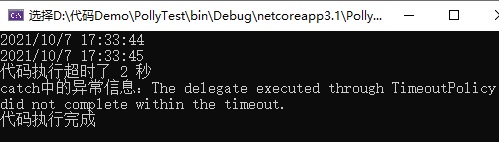
从上面的代码和运行结果可以看出:悲观超时策略,代码执行后,如果达到执行的超时时间后,会自动触发超时异常,但是不会取消代码的执行,代码会一直执行的结束。这一点在某些情况下可能不太好,我们可以通过一个 bool 变量进行改进。
3 悲观超时 demo 改进(自己闲着没事想干些无聊的事情)
//设置超时时间为 2 秒
TimeoutPolicy policy = Policy.Timeout(2, TimeoutStrategy.Pessimistic,
(context, timespan, task) =>
{
//当代码执行超时发生时,先执行这里的代码
Console.WriteLine($"代码执行超时了 {timespan.TotalSeconds} 秒");
});
bool stopflag = false;
//超时策略执行的代码,需要使用 try catch 包裹
try
{
policy.Execute(() =>
{
for (int i = 0; i < 10; i++)
{
if(stopflag)
{
break;
}
Console.WriteLine(DateTime.Now);
System.Threading.Thread.Sleep(1000);
}
Console.WriteLine("代码执行完成");
});
}
catch (Exception ex)
{
stopflag = true;
Console.WriteLine($"catch中的异常信息:{ex.Message}");
}
运行效果如下图所示:
2.5 限流策略
限流策略是指限制并发执行的线程数量以及排队等待执行的线程数量,我们经常会遇到这种场景:开发好的 api 接口放到生产环境上供别人调用,由于在某个时间调用的过于频繁,导致 api 接口宕机。我们就可以采用限流策略进行代码改进,针对每个用户或者每个 ip 等进行并发请求限制,下面我们就看具体的代码吧:
//限制最多 2 线程并发执行,等待队列中最多 3 个线程等待
BulkheadPolicy policy = Policy.Bulkhead(2, 3,
(context) =>
{
//当并发线程和等待队列都达到最大值时,先执行此处的代码
Console.WriteLine("并发线程和等待队列超过了最大限制...");
});
//模拟在同一时间内,有 10 个线程并发执行代码
for (int i = 0; i < 10; i++)
{
Task.Run(() =>
{
//限流策略要执行的代码,必须用 try catch 进行包裹
try
{
policy.Execute(() =>
{
Console.WriteLine($"正常执行,{DateTime.Now}");
Thread.Sleep(1000);
});
}
catch (Exception ex)
{
Console.WriteLine($"catch中的异常信息:{ex.Message}");
}
});
}
运行效果如下图所示:
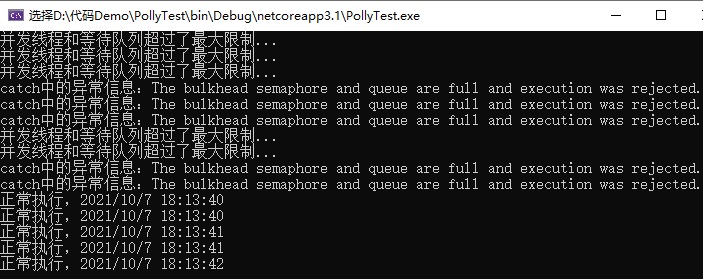
从上面的代码和执行的结果可以看出:虽然同时有 10 个并发线程要执行代码,但是由于限流策略是最多允许 2 个并发线程,等待队列中最多有 3 个线程,所以最终只能有 5 个线程执行成功,其它线程都直接抛出异常。
2.6 缓存策略
缓存的作用,这里就不需要过多介绍了,Polly 组件支持缓存,这里了解一下即可,因为我们在实际场景中可能很少使用。
首先需要 Nuget 安装 Polly.Caching.Memory 和 Microsoft.Extensions.Caching.Memory 这俩包,代码如下:
MemoryCache mc = new MemoryCache(new MemoryCacheOptions());
MemoryCacheProvider mcp = new MemoryCacheProvider(mc);
//缓存有效期为 2 秒钟
CachePolicy policy = Policy.Cache(mcp, TimeSpan.FromSeconds(2));
for (int i = 0; i < 10; i++)
{
string cachevalue = policy.Execute(
(context) =>
{
//context.CorrelationId 为执行id,系统为每次执行生成唯一的id
//通过查看执行id,就知道是否使用了缓存,
//如果没有使用缓存的话,每次执行id 都是不同的。
Console.WriteLine($"执行id:{context.CorrelationId}");
return DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss.fff");
}, new Context("cachekey"));
Console.WriteLine($"{DateTime.Now} 第{i}次返回值:{cachevalue}");
Thread.Sleep(1000);
}
运行效果如下图所示:
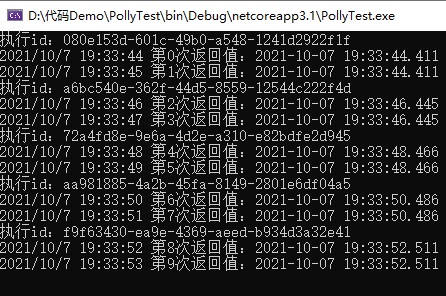
从上面的代码和执行的结果可以看出:两秒钟内都是线程的执行过程,直接返回缓存中的时间值。
2.7 组合策略
以上已经简单介绍了 Polly 组件的 6 种策略,其实可以对这 6 种策略根据实际情况,组合在一起使用。比如我们在实际工作中,可能会遇到这样的场景:向对方推送消息,推送者期望 500 毫秒内获得响应,如果超时的话,那就重复推送一次,代码如下:
//这里把 悲观超时策略 和 重试策略 组合在一起使用
//第一次请求失败后,再重新请求一次
RetryPolicy retryPolicy = Policy.Handle<Exception>()
.WaitAndRetry(new List<TimeSpan> { TimeSpan.FromSeconds(1) },
(exception, timespan) =>
{
Console.WriteLine($"timespan:{timespan},触发了重新推送,异常信息为:{exception.Message}");
});
TimeoutPolicy timeoutPolicy = Policy.Timeout(TimeSpan.FromMilliseconds(500),
TimeoutStrategy.Pessimistic,(context, timespan, task) =>
{
Console.WriteLine($"timespan:{timespan},推送代码执行超时了 {timespan.TotalSeconds} 秒");
});
PolicyWrap policywrap = Policy.Wrap(retryPolicy, timeoutPolicy);
try
{
policywrap.Execute(() =>
{
Console.WriteLine($"{DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss.fff")} 向对方推送消息");
Thread.Sleep(1500);
});
}
catch (Exception ex)
{
Console.WriteLine($"catch中的异常信息:{ex.Message}");
}
运行效果如下图所示:
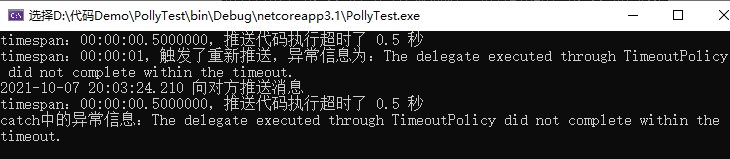
从上面的代码和执行的结果可以看出:执行代码时,超过了 500 毫秒,触发了重新执行,然后又执行了一次代码。
到此为止,Polly 组件的各种使用方式,已经简单介绍完了,大家在工作中根据实际情况,结合自身的业务场景,合理利用即可。还是那句话: 限于篇幅,这里只展示最常使用的样例,更多使用方法请查看官网。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号