小爬爬6: 网易新闻scrapy+selenium的爬取
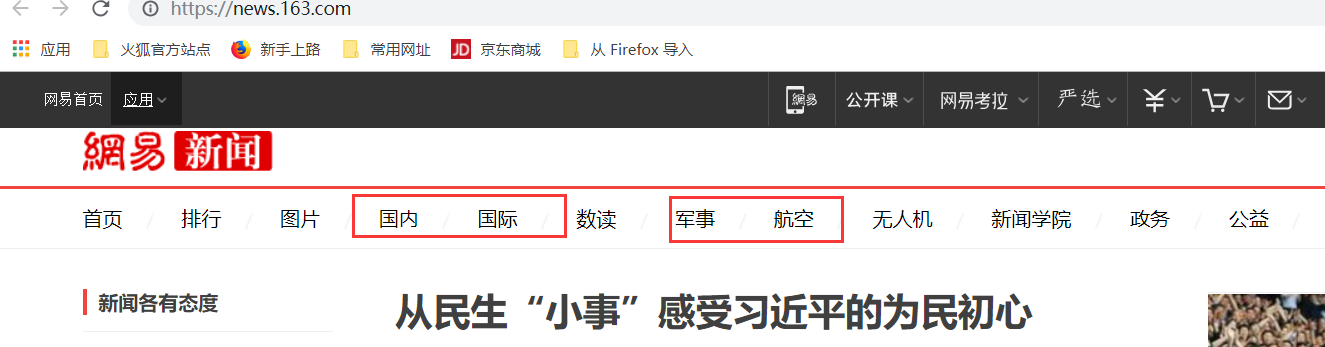
国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件
2.
我们可以查看到"国内"等板块的位置
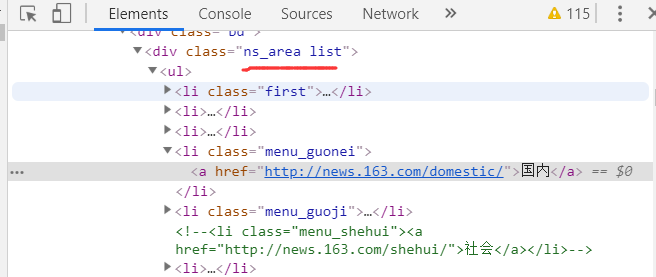

新建一个项目,创建一个爬虫文件
下面,我们进行处理:
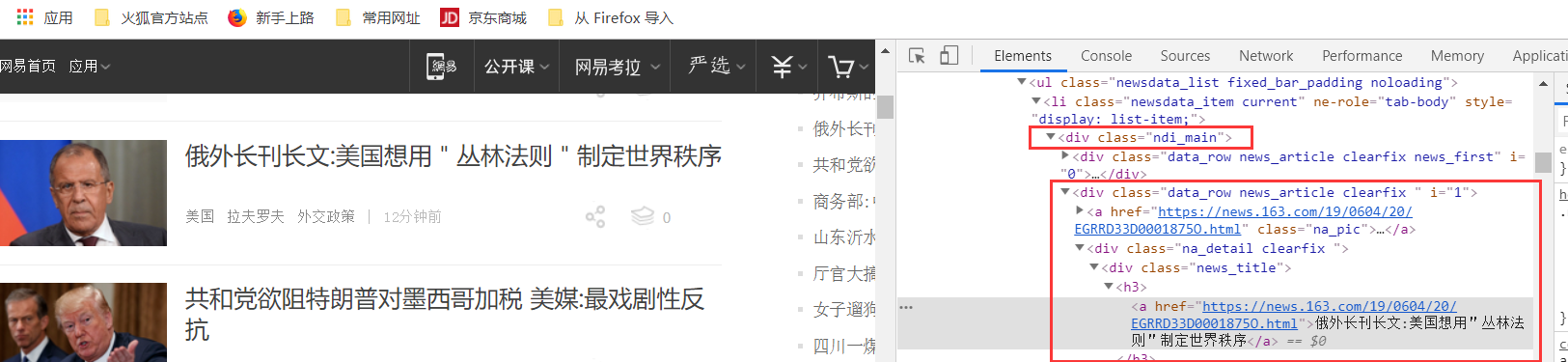
仔细查找二级标签的位置:
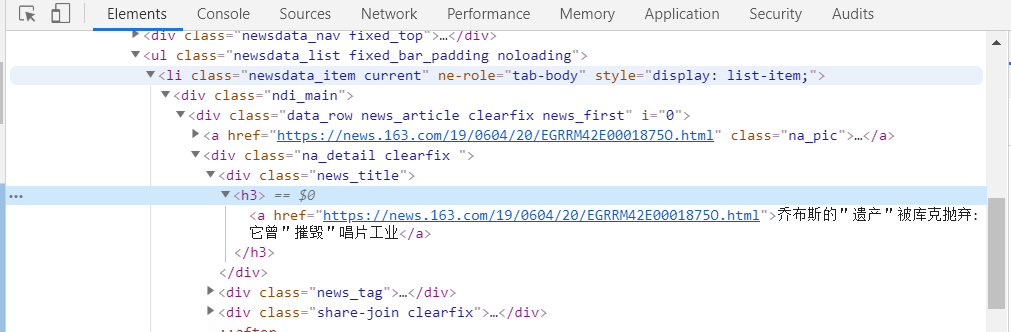
每一段的信息都储存在p标签内部
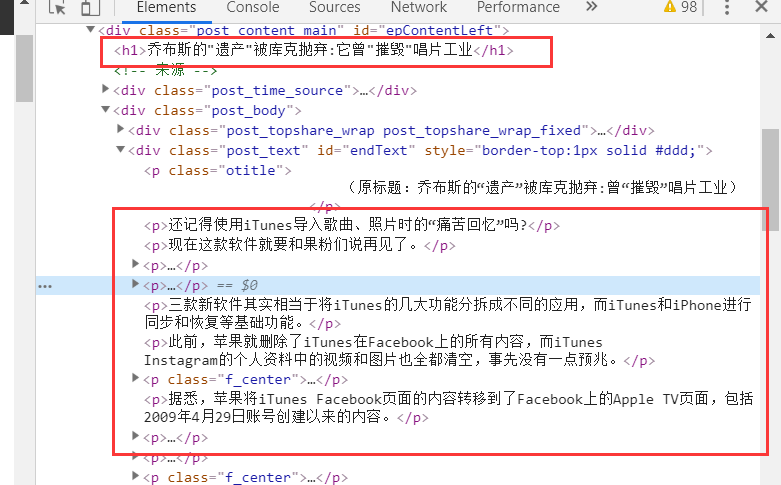
items.py写两个字段
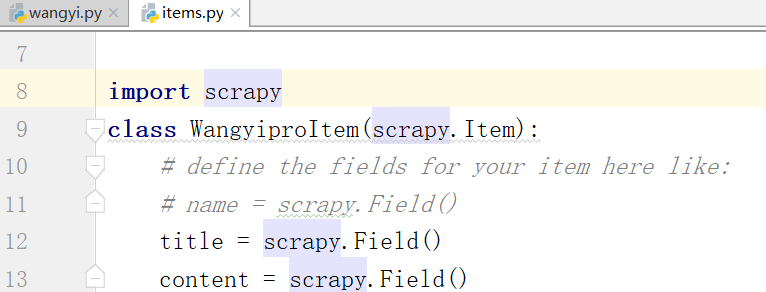
导入下面的内容:
爬虫文件wangyi.py
# -*- coding: utf-8 -*- import scrapy from wnagyiPro.items import WangyiproItem class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] def parse(self, response): li_list=response.xpath('//div[@class="ns_area"]/ul/li') #拿到列表中的34678 for index in [3,4,6,7,8]: li=li_list[index] new_url=li.xpath('./a/@href').extract_first() #是五大版块对应的url进行请求发送 yield scrapy.Request(url=new_url,callback=self.parse_news) #解析每个版块对应的数据 #是用来解析每一个版块对应的新闻数据(新闻的标题) def parse_news(self,response): div_list=response.xpath('//div[@class="ndi_main"]/div') for div in div_list: title=div.xpath("./div/div[1]/h3/a/text()").extract_first() news_detail_url=div.xpath("./div/div[1]/h3/a/@href").extract_first() #实例化item对象将解析到的标题和内容存储到item对象中 item=WangyiproItem() item['title']=title #对详情页的url进行手动请求发送一遍回去新闻的内容 yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response): item=response.meta['item'] #信息的传递 #通过response解析出新闻的内容 content=response.xpath('//div[@id="endText"]//text()').extract() content=''.join(content) item['content']=content yield item
我们可以在管道中打印一下item
下面再在配置文件中开启管道


现在,我们存在的问题就是,没有动态加载出来的数据,怎么处理?
响应对象存在问题,我们需要修改,五大板块对应的响应对象,其他不需要修改,下面我们处理中间件文件
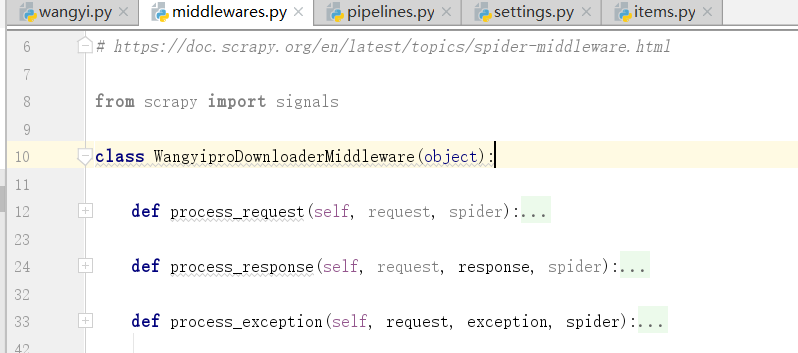
我们只需要保留这一个类中的三个process方法即可
我们需要对第一个页面中进行修改
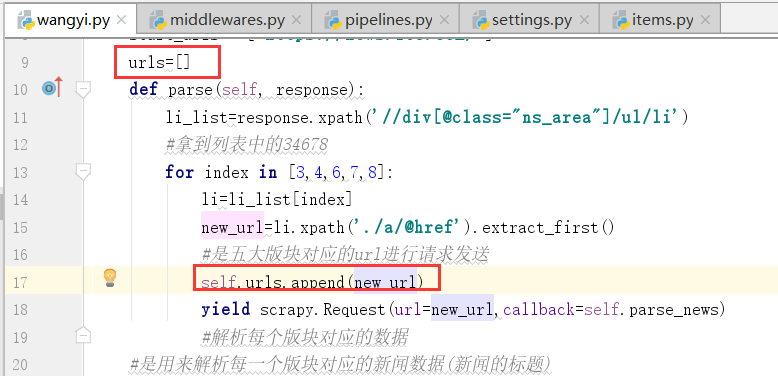
#上边的urls列表最终存放的就是五大板块对应的url
我们需要在中间件写新的response需要在爬虫文件继续写内容
开启中间件:

君子协定修改成False,

下面开始执行爬虫

重新复制首页的xpath
//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div
出现下面的错误需要进行修改下面的方法:

爬虫文件wangyi.py内容:
# -*- coding: utf-8 -*- import scrapy from wangyiPro.items import WangyiproItem from selenium import webdriver class WangyiSpider(scrapy.Spider): name = 'wangyi' # allowed_domains = ['www.xxx.com'] start_urls = ['https://news.163.com/'] #浏览器实例化的操作只会被执行一次 bro=webdriver.Chrome(executable_path='chromedriver.exe') urls=[] #最终存放的就是五个板块对应的url def parse(self, response): li_list=response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li') #拿到列表中的34678 for index in [3,4,6,7,8]: li=li_list[index] new_url=li.xpath('./a/@href').extract_first() #是五大版块对应的url进行请求发送 self.urls.append(new_url) yield scrapy.Request(url=new_url,callback=self.parse_news) #解析每个版块对应的数据 #是用来解析每一个版块对应的新闻数据(新闻的标题) def parse_news(self,response): div_list=response.xpath('//div[@class="ndi_main"]/div') for div in div_list: title=div.xpath("./div/div[1]/h3/a/text()").extract_first() news_detail_url=div.xpath("./div/div[1]/h3/a/@href").extract_first() #实例化item对象将解析到的标题和内容存储到item对象中 item=WangyiproItem() item['title']=title #对详情页的url进行手动请求发送一遍回去新闻的内容 yield scrapy.Request(url=news_detail_url,callback=self.parse_detail,meta={'item':item}) def parse_detail(self,response): item=response.meta['item'] #信息的传递 #通过response解析出新闻的内容 content=response.xpath('//div[@id="endText"]//text()').extract() content=''.join(content) item['content']=content yield item def closed(self,spider): #关闭 print('爬虫整体结束!!!') self.bro.quit()
中间件中的处理:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from scrapy.http import HtmlResponse from time import sleep class WangyiproDownloaderMiddleware(object): def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None #拦截整个工程中所有的响应对象,一请求对应一响应 def process_response(self, request, response, spider): if request.url in spider.urls: #就要将其对应的响应对象进行处理 #获取了在爬虫类中定义号的浏览器对象 bro=spider.bro #包含动态加载出来的数据 bro.get(request.url) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) #获取携带了新闻数据的页面源码数据 page_text=bro.page_source #spider.bro.current_url==request.url new_response=HtmlResponse(url=request.url,body=page_text,encoding='utf-8',request=request) return new_response else: return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass

网易需求:
1.爬取五大板块对应的新闻
2.爬取新闻标题和内容,将数据存储到mysql 数据库中
3.创建一个表,三列id,title,content
4.notype可能是在解析标题时候出现的错误
scrapy中应用selenium的编码流程: - 爬虫类中定义一个属性bro - 爬虫类中重写父类的一个方法closed,在该方法中关闭bro - 在中间件类的process_response中编写selenium自动化的相关操作
关键字的 提取:
百度AI:分类
点击控制台:
自然语言处理===>技术文档===>
对关键字进行处理
第四keyword&&第五是分类
其实是个时间的问题.
有时间再搞.(答辩)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号