小爬爬6.scrapy回顾和手动请求发送
1.数据结构回顾
#栈
def push(self,item)
def pop(self)
#队列
def enqueue(self,item)
def dequeue(self)
#列表
def add(self,item)
2.回顾scrapy
- 创建工程:scrapy startproject ProName - 创建爬虫文件 - cd ProName - scrapy genspider spiderName www.xxx.com - 爬虫类的相关属性和方法 - 爬虫文件的名称:name #这里不能重复 - 起始的url列表:start_urls,存储的url会被scrapy进行自动的请求发送 - parse(reponse):用来解析start_urls列表中url对应的响应数据,会被调用多次 - response.xpath() ==> [selector,selector] - extract() - 数据持久化存储 - 基于终端指令: - 只可以将parse方法的返回值进行持久化存储 - scrapy crawl SpiderName -o ./file - 基于管道持久化存储的编码流程:重点 - 数据解析 - 在item类中声明相关的属性用于存储解析到的数据 - 将解析到的数据存储封装到item类型的对象中 - 将item对象提交给管道类 - item会被管道类中的process_item方法中的item参数进行接收 - process_item方法中编写基于item持久化存储的操作 - 在配置文件中开启管道 - 管道细节处理: - 管道文件中一个类对应的是什么? - 一个类表示的是将解析到的数据存储到某一个具体的平台数据库或txt中 - process_item方法中的返回值表示什么含义? - return item就是说将item传递给下一个即将被执行的管道类 - open_spider,close_spider
3.手动请求发送
阳光热点问政平台:http://wz.sun0769.com/index.php/question/questionType?type=4

我们不能将每个url都放在start_urls中
如何和实现全站数据的爬取?定位到某个板块将所有的数据都爬取到
起始页码:http://wz.sun0769.com/index.php/question/questionType?type=4&page=
下面我们新建一个工程:

走到day6里边,创建一个工程,走到工程内容,下面我们创建一个爬虫文件

下面我们需要settings进行伪装和robot修改

下面打开爬虫文件:注释 allowed_domains
写入起始url,下面解析数据当前页码数据
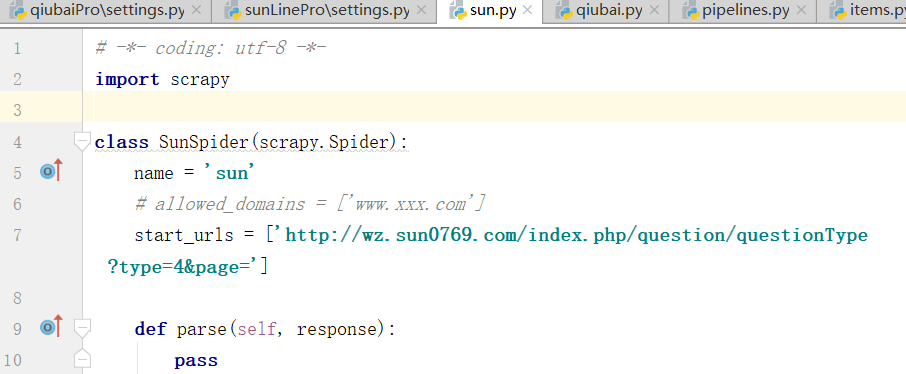
下面,我们进行解析,在parse函数中
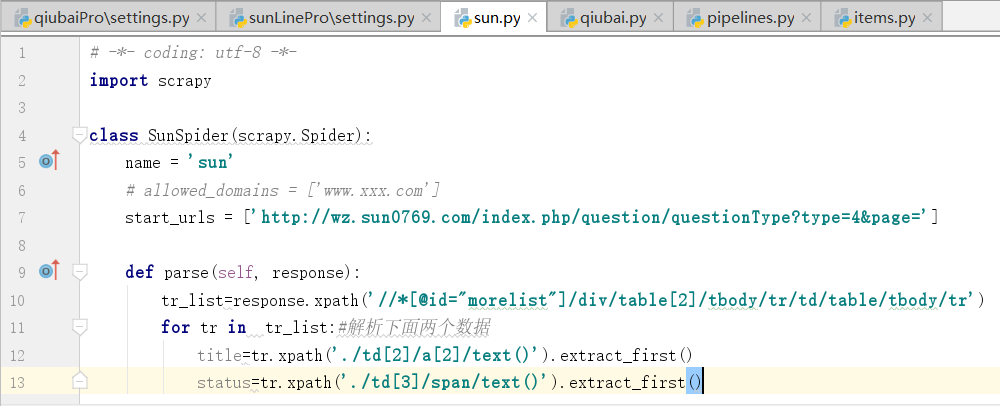
复制第二个xpath作为解析url,再加上一个tr
下面,我们拿一下标题

下面我们再items写我们需要存储的字段:
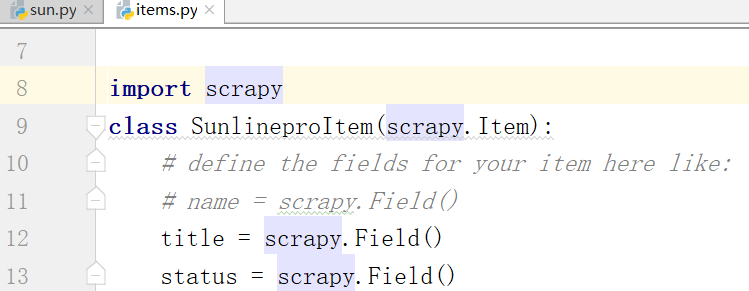
导入包:
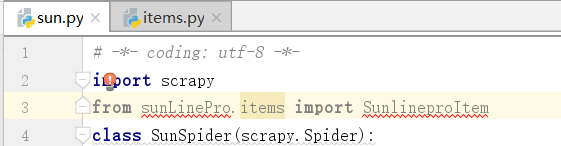
sun.py爬虫文件
# -*- coding: utf-8 -*- import scrapy from sunLinePro.items import SunlineproItem class SunSpider(scrapy.Spider): name = 'sun' # allowed_domains = ['www.xxx.com'] start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page='] def parse(self, response): tr_list=response.xpath('//*[@id="morelist"]/div/table[2]/tbody/tr/td/table/tbody/tr') for tr in tr_list:#解析下面两个数据 title=tr.xpath('./td[2]/a[2]/text()').extract_first() status=tr.xpath('./td[3]/span/text()').extract_first() item=SunlineproItem() item['title']=title item['status']=status yield item #提交的操作在循环的里边
每提交一次,pipelines.py文件里边的process_item函数就会执行一次
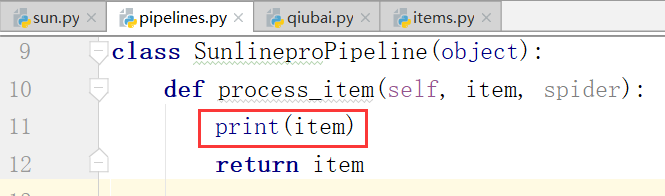
下面,我们再settings.py的配置文件中打开管道:
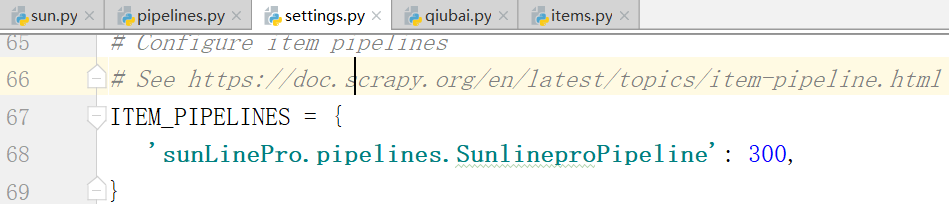
下面,看一下能不能解析出首页的内容.
现在配置文件中写log_error,只有错误的时候打印
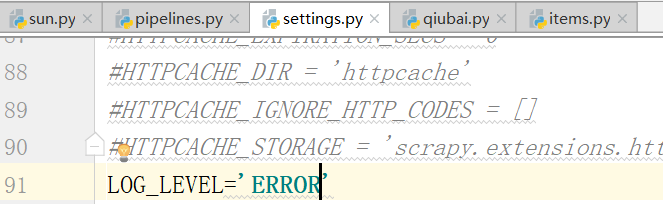
没有错误,也就是没有解析到数据,因此我们需要修改xpath,存在问题的形式tbody
下面是修改之后的内容

执行爬虫文件,也就是这个工程
![]()
这个时候,已经能够拿到数据了
我们现在拿到的是当前页中的内容.
我们看一下第二页和第三页中的url
http://wz.sun0769.com/index.php/question/questionType?type=4&page=30
http://wz.sun0769.com/index.php/question/questionType?type=4&page=60
我们看到了这个文件中后边的参数发生了改变
sun.py文件
# -*- coding: utf-8 -*- import scrapy from sunLinePro.items import SunlineproItem class SunSpider(scrapy.Spider): name = 'sun' # allowed_domains = ['www.xxx.com'] start_urls = ['http://wz.sun0769.com/index.php/question/questionType?type=4&page='] #通用的url模板(不可以修改) url='http://wz.sun0769.com/index.php/question/questionType?type=4&page=%d' page=1 def parse(self, response): print(',,,,,,,,,,,,,,page=',self.page) #查看页面 tr_list=response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr') for tr in tr_list:#解析下面两个数据 title=tr.xpath('./td[2]/a[2]/text()').extract_first() status=tr.xpath('./td[3]/span/text()').extract_first() item=SunlineproItem() item['title']=title item['status']=status yield item #提交的操作在循环的里边 if self.page<5: #手动对指定的url进行请求发送 count=self.page*30 new_url=format(self.url%count) self.page+=1 yield scrapy.Request(url=new_url,callback=self.parse) #url和结束递归条件
下面,我们对文件进行处理,执行下面的命令
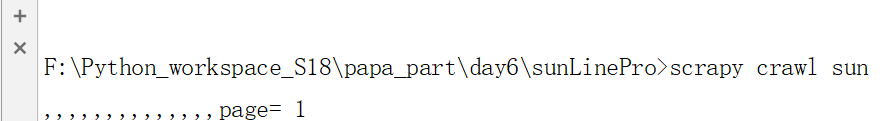
成功打印到了第五页
全栈数据的爬取我们可以进行手动进行数据的发送
总结全站数据的爬取:
全站数据的爬取 - 手动请求发送: - yield scrapy.Request(url,callback):callback回调一个函数用于数据解析
4.get请求,我们怎样用post请求?在scrapy可以用post,但是一般不用,原因比较麻烦
如何进行post请求的发送和如何进行cookie的处理 - post请求的发送: - 重写父类的start_requests(self)方法 - 在该方法内部只需要调用yield scrapy.FormRequest(url,callback,formdata) - cookie处理:scrapy默认情况下会自动进行cookie处理
新建一个项目

新建一个爬虫文件
在配置文件进行修改ua,robot和log_level
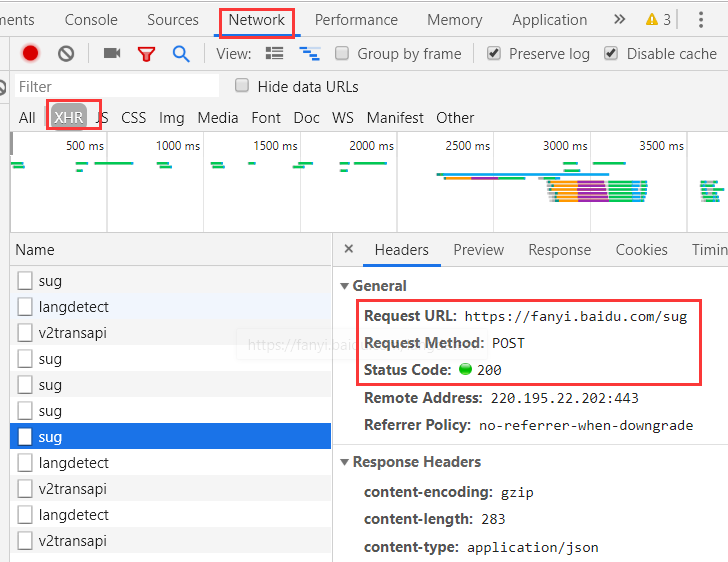
我们得到上边的url
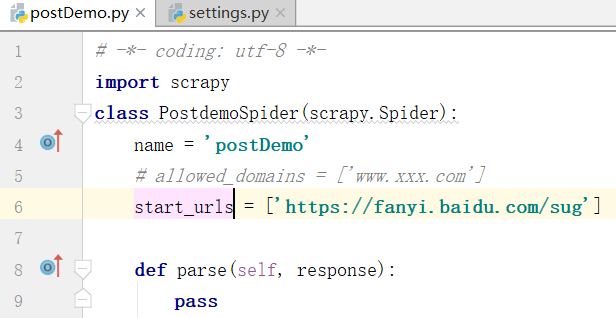
我们看一下这个方法怎样实现?start_requests()
父类方法:就是将start_urls中del列表元素进行get请求的发送
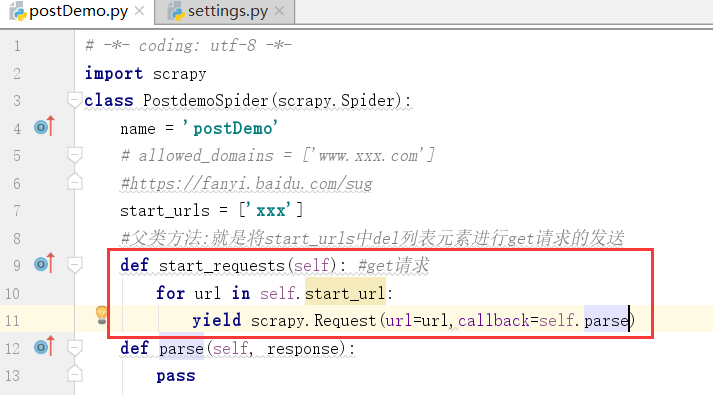
上边是get请求的父类方法,现在我们进行改写

上图是请求的数据
postDemo.py文件
# -*- coding: utf-8 -*-
import scrapy
class PostdemoSpider(scrapy.Spider):
name = 'postDemo'
# allowed_domains = ['www.xxx.com']
#https://fanyi.baidu.com/sug
start_urls = ['https://fanyi.baidu.com/sug']
#父类方法:就是将start_urls中del列表元素进行get请求的发送
def start_requests(self): #get请求
for url in self.start_urls:
data={
'kw':'dog',
}
#post请求的手动发送使用的是FormRequest
yield scrapy.FormRequest(url=url,callback=self.parse,formdata=data)
def parse(self, response):
print(response.text)
运行之后,我们得到狗dog的数据

5.cookie默认是进行存储生效的在scrapy框架中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号