小爬爬1.requests基础操作
1.requests安装的问题
(1)如果requests没有安装,我们需要先安装这个模块,在cmd安装不了,我们可以在下面的位置,打开的窗体安装requests模块
pip install requests
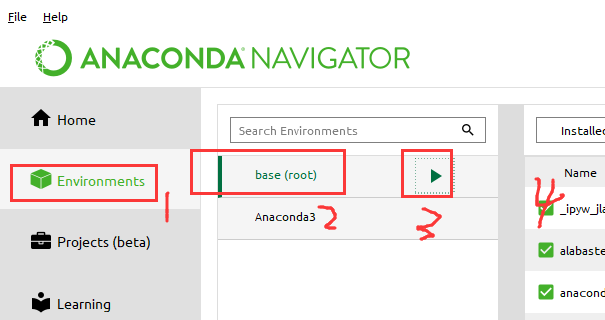
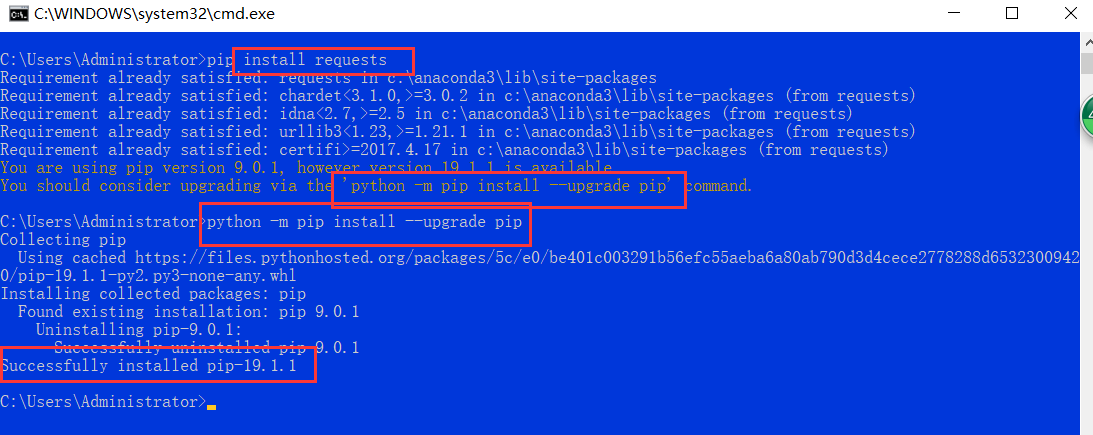
(2)pip要升级注意一下:
2.requests模块&&urllib模块
(1)什么是requests模块?原生的基于网络请求的模块.可以发起网络请求,爬取互联网数据
作用:就是用于模拟浏览器上网的.
缺点:简单,高效
总结:掌握requests详情用法就掌握了爬虫的半壁江山.70%-80%的功能可以实现
原生基于网络请求的模块
(2)old:urllib:比较繁琐
了解怎样用urllib发送请求就可以了.自己查看博客
(3)requests模块的使用流程:
A:指定URL
B:发起请求
C:获取响应数据
D:持久化存储
3.扬帆起航:
需求1:爬取搜狗首页的页面数据:(shift+tab,看一下有哪些参数)
import requests #1.指定url url='https://www.sogou.com/' #2.发起请求 response=requests.get(url=url) # 3.获取响应数据 page_text=response.text #text返回的是字符串类型的数据 print(page_text)
#上边这个测试有问题????
非数据库,文本式持久化处理
#爬取搜狗首页的页面数据 import requests #1.指定url url='https://www.sogou.com/' #2.发起请求 response=requests.get(url=url) # 3.获取响应数据 page_text=response.text #text返回的是字符串类型的数据 #4.持久化存储: with open('./sougou.html','w',encoding='utf-8')as fp: fp.write(page_text) print('over!')
#和上边依然是同样的"时间超时问题",sougou不是这个是sogou
#出来不是我们需要的结果
修改jupyter notebook默认浏览器地址:https://blog.csdn.net/u013985879/article/details/82078993


处理get请求的参数
需求2:网页采集器
注意,原生的url是不能有中文的.
#下边是修改好的,"但是会报错,是否是程序爬取这个页面"
import requests wd=input('enter a word:') url='https://www.sogou.com/web?query' #参数的封装 param={ 'query':wd } response=requests.get(url=url,params=param) #page_text=response.content.decode('utf-8') #这种方式是可以的 response.encoding = 'utf-8' #page_text=response.text #这是一种猜测形式,可能会出错,也就是乱码问题 fileName=wd+'.html' with open(fileName,'w',encoding='utf-8')as fp: fp.write(page_text) print(fileName,'爬取成功!!!')
#手动修改响应数据的编码
import requests wd=input('enter a word:') url='https://www.sogou.com/web' #参数的封装 param={ 'query':wd } response=requests.get(url=url,params=param) #page_text=response.content.decode('utf-8') #这种方式是可以的 #手动修改响应数据的编码 response.encoding = 'utf-8' page_text=response.text #这是一种猜测形式,可能会出错 fileName=wd+'.html' with open(fileName,'w',encoding='utf-8')as fp: fp.write(page_text) print(fileName,'爬取成功!!!')
反爬机制:UA检测,检测你是不是程序爬取我的代码
反反爬策略:UA伪装
下面,我们开始学习伪装
请求之前需要进行伪装:
import requests wd=input('enter a word:') url='https://www.sogou.com/web' #参数的封装 param={ 'query':wd } #UA伪装 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } response=requests.get(url=url,params=param,headers=headers) #page_text=response.content.decode('utf-8') #这种方式是可以的 #手动修改响应数据的编码 #response.encoding = 'utf-8' page_text=response.text #这是一种猜测形式,可能会出错 fileName=wd+'.html' with open(fileName,'w',encoding='utf-8')as fp: fp.write(page_text) print(fileName,'爬取成功!!!')
需求3,破解百度翻译(ajax请求,自动发送)
找到url,发送请求即可
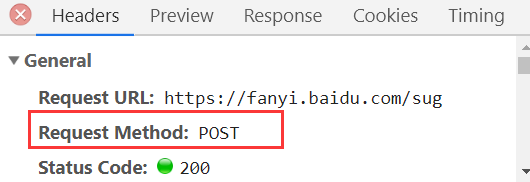
上边的post请求
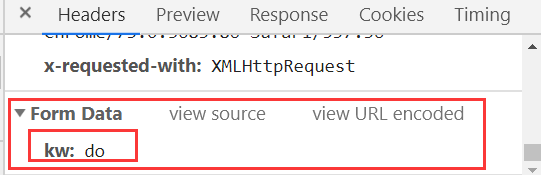
上图是请求的内容
下边是响应的内容.

我们看到了下图中的"响应的数据类型是":"application/json"
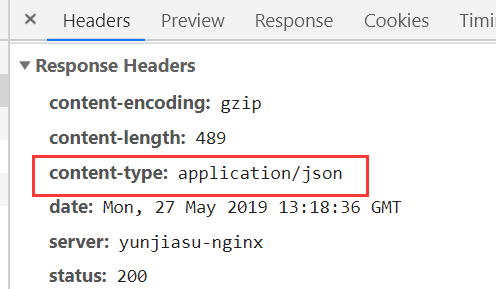
从上图,我们可以明确看到是一个json格式的数据
POST&&ajax,通过ajax请求抓取的数据
#破解百度翻译 import requests url='https://fanyi.baidu.com/sug' word=input('enter a English word:') #请求参数的封装 data={ 'kw':word } #UA伪装,headers是个通用的,不管是get还是post headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } response=requests.post(url=url,data=data,headers=headers) #print(response.text)#字符串形式,返回的是字节码 print(response.json()) #下面返回的是json,可以转换到我们的汉语 #属性text:返回字符串,方法json():对象,返回汉语 obj_json=response.json() print(obj_json) #我们可以进行解析字典 #注意,只有响应对象是一个json形式的才可以进行调用
测试:
1.爬取kfc的餐厅查询数据
http://www.kfc.com.cn/kfccda/storelist/index.aspx
动态加载的ajax请求
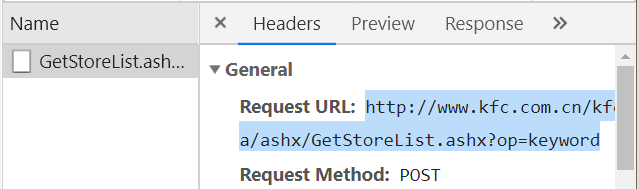
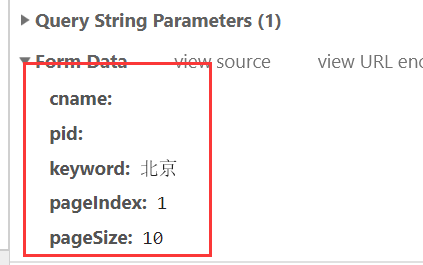
上图是最下边的数据
import requests #爬取惹你城市对应的肯德基餐厅的位置信息 #动态加载的数据 city=input("enter a cityName:") url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' data={ "cname": "", "pid": "" , #什么都没有就设置成空字符串 "keyword": city, "pageIndex": "1", #作业1:一共有八页,我们怎样循环打印出来?,现在我们只能打印出一页来 "pageSize": "10", } #UA伪装,headers是个通用的,不管是get还是post headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } response=requests.post(url=url,data=data,headers=headers) json_text=response.text print(json_text)
爬取北京肯德基所有的餐厅位置信息(1-8页)
#下面的for循环,写的有点low
import requests #爬取惹你城市对应的肯德基餐厅的位置信息 #动态加载的数据 city=input("enter a cityName:") url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' for i in range(1,9): data={ "cname": "", "pid": "" , #什么都没有就设置成空字符串 "keyword": city, "pageIndex": "1", "pageSize": "10", } #UA伪装,headers是个通用的,不管是get还是post headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } response=requests.post(url=url,data=data,headers=headers) json_text=response.text print(json_text)
2.爬取豆瓣电影中更多的电影数据的详情?
https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=17&interval_id=100:90&action=

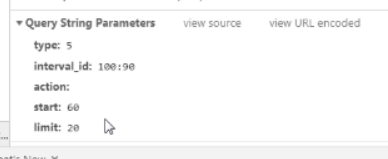
start指的是开始的位置,limit表示一次取多少
获取更多的数据?
import requests #爬取惹你城市对应的肯德基餐厅的位置信息 #动态加载的数据 start_num=input("enter a start_num:") limit_num=input("enter a limit_num:") url='https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20' data={ "type": "17", "interval_id": "100:90", "action":"", "start": start_num, #输入0 "limit": limit_num, #输入100,一次获取100个 } #UA伪装,headers是个通用的,不管是get还是post headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } response=requests.get(url=url,data=data,headers=headers) json_text=response.json() print(json_text)
3.爬取国家药品监管局(首页和详情页都是通过动态加载出来的)
爬取每家企业的详情数据.
如何验证数据是否是动态加载出来的数据?
访问上边这个url,在"检查"中,查看"Network"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号