小爬爬1:jupyter简单使用&&爬虫相关概念
1.jupyter的基本使用方式
两种模式:code和markdown
(1)code模式可以直接编写py代码
(2)markdown可以直接进行样式的指定
(3)双击可以重新进行编辑
(4)快捷键总结:
插入cell:a b 删除cell:x 切换cell的模式:m y 执行cell:shift+enter tab:自动补全 shift+tab:打开帮助文档
(5)ipynb文件相当于是放在缓存中,没有先后顺序.缓存机制
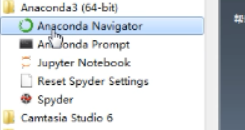
2.第二种打开anaconda的方式:
(1)图1
(2)图2
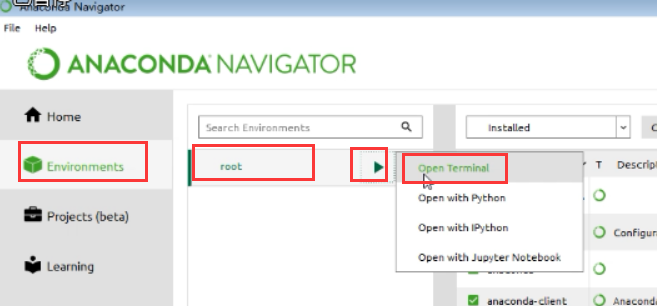
(3)图3,下图两个路径,也是也已打开浏览器的内容的

上边的方式打开,就不需要配置环境变量了.
2.基本概念:http回顾
1.什么是爬虫?
我们用过很多:就是浏览器本身就是
概念:通过编写程序,模拟浏览器上网,让其去互联网上获取数据的过程.
2.爬虫的分类
(1)通用爬虫:获取一整张页面数据, 比如百度,360,搜狗浏览器(背后有一套抓取系统)
(2)聚焦爬虫:根据指定的需求获取页面中指定的局部数据
(3)增量式爬虫:用来监测网站数据更新的情况,爬取网站最新更新出来的数据
(4)分布式爬虫:讲解完scrapy之后,再涉及到
3.反爬本质
反爬机制:网站可以采取相关的技术手段或者策略阻止爬虫程序进行网站数据的爬取
反反爬策略:让爬虫程序通过破解反爬机制获取数据
4.协议
(1)robots协议(可以不遵守):一种反爬协议,规定哪些数据可爬,哪些不可以爬,必须双方遵循才行.
防君子不防小人的协议
https://www.taobao.com/robots.txt
(2)http协议(超文本传输协议):client和server进行数据交互的形式(一定要善于总结)
https协议:安全的http
人与人之间其实就是在进行数据交互.
-使用到的头信息
请求头信息:
--User-Agent:请求载体的身份标识(浏览器或者爬虫程序都行,爬虫通过伪装的)
比如,我们安装的是谷歌浏览器,而我们访问的是百度,请求的载体是"谷歌浏览器"
--Connection:keep-alive或者close
close属性:当发送的请求成功之后,请求对应的链接会立马断开
keep-alive;当发送的请求成功之后,请求对应的链接会断开,但是不会马上断开
响应头信息:
--content-type:可以是json或者text或者js,作用:说明服务端响应回客户端的数据格式或者数据类型.
5.
https:安全的http协议
证书秘钥加密?
在理解上边的加密方式之前,我们先了解"对称秘钥加密","非对称秘钥加密"
初步了解即可
三种加密方式:证书秘钥加密,对称秘钥加密,非对称密钥加密
(1)SSL加密技术:
SSL采用的加密技术叫做"共享密钥加密",也叫作"对称秘钥加密".
缺点:一旦被三方拦截,就会被破解秘钥和公钥,密文就可能被破解

(2)非对称加密
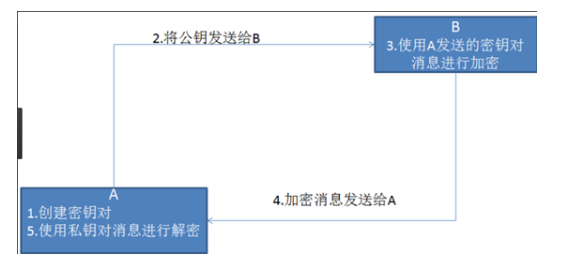
缺点:(1)效率比较低,(2)客户端不知道是不是服务端发送的公钥.
(3)证书秘钥加密:攻克了非对称秘钥加密的问题
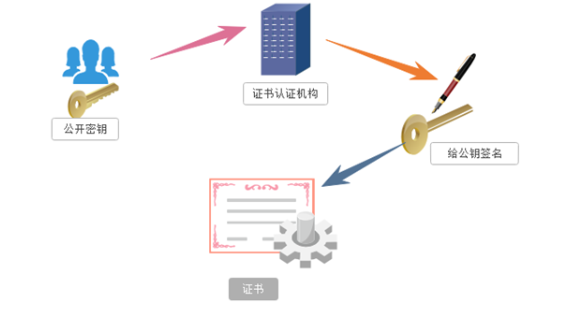
三方机构:证书认证机构
参考博客:https://www.cnblogs.com/bobo-zhang/p/9645715.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号