巨蟒python全栈开发django9:一些知识点的汇总
回顾上周内容:
题目:
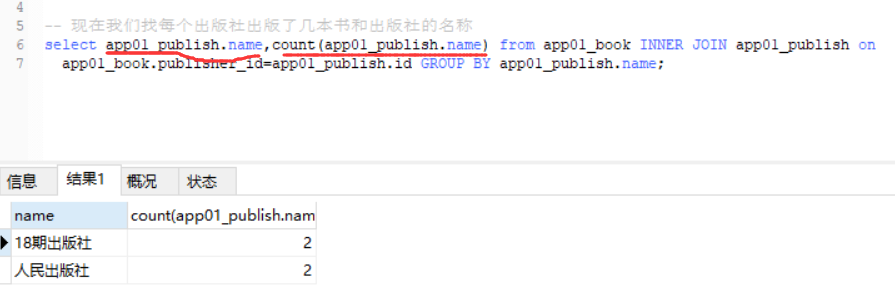
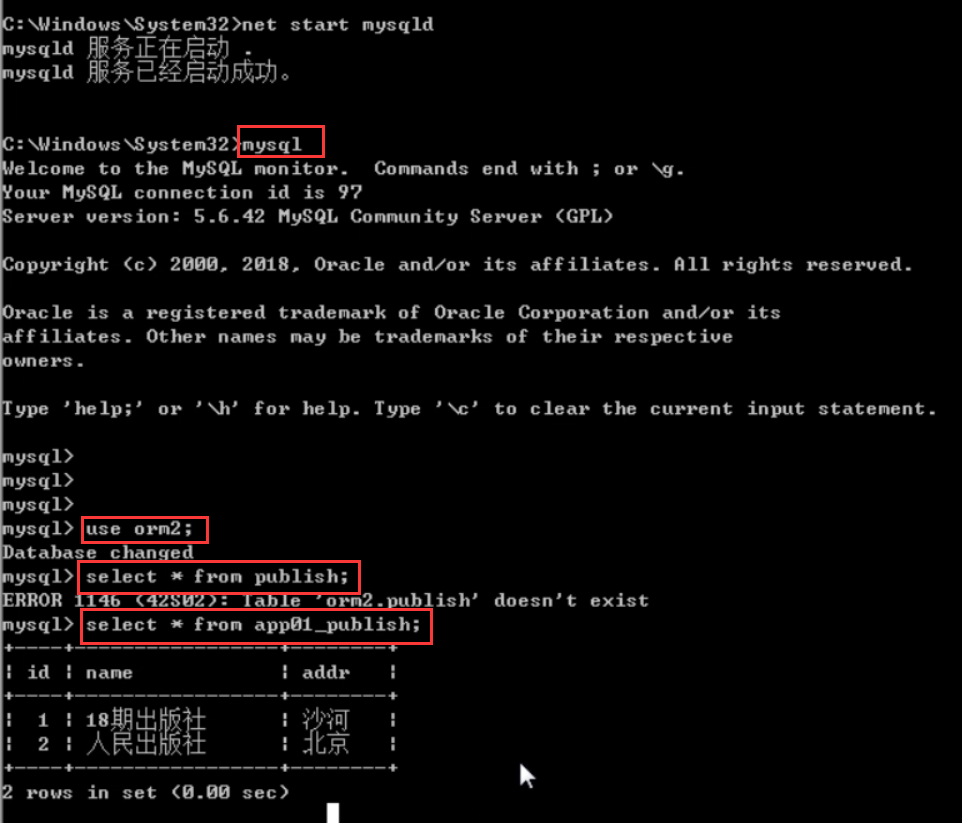
1.人民出版社出版过的所有书籍的名字以及作者的姓名(三种写法,笔记中有两种写法)
2.手机以2开头的作者出版过的所有书籍名称以及出版社名称(三种写法,笔记中有1种写法)
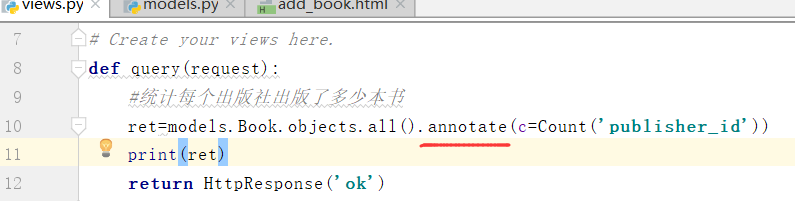
1.聚合查询(aggregate)
需求:查找所有书里边的最大价格的那本书
因为,书这张表中没有价格字段.我们需要添加一个这样的字段
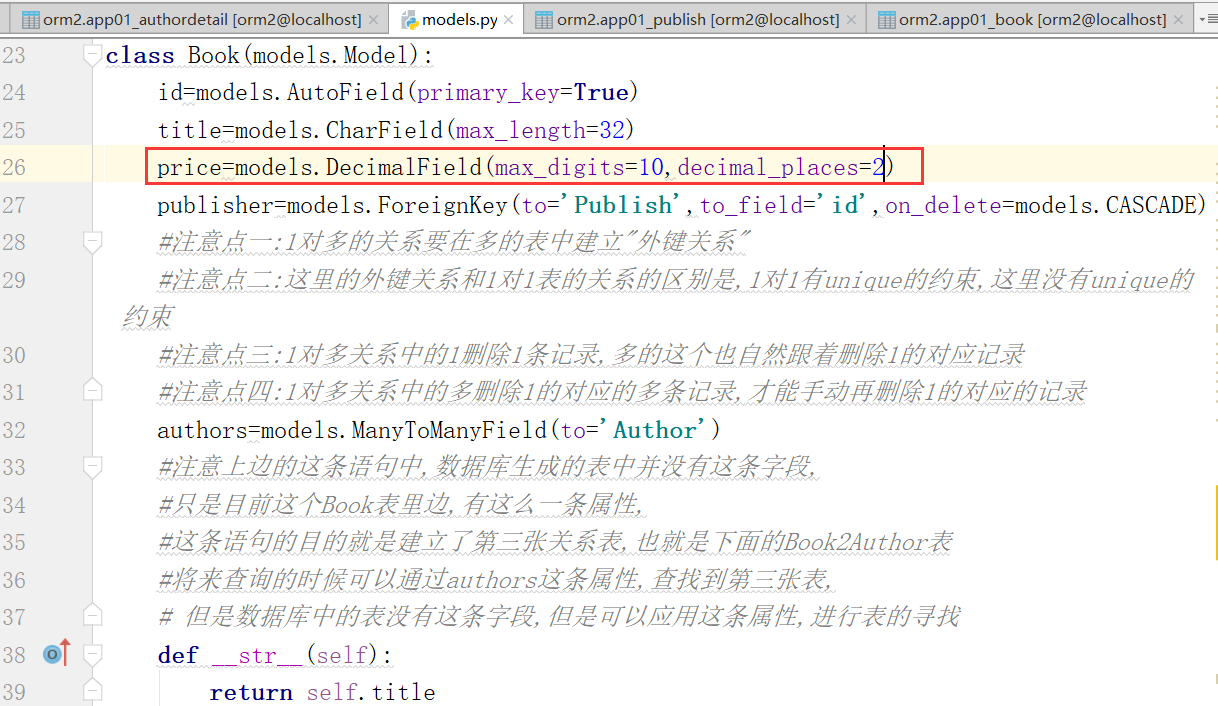
同步数据库需要的指令,首先,找到,简化的指令
运行指令:
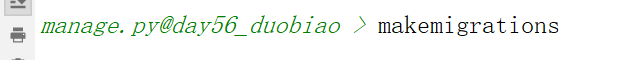

上边说明,需要设置一个默认值,所以,我们选择2,退出,在models.py里边添加默认值
这样就回到了,相关的界面

设置默认值为10
执行指令:
这时候,表里边就有一个,默认值为10的价格属性字段了
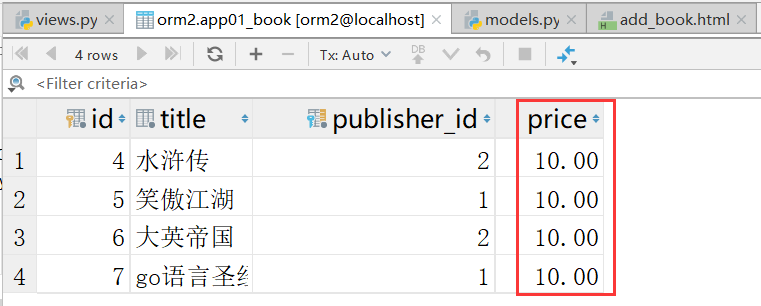
修改价格
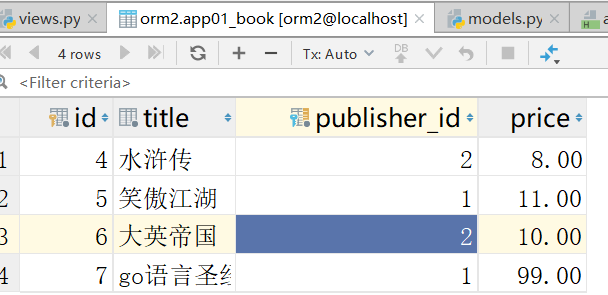
查询价格最高的那本书
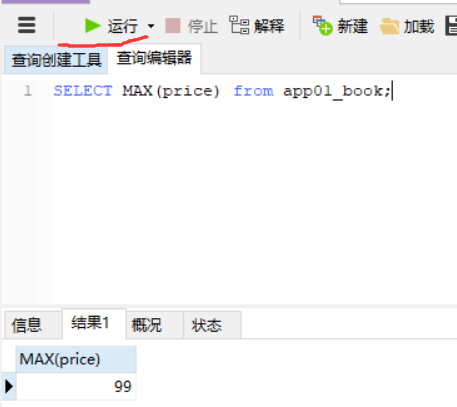
写完命令,点击查询
聚合就是上边最后得到的结果
首先,引入聚合函数
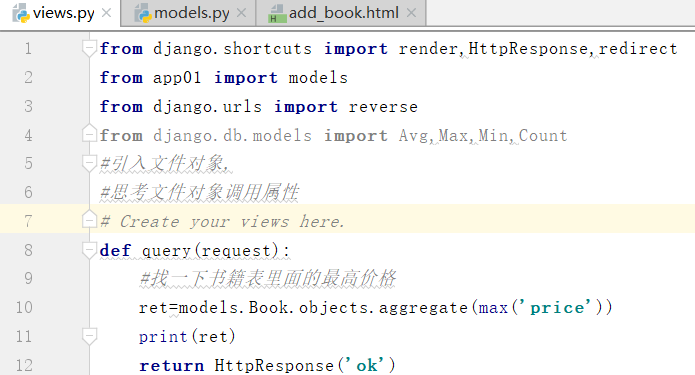
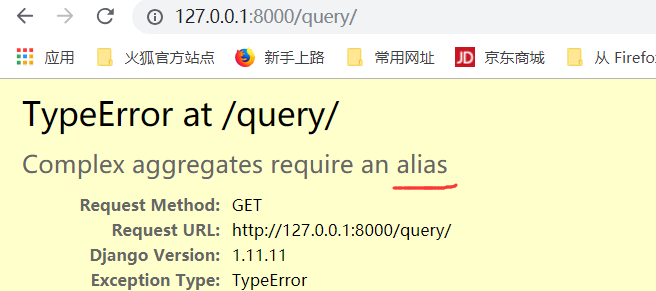
注意:这里报错的原因是max需要大写Max
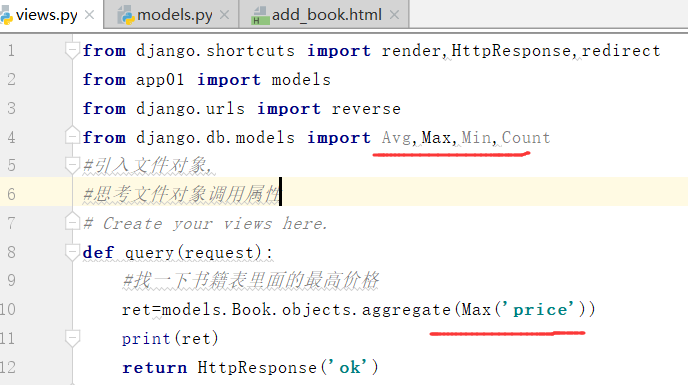
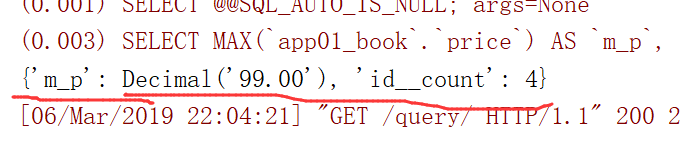
运行,得到如下结果:

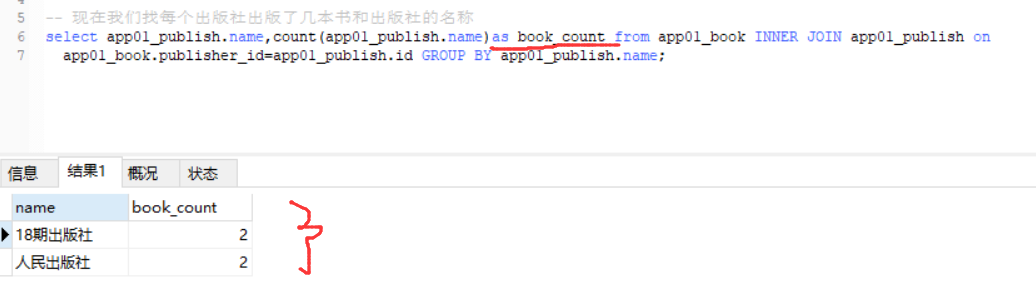
现在我们再起别名
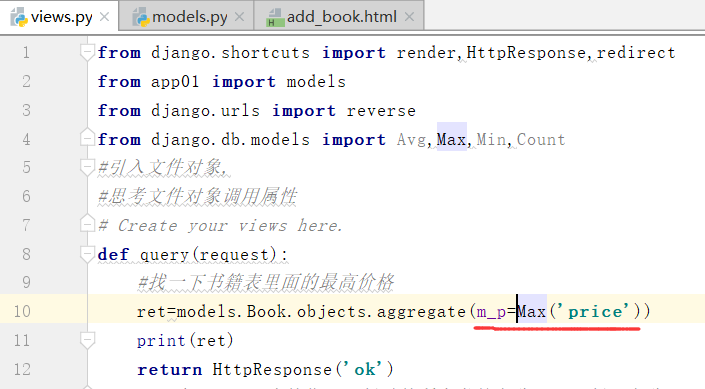
,将别名进行了修改为,m_p
得到如下结果:

查一下书籍的总数
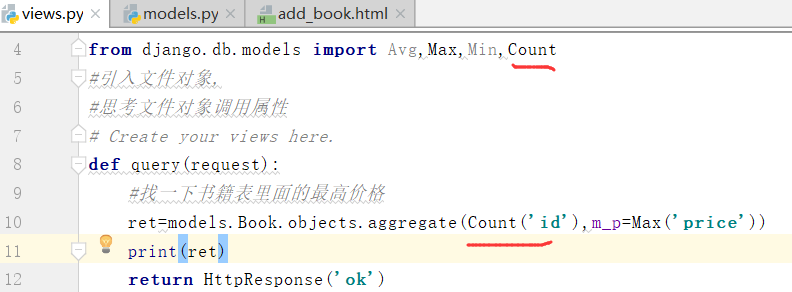
得到的是4条数据
利用filter和all进行筛选

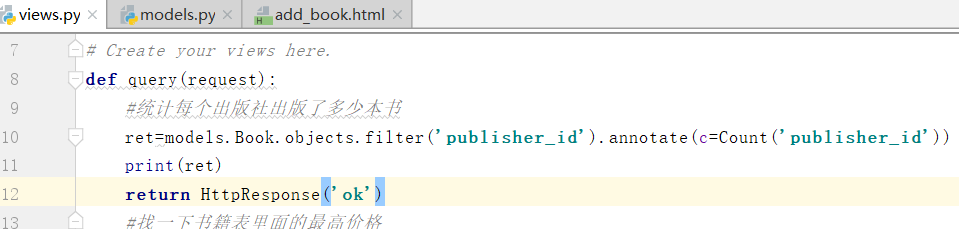
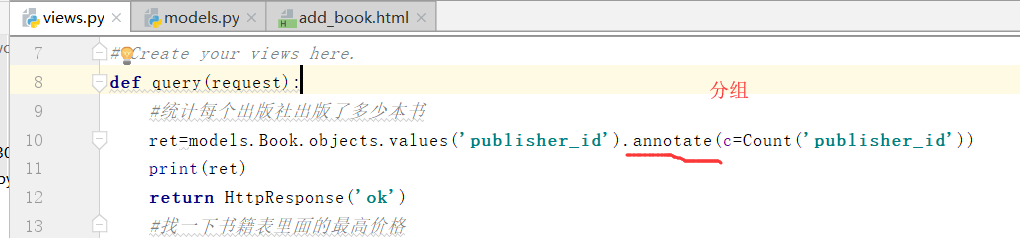
如上图,以publish_id分组即可
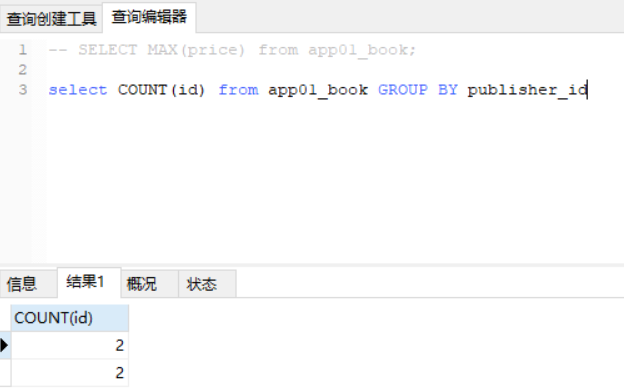
得到如上结果:
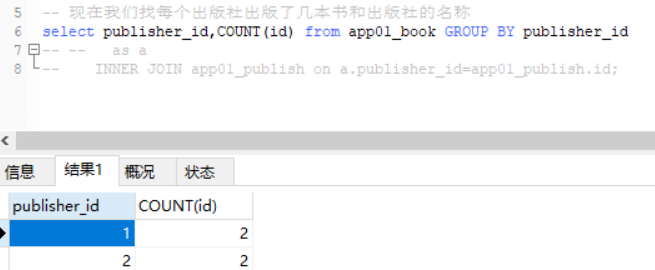
出版社的名字是可以拿到的
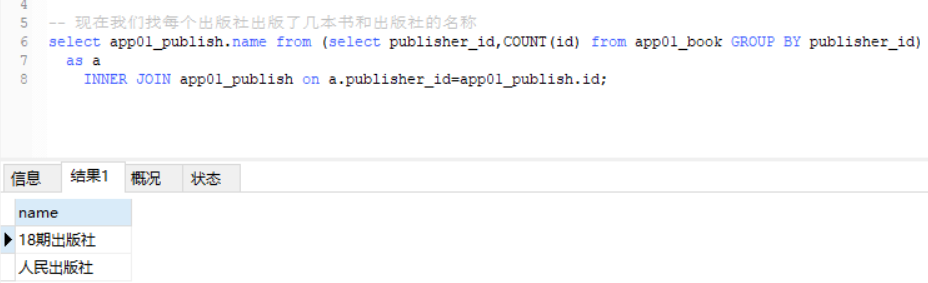
连接字段
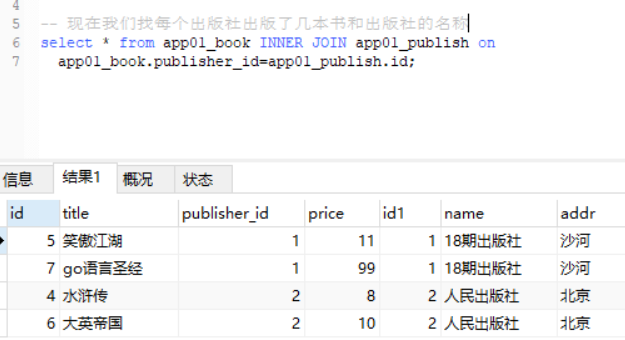
分组通过publish的名字
起别名:
2.分组查询
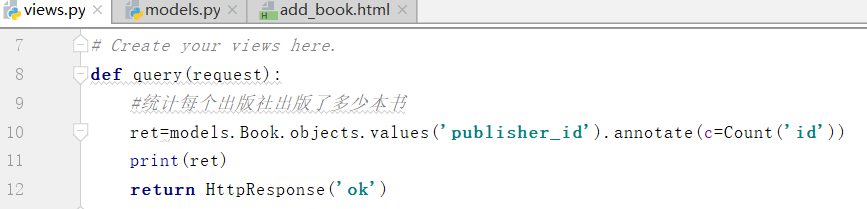
得到结果:

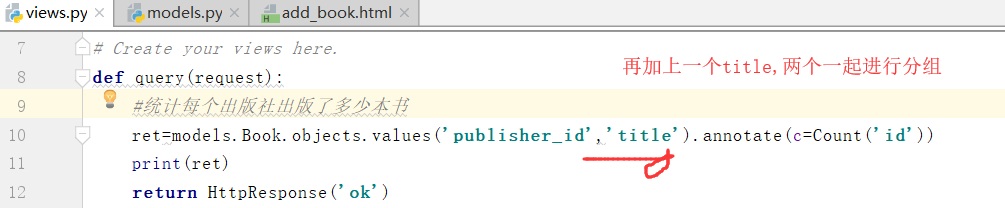
得到结果:

以and关系进行分组
结果:

分组之后,再统计结果
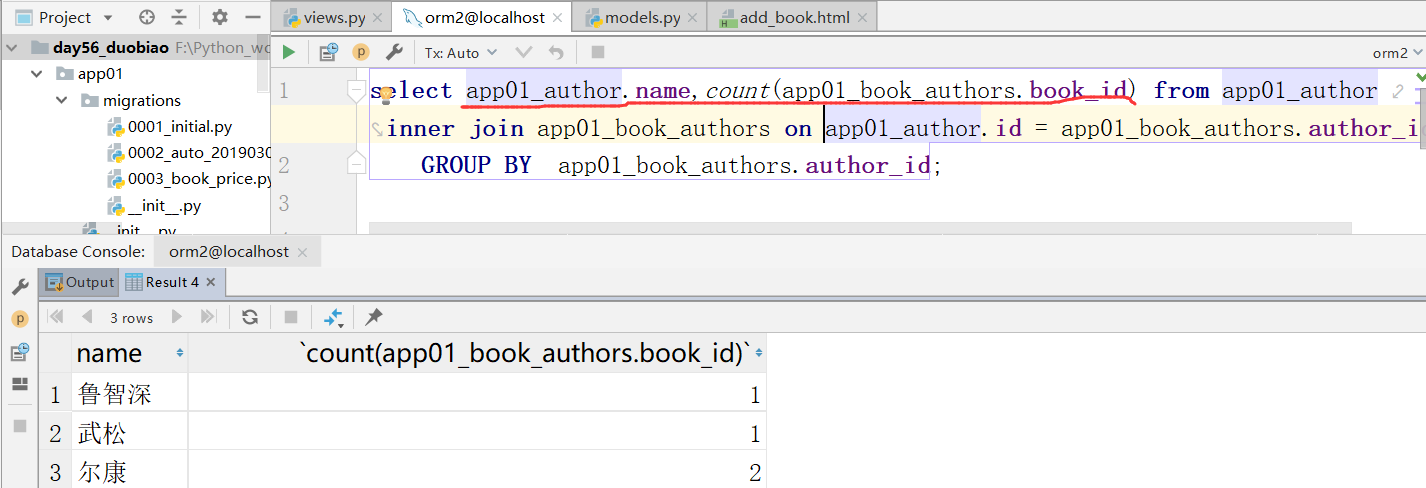
注意下面的book__id,指的是两个横杠
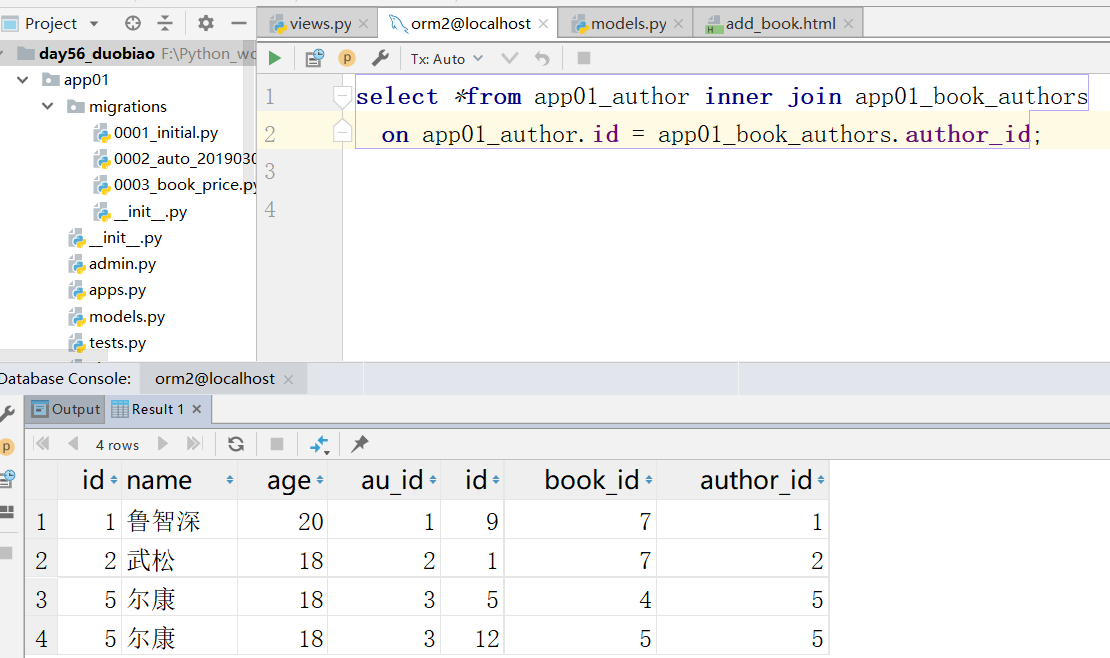
通过下面,我们知道尔康出了两本书

执行,得到结果:
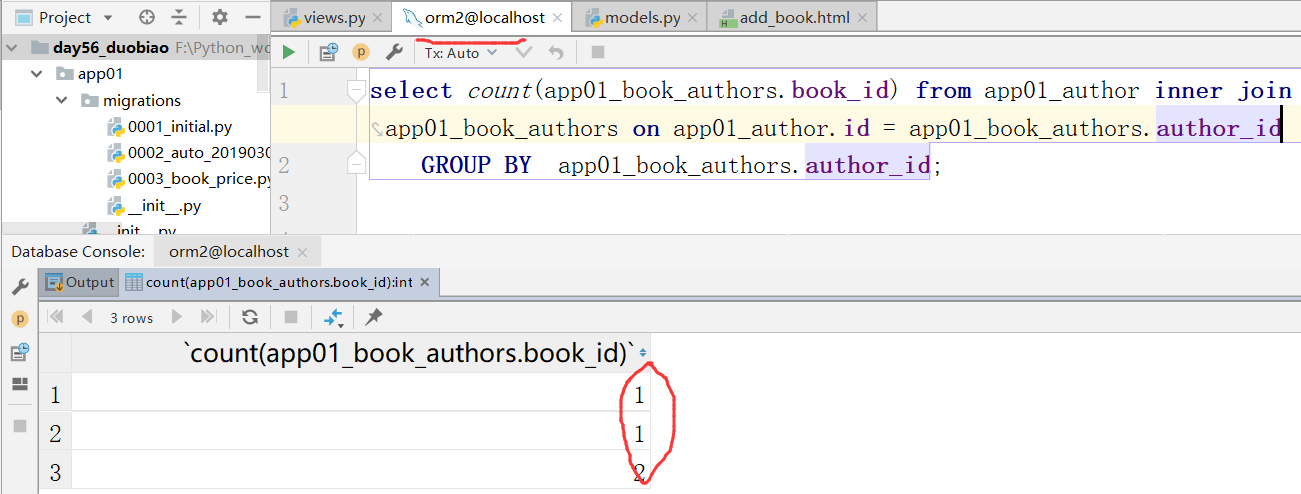
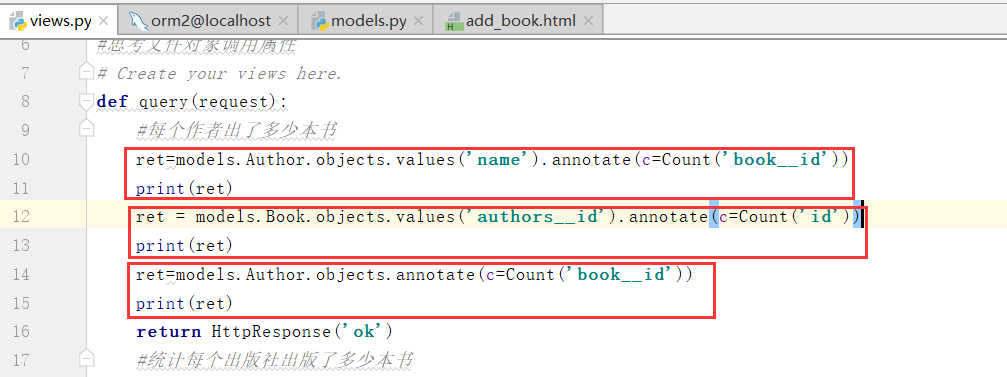

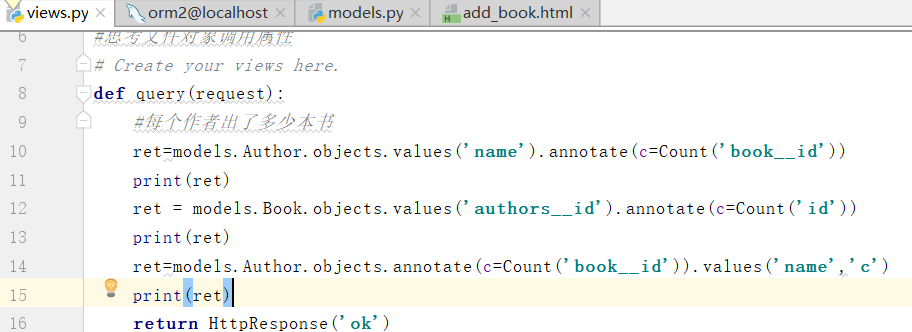

先联表再进行分组
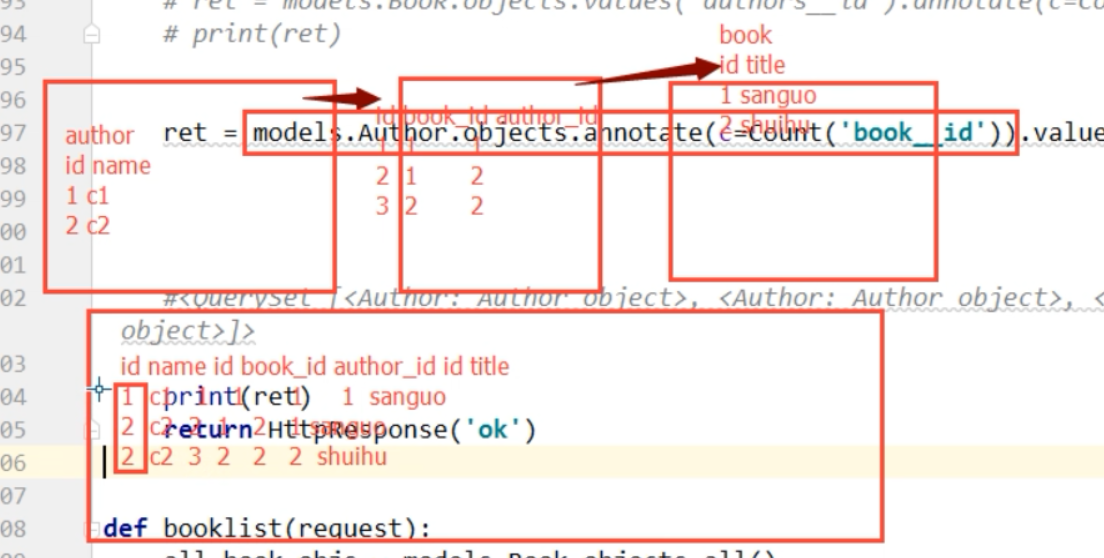
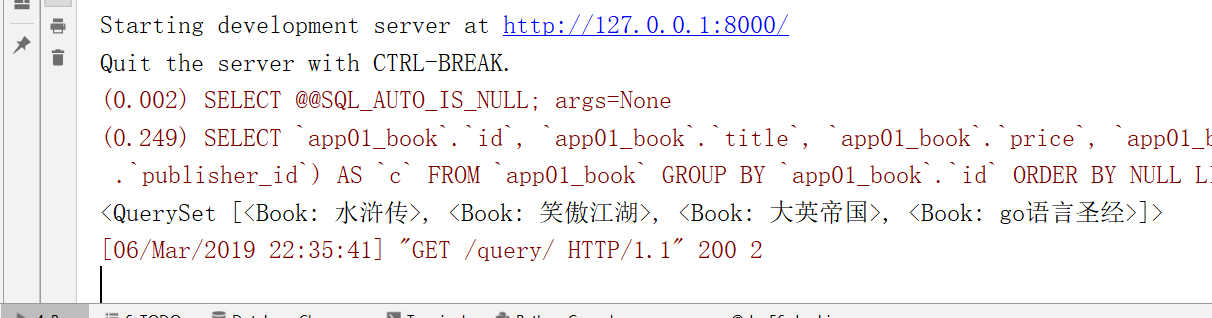
ORM执行原生sql语句
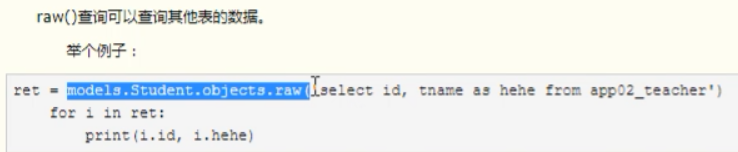

直接拿取数据
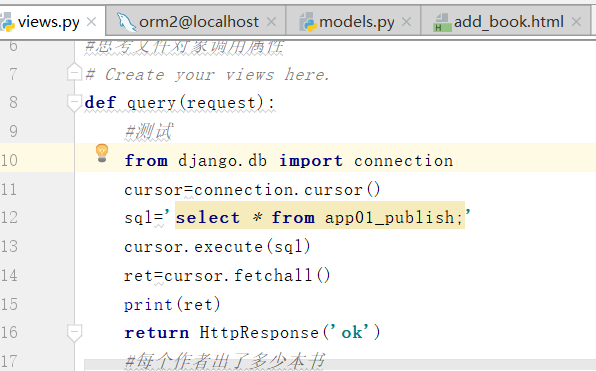
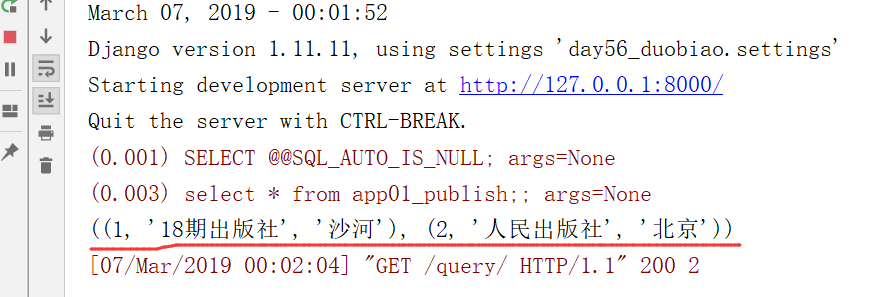
通过原生 的SQL,我们就得到了这样的结果
3.F&&Q查询
添加两个属性,点赞数和评论数
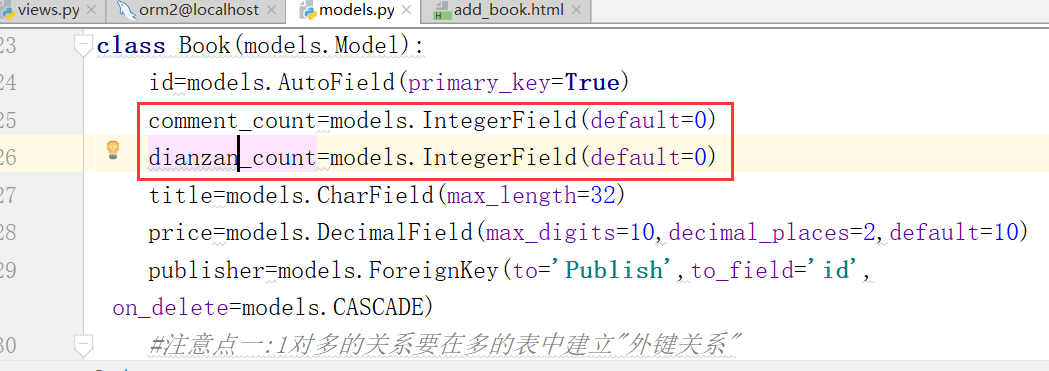
执行,两条命令:
makemigrations
migrate

得到如下表
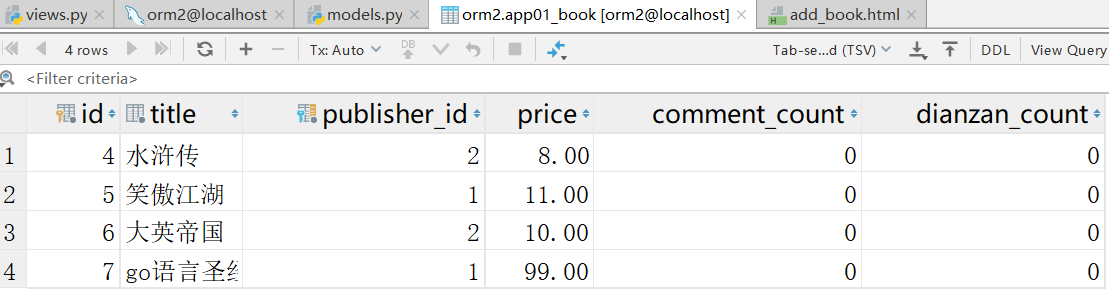
添加数据得到如下所示:
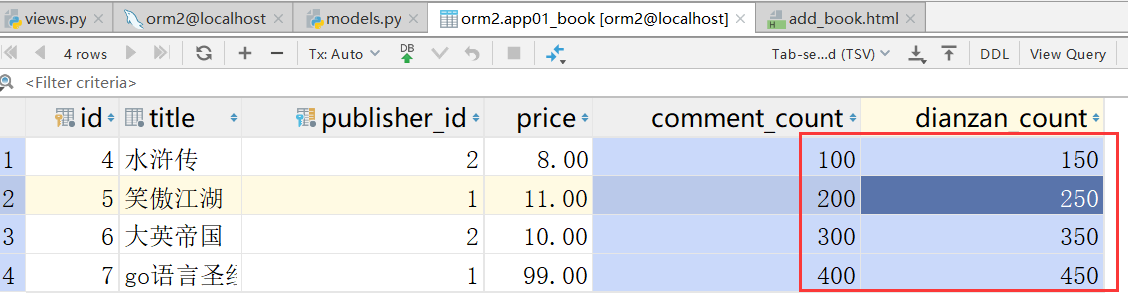
F&&Q
注意,两个字段之间不能直接比较
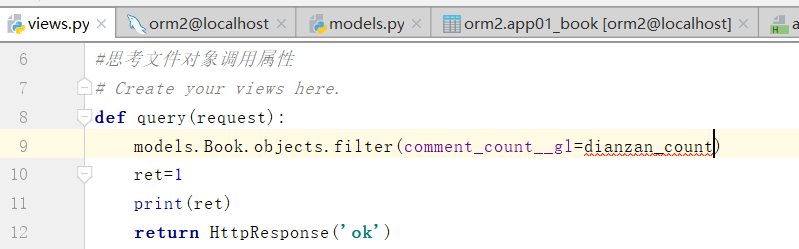
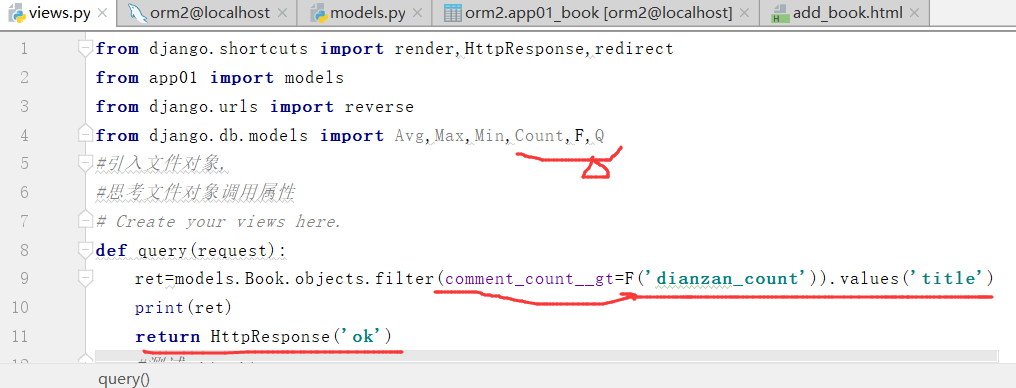

集合为空,说明没有大于的
可以对F进行处理
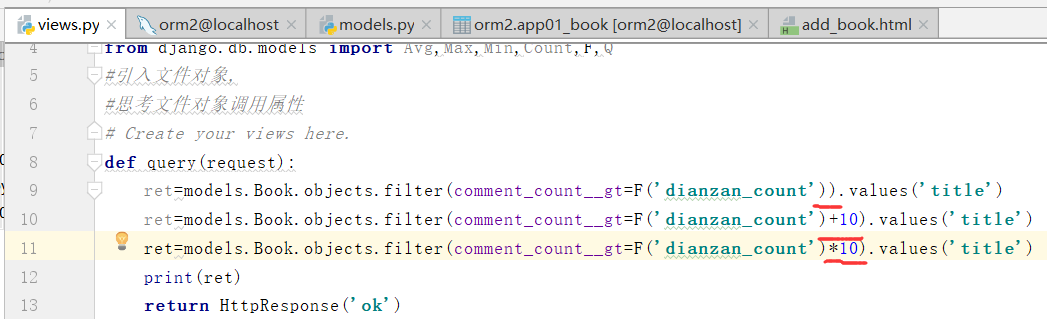
更新,自增12
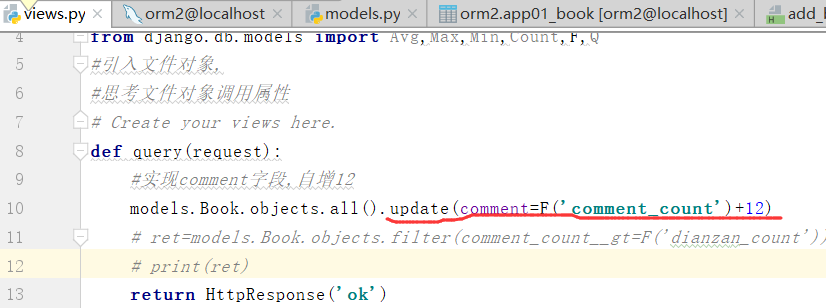
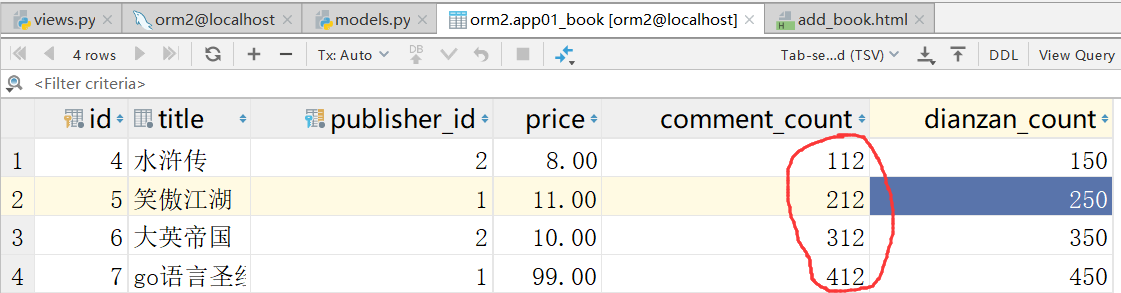
更新之后,

刷新之后,评论结果加上12
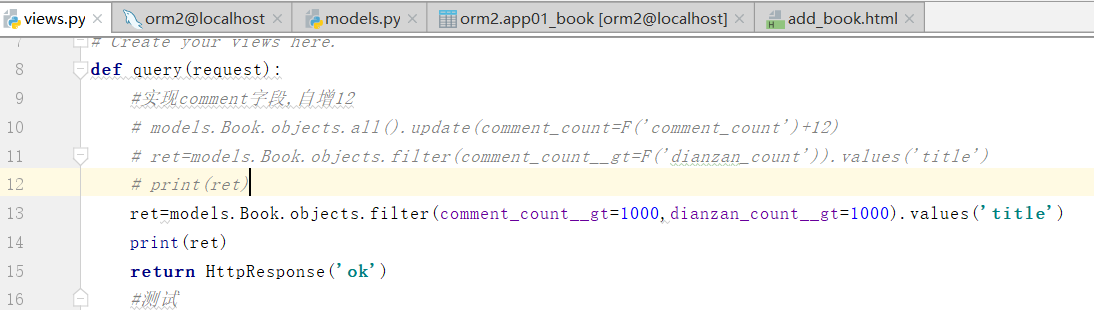

结果里边没有两个都大于1000的数据
Q通过管道符|实现"或者"的意思

且的话,我们再写在后边


注意一点:Q包裹的放在没有Q包裹的前面
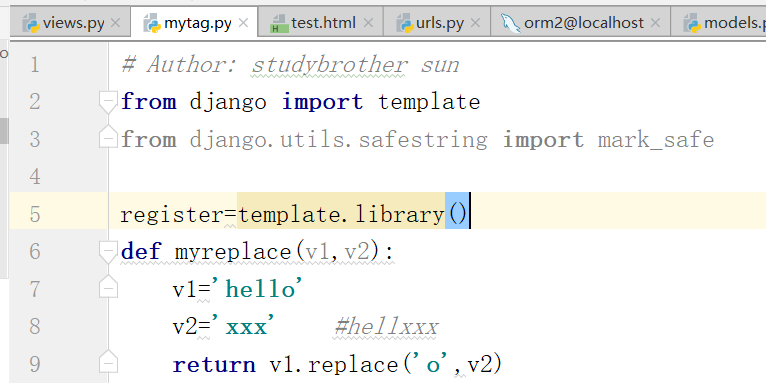
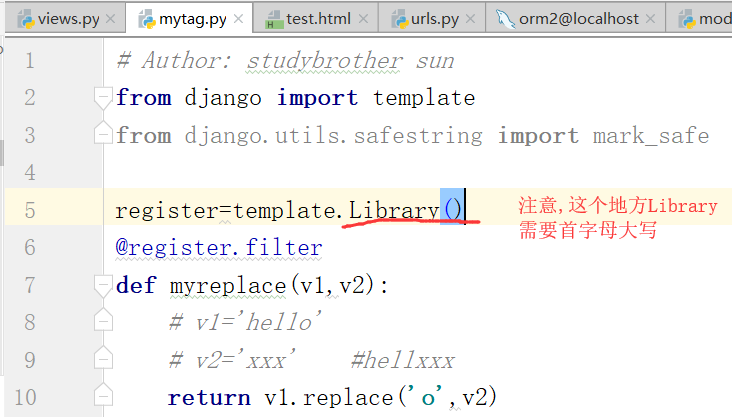
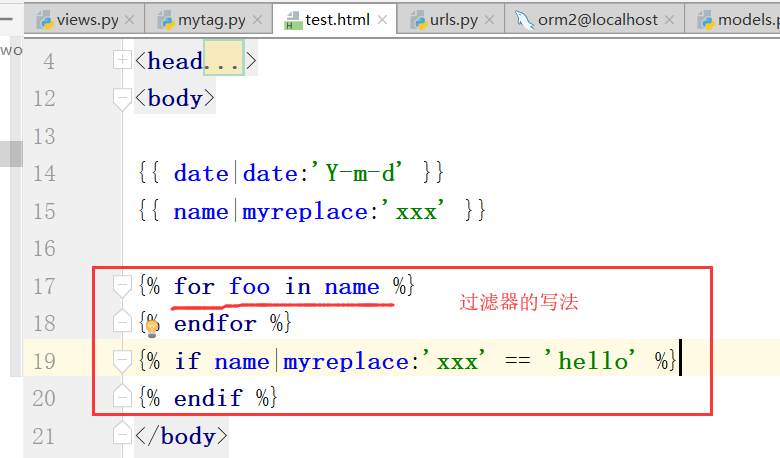
4.自定义标签过滤器
自定义过滤器
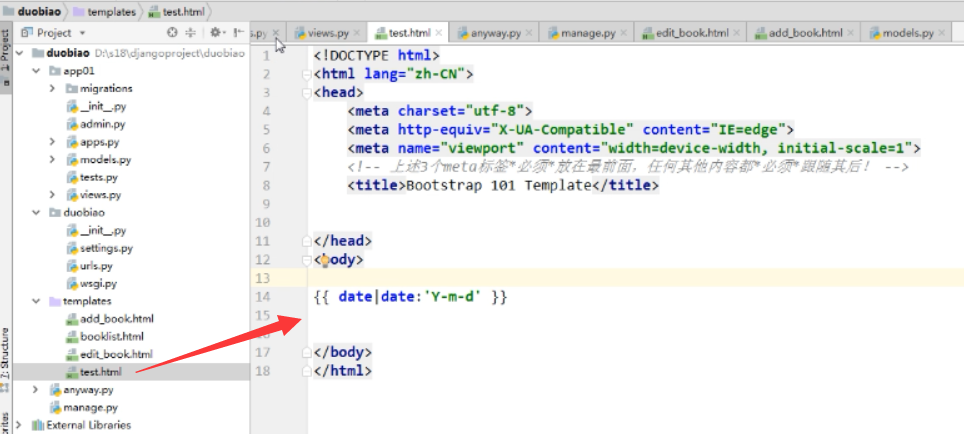

运行:
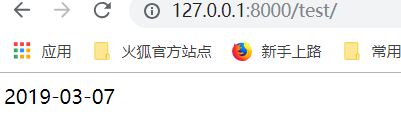
下面是自定义标签:
如何运用到模板语言之中呢?(自定义过滤器)
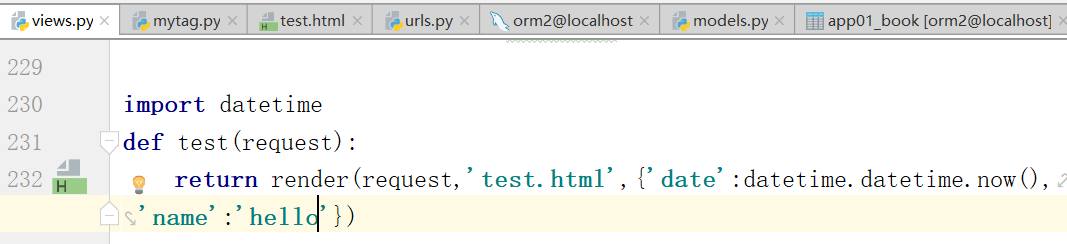
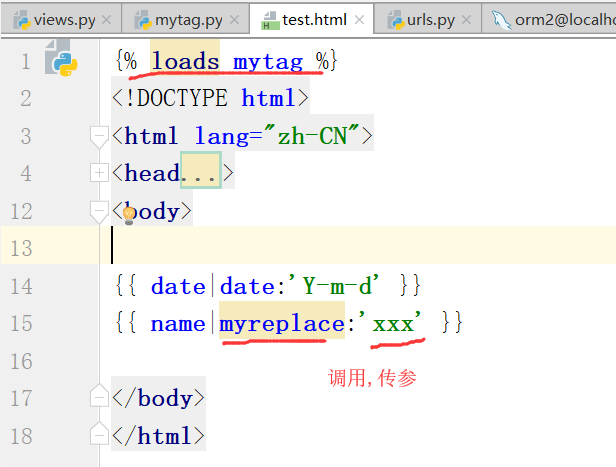
需要处理的数据,函数,需要替换的参数,在下面的过滤函数中最多接收2个参数,而且这个过滤器和其他过滤器一样,
可以放到if判断,for循环等语句里面来使用
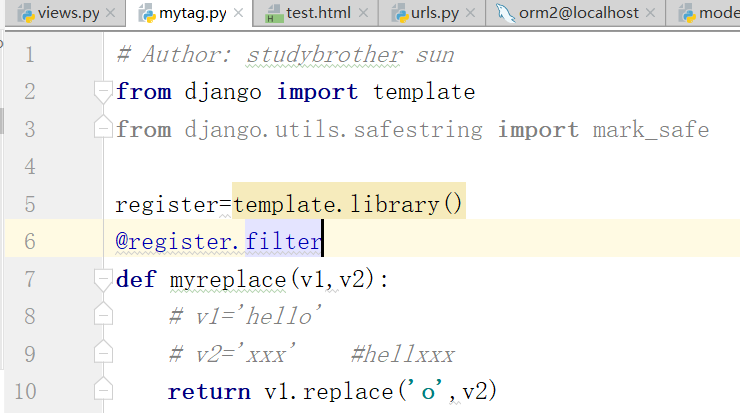
运行报错,之后的修改:
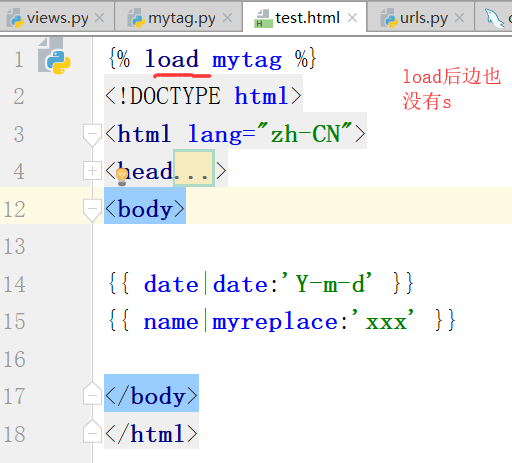
再次,运行,得到结果
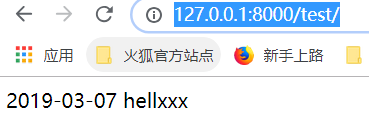
得到的结果如上图
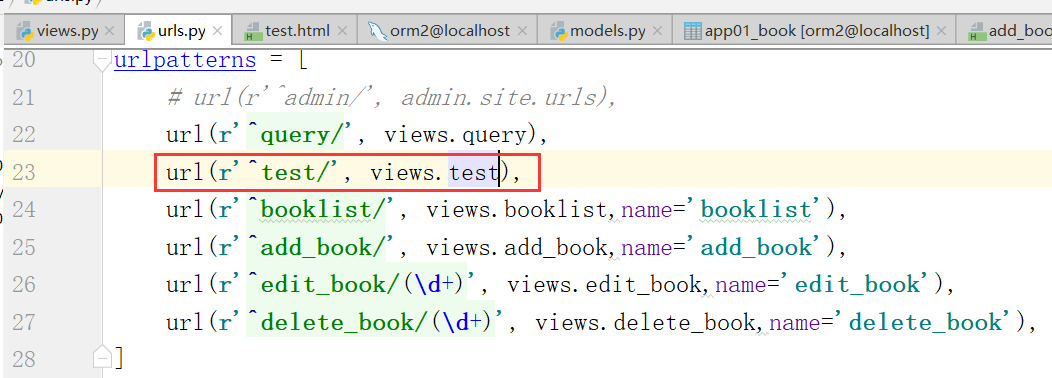
涉及到的文件夹(urls.py test.html views.py templatetags/mytag.py)
过滤器也可以如下图,这样使用
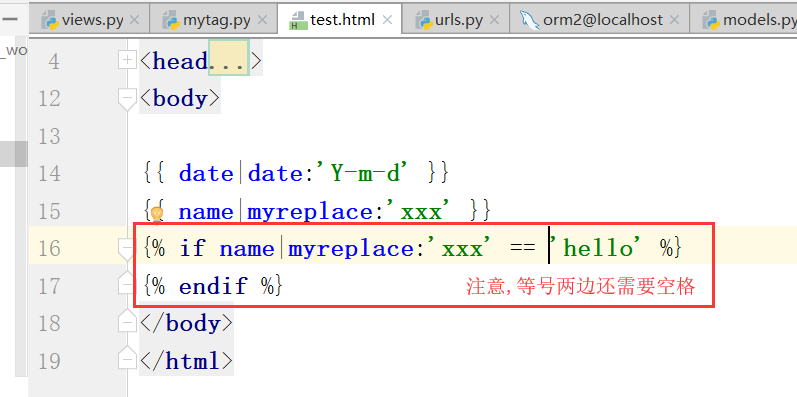
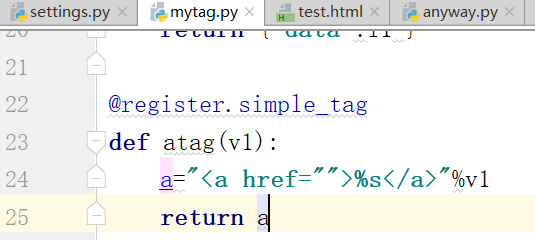
下面是自定义标签:(下面的函数,可以传递任意个参数)
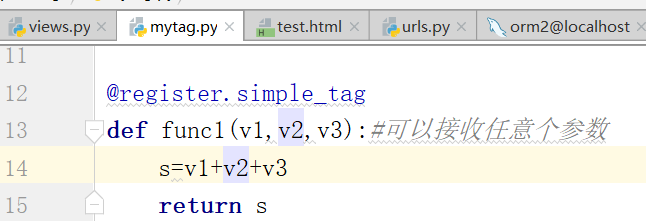
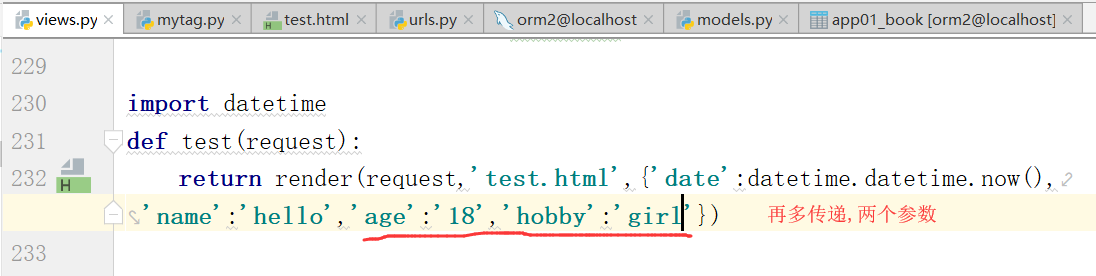
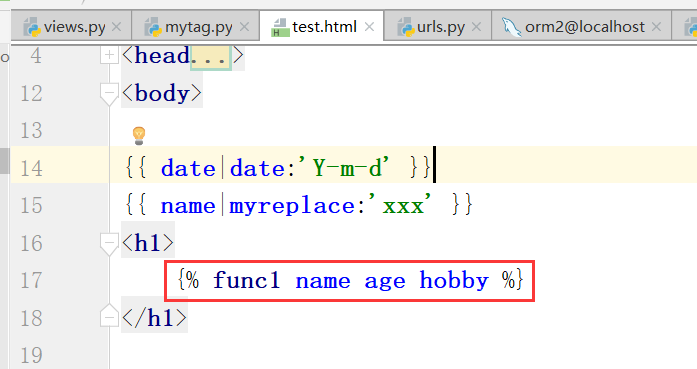
运行,测试,得到结果:
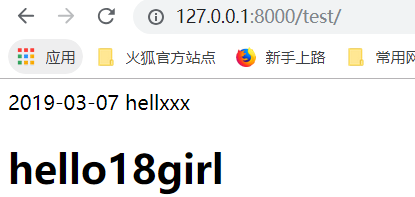
注意,这个函数,不可以写在渲染语句里边

inclusion_tag标签
文件:(result.html mytag.py views.py test.html result.html urls.py )
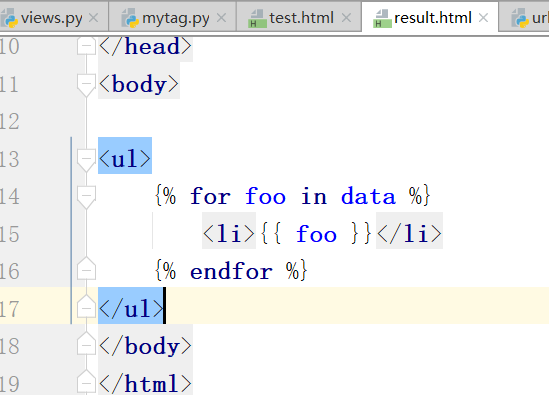
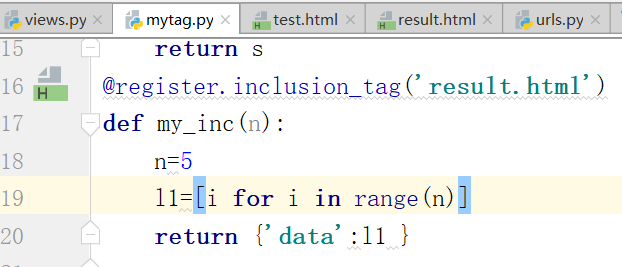
return里边的data就是上边的html里边的data,前端接收后端的
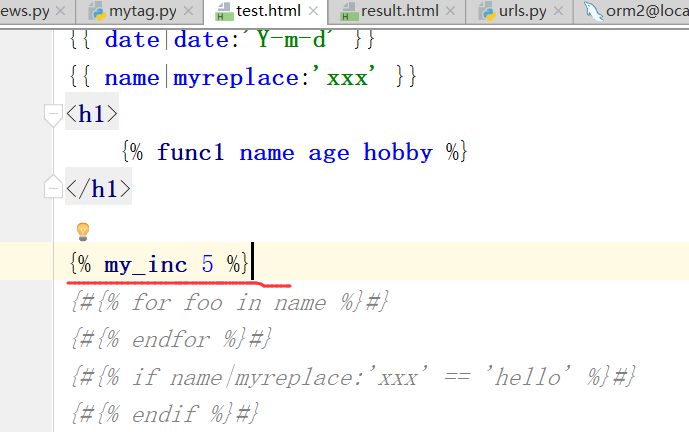
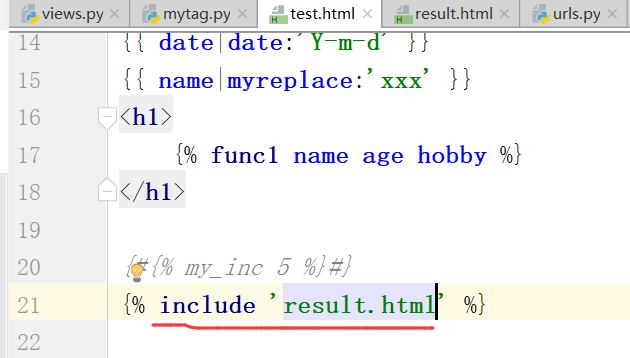
以组件形式引入上边的标签的方式
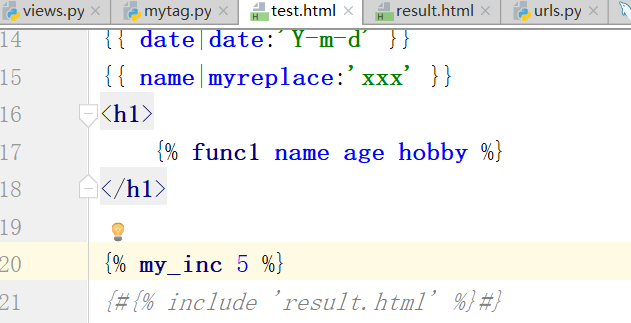
在mytag.py里边的return里边的data通过以字典的形式,传递给result.html,进行渲染
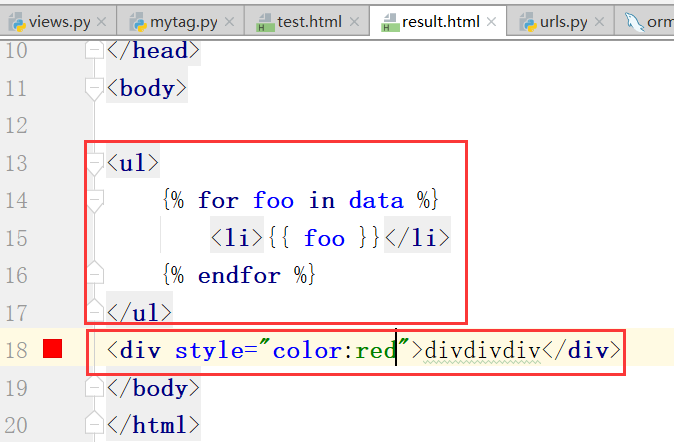
运行:得到的结果

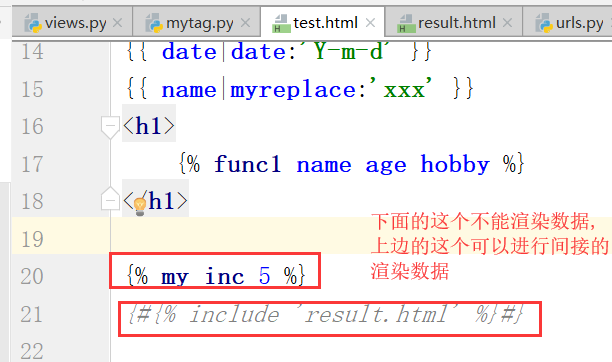
5.静态文件配置
一开始引入的是网络地址,bootstrap,如何添加到本地???
需要手动处理,为了防止bootstrap网上的崩溃了,需要写在本地
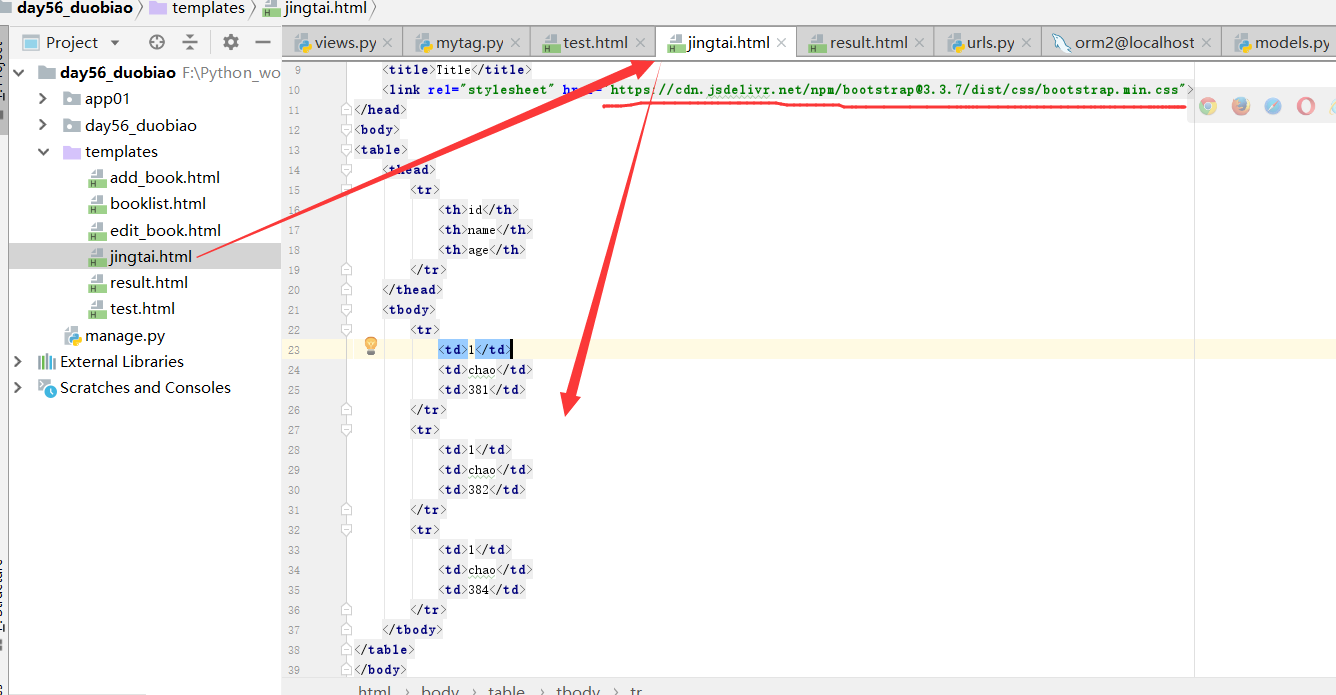

运行,得到结果:
现在,我们应用bootstrap样式,在jingtai.html文件里边
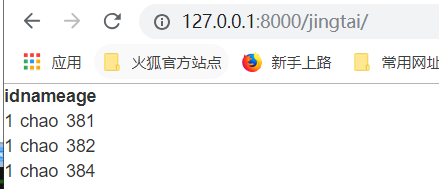
运行,得到结果:

万一哪一天,网上的bootstrap崩了,就需要有事情了,我们需要在本地处理
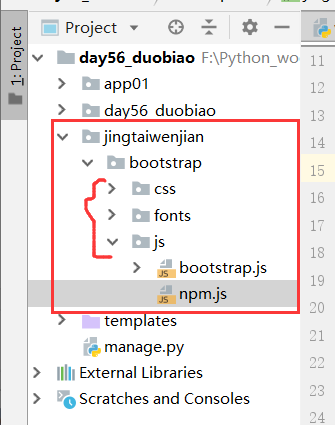
首先,在整个项目上创建jingtaiwenjian文件
将下载到本地的bootstrap,解压之后放到jingtaiwenjian里边
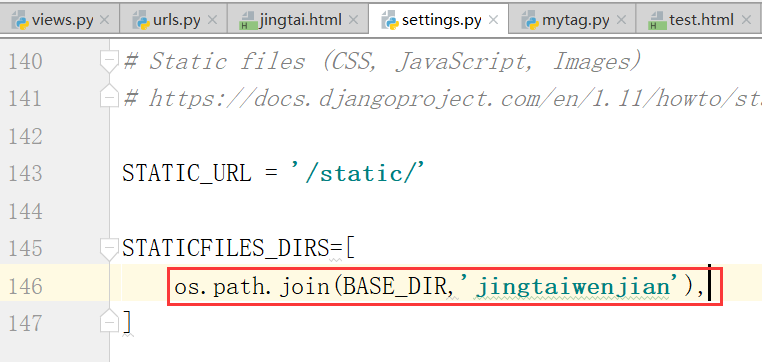
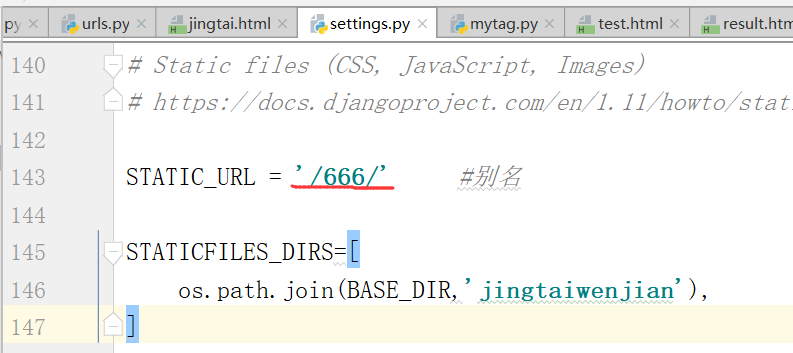
配置settings.py文件
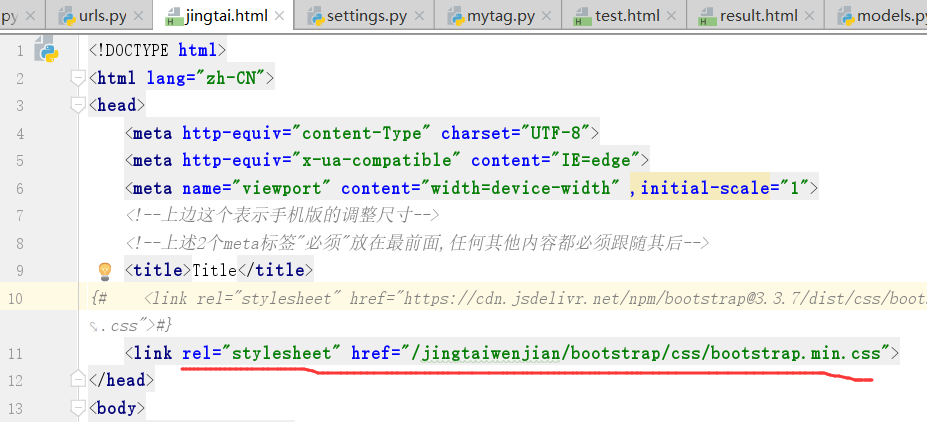
运行:bootstrap并不起作用,这个和刚才的配置文件有关系
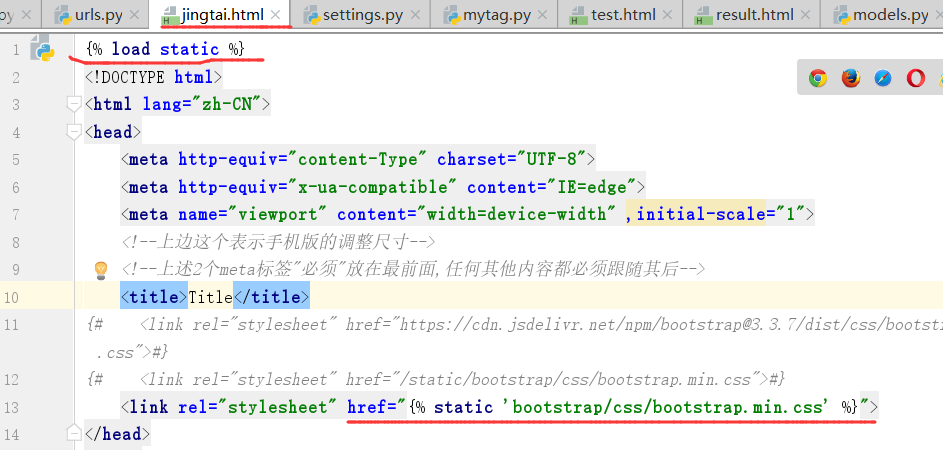
正确的写法
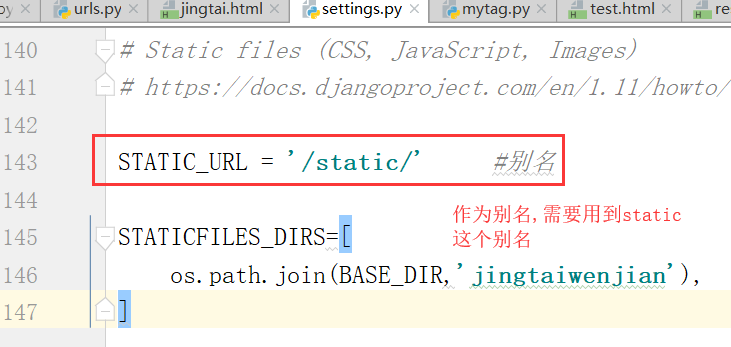
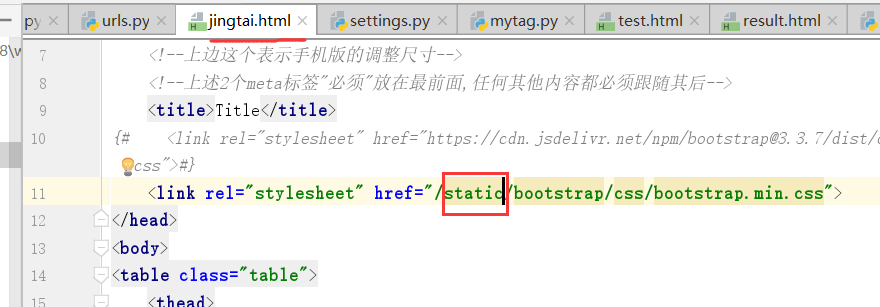
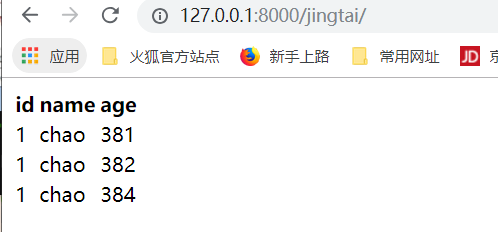
修改成的static,再次运行,就可以成功修改了.以别名的方式引入
如果别名修改成xxx,
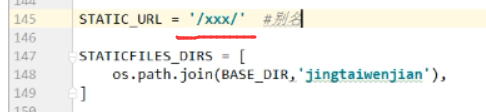
引入的路径,也需要改成xxx

下面介绍一种,不需要改的,自动加载的方式:
将别名改成"666"试一下
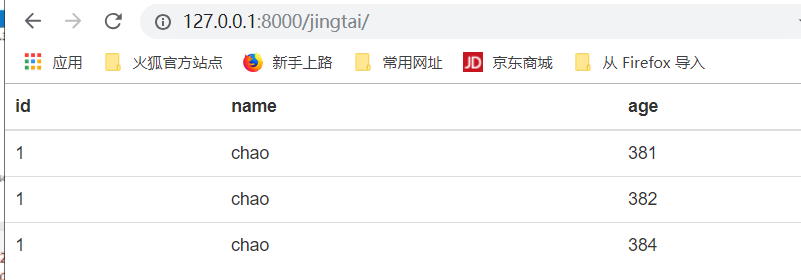
如上图,依然可以得到上边的结果
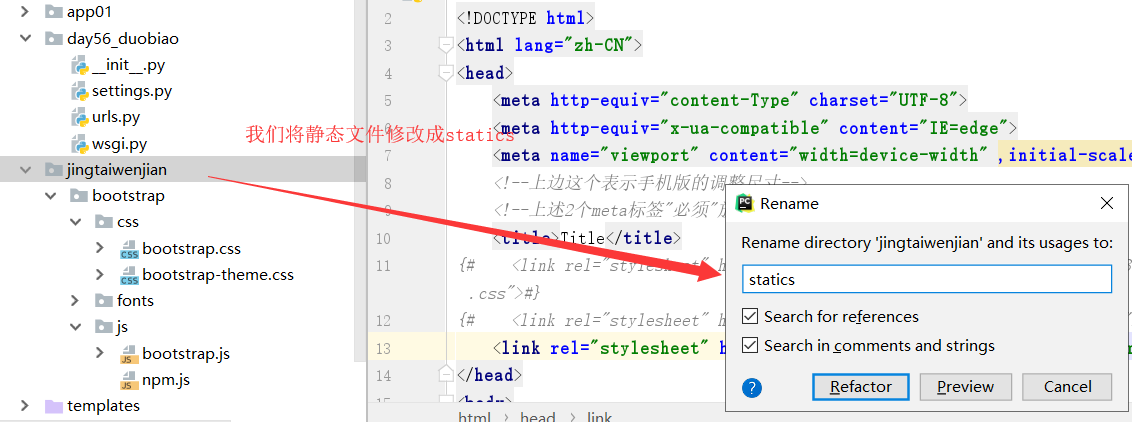
我们将上边的结果,修改成statics,这是习惯性问题.
下面的settings.py也需要进行修改
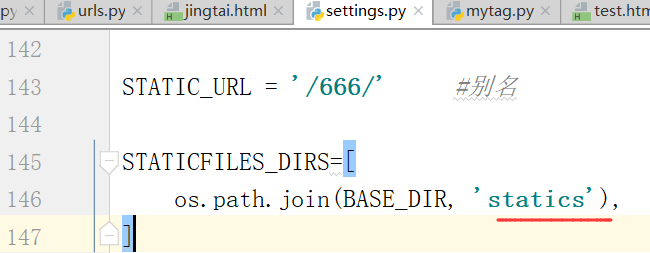
在我们上边修改文件夹名字的时候,已经进行自动把这里的jingtaiwenjian修改成了statics
但是这里,羞不修改貌似,没有太大影响,已经测试过了.
6.事务和锁
锁:(遇到之后可以再读一下超哥的笔记)
锁,指的是,某些数据,在同一时间只能一个人用,尤其指的是数据库中的相关操作,
防止多人同时操作一条数据.
MYISAM支持的表级锁(锁住整个表),MYISAM又分为读锁和写锁是隔离的
INNODB支持的是行级锁(锁住一行)和表级锁
INNODB在更新和删除某条记录的时候是锁住的,其他人是不能查看的和写入
有很多概念.
更新和删除的时候,用的是表级锁
查询的时候是共享锁

事务的四大特性:原子性,持久性,唯一性,隔离性
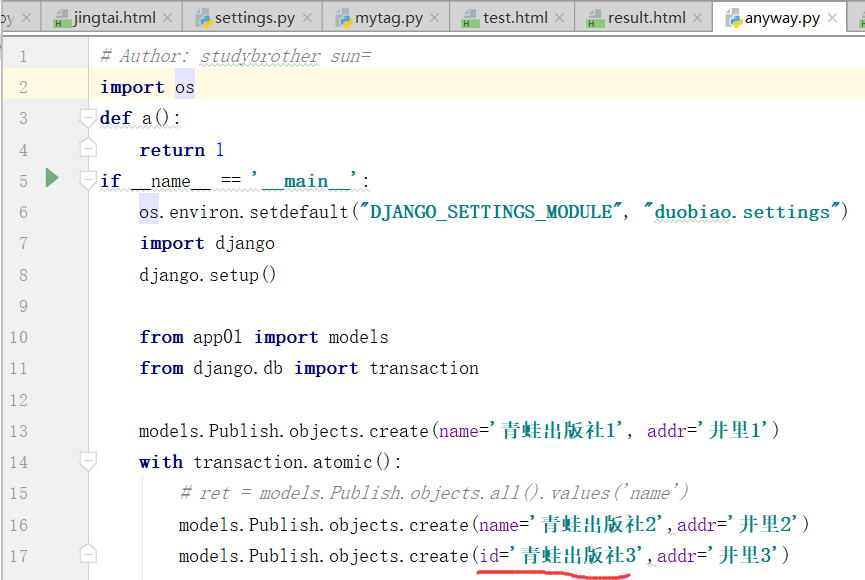
上边的代码一直报错:
原因如下图:
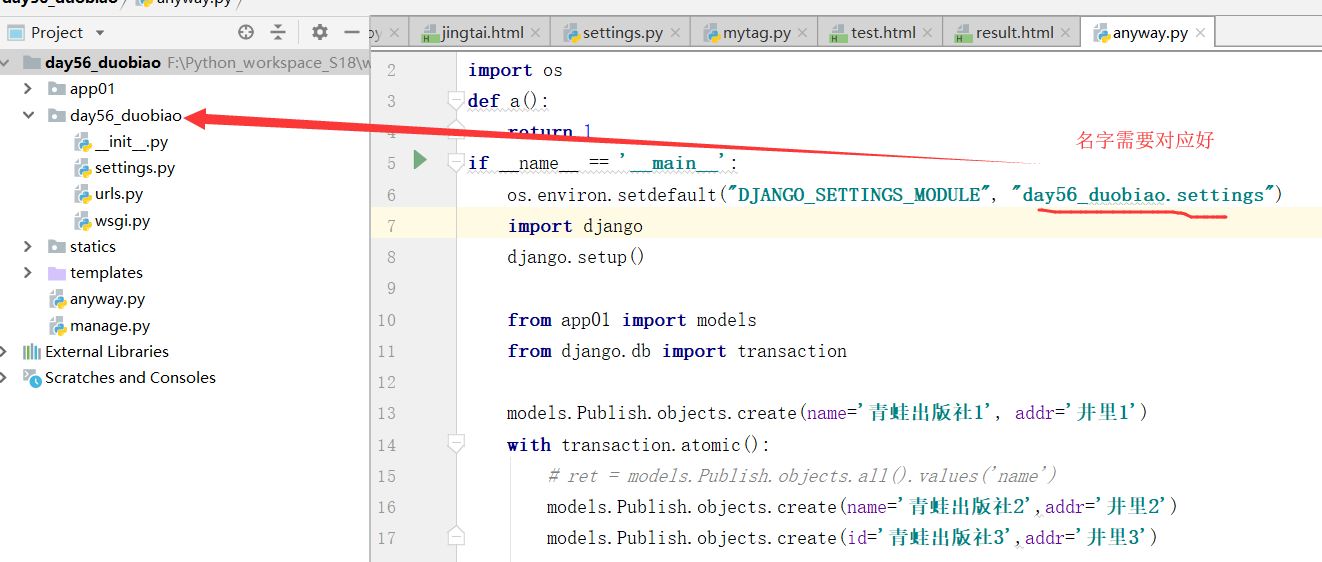
运行:anyway.py,得到结果(报错)

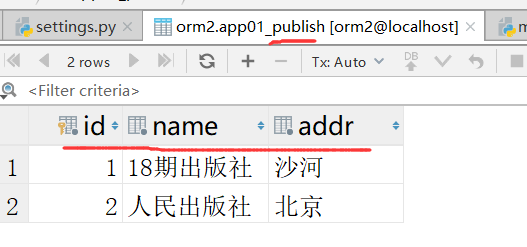
我们再看一下,多了一条数据
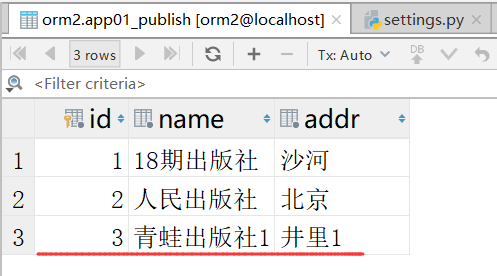
运行成功,运行anyway.py出错的原因是因为属性不对应和publish表.
复习:
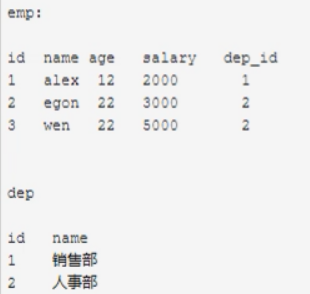
连表,分组,找数据(三步走)
#按照部门分组查询名字和id的数量 # select name,count(id) from emp group by dep; # ret = models.Emp.objects.value('dep').annotate(c=Count('id')) # print(ret) #查询每一个部门以及对应的员工数 # select dep.name,count(emp.id) from dep inner join emp on dep.id=emp.dep_id # group by dep.name,dep.id; # models.Dep.objects.values('id','name').annotate(c=Count('emp__id')) #查询每一个部门以及对应的员工数以及ID # select dep.id,dep.name,count(emp.id) as c from dep inner join emp on dep.id=emp.dep_id # group by dep.id,dep.name; # # models.Dep.objects.annotate(c=Count('emp__id')).values('name','c') # # select dep.name,count(emp.id) as c from dep inner join emp on dep.id=emp.dep_id group by dep.id;
mark_safe补充
在test.html里边调用
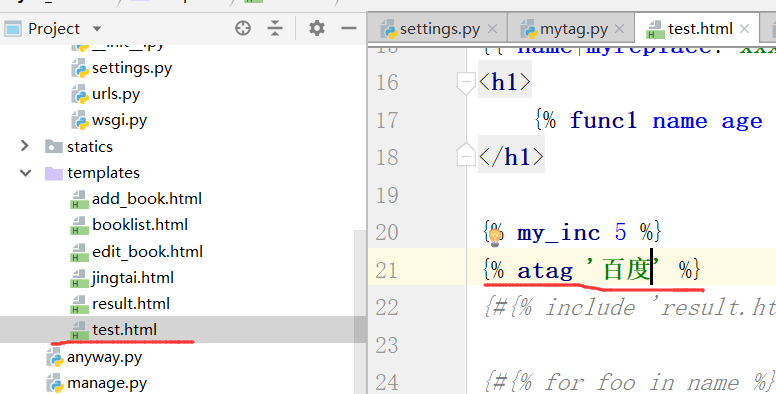
运行结果:
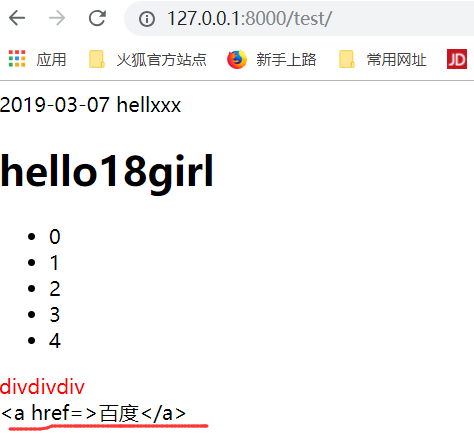
没有变成,修改如下标签
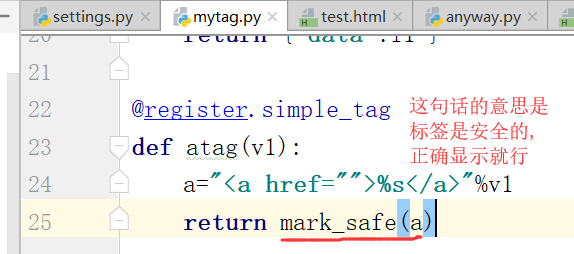
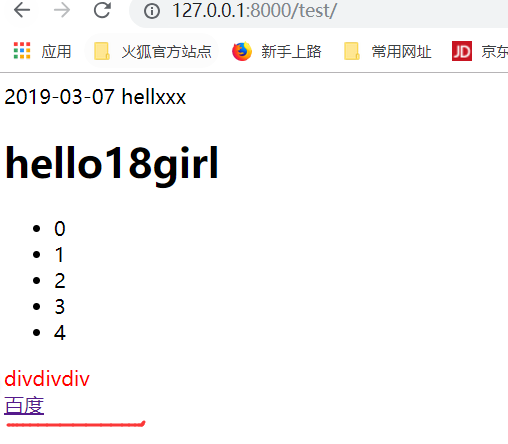
这样就修改成功了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号