巨蟒python全栈开发django6: FBV&CBV&&单表查询的其他方法
练习CBV用法

截图中的action="/cbv/",应该是这样


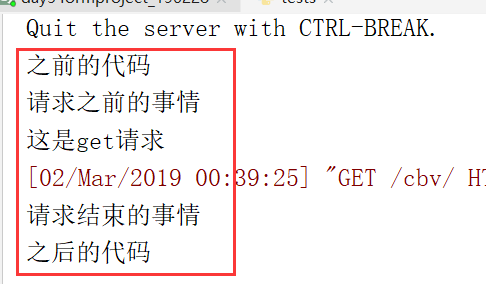
上边红图,说明mysql有问题,需要重启一下
返回,输入的内容
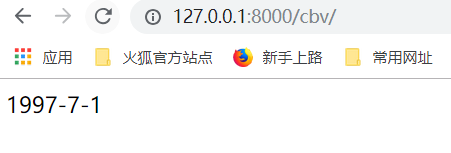
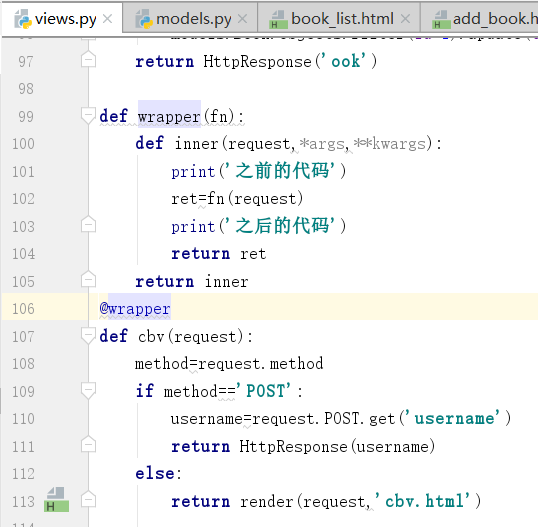
@wrapper==>cbv=wrapper(cbv)
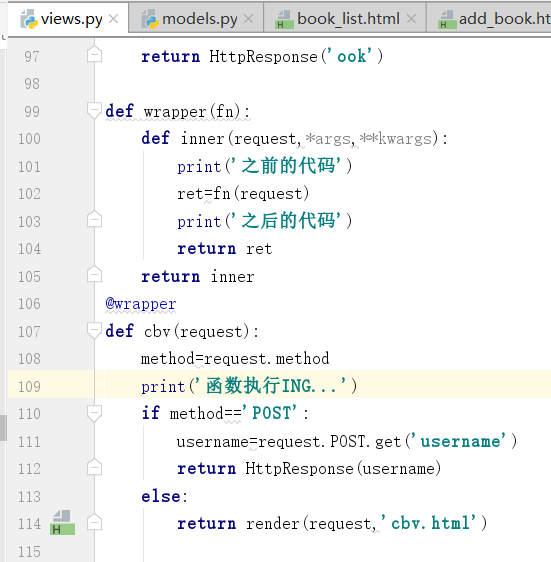
运行重启:
提交数据123,之后,返回123
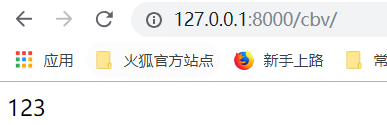
服务端得到结果:
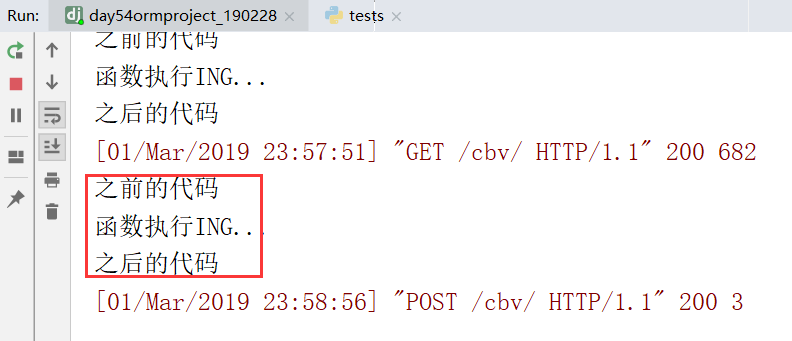
上边是FBV装饰器的使用
下边是CBV装饰器的使用:
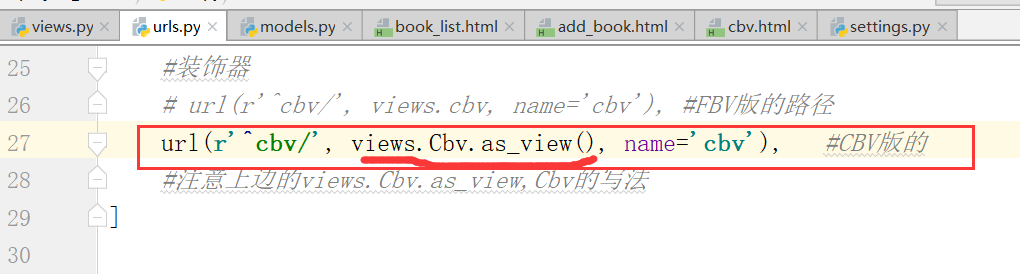
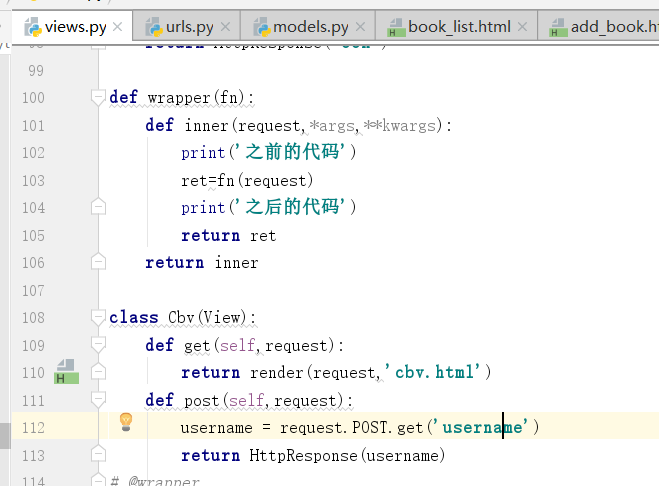

下面我们进行,加装饰器
,先演示dispatch
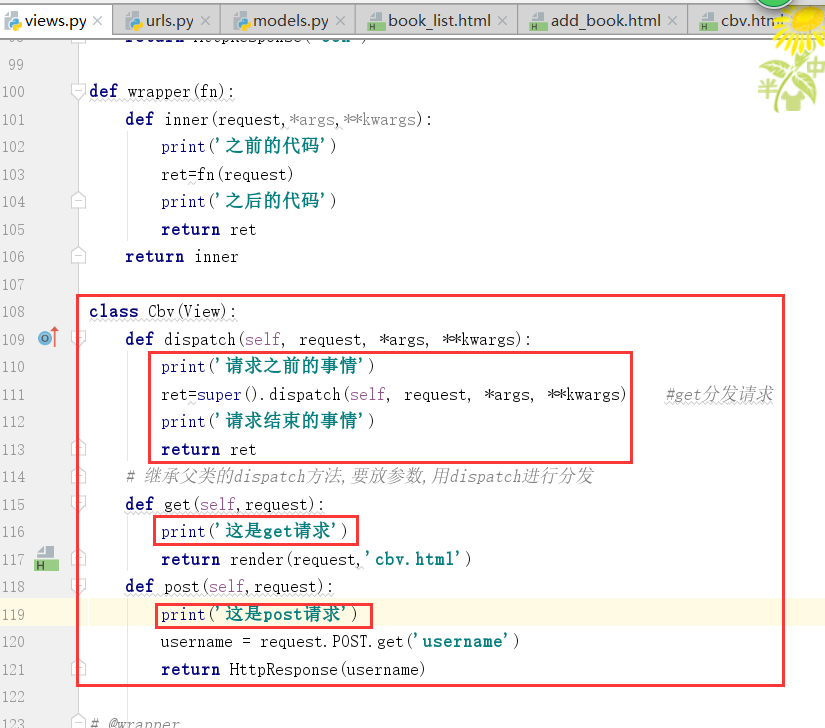
注意,上边的dispatch里边的,第一个框,没有self
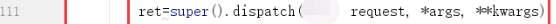
这时候,我们再重启看效果.
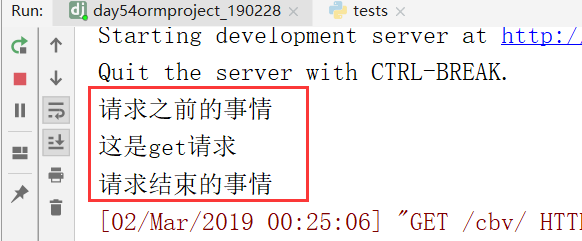
现在开始写装饰器,

开始,加入方法装饰器,
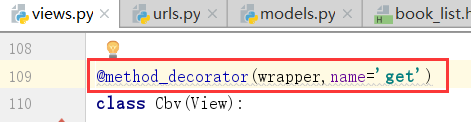
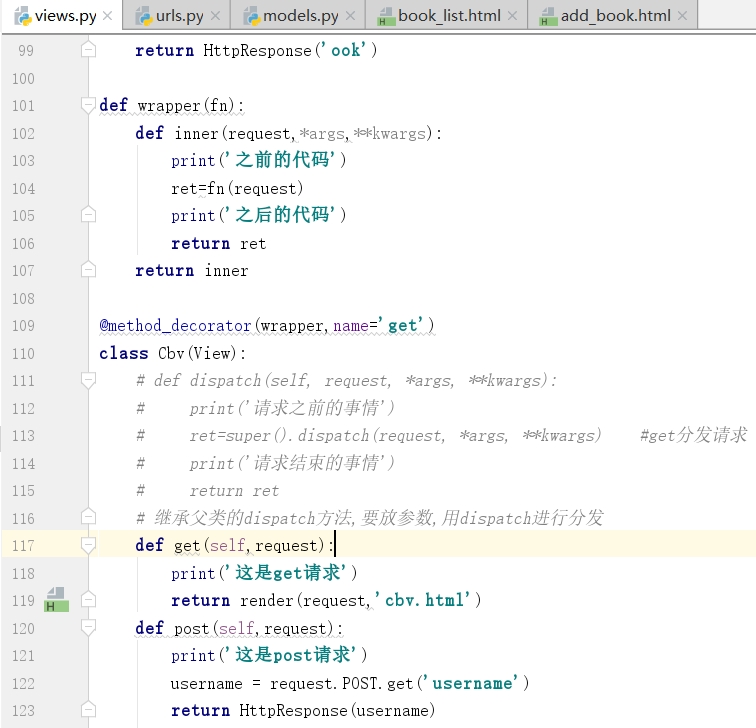

装饰器加成功了

第二种加法
运行


如果,想要两个都加,加在dispatch方法上边,

运行:


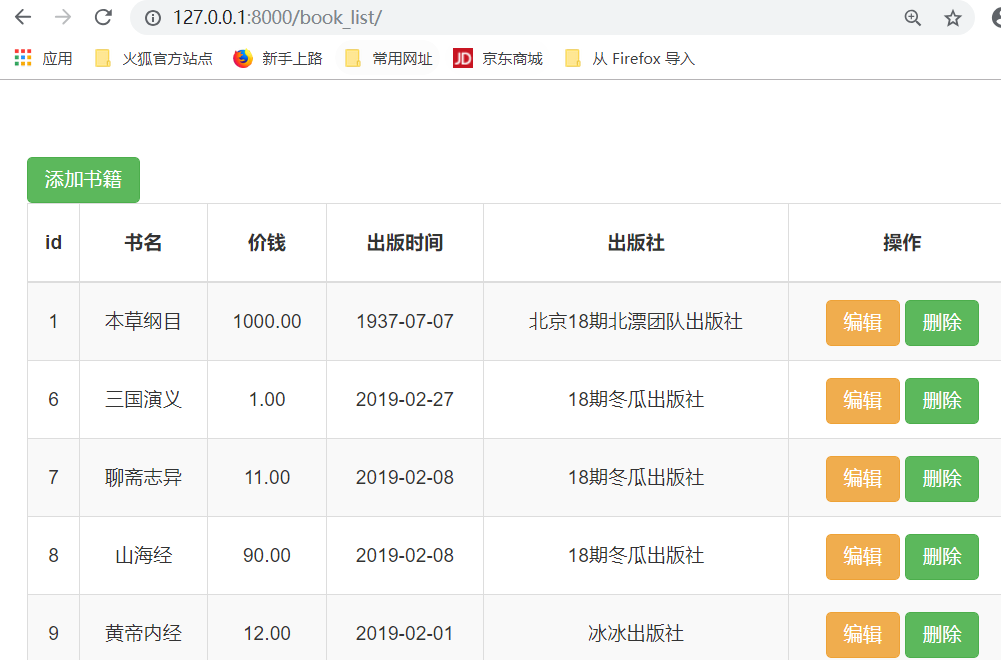
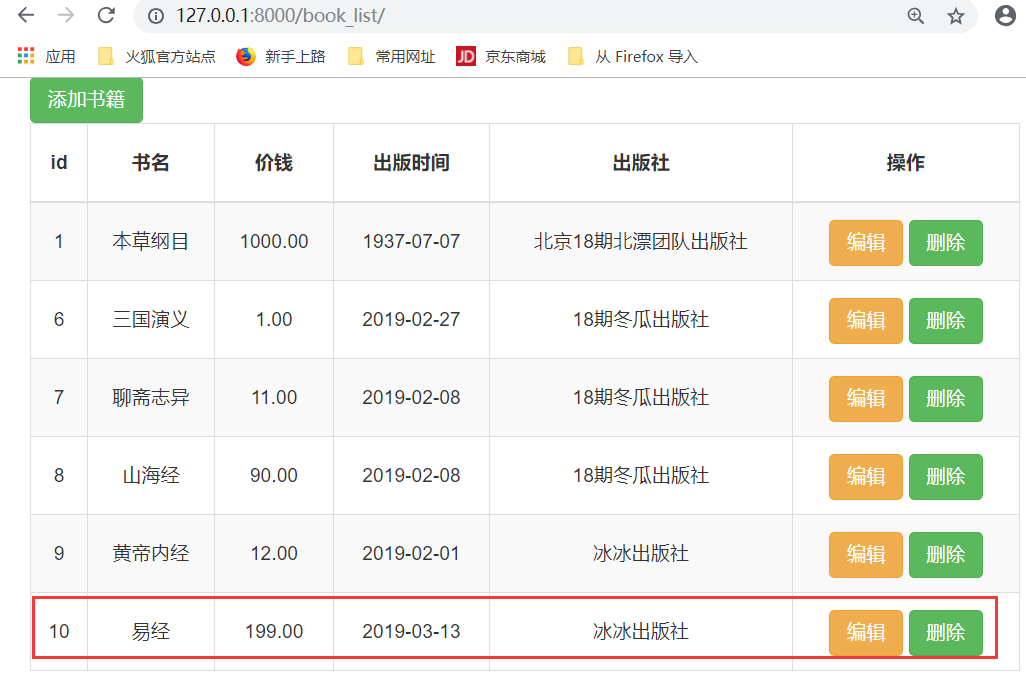
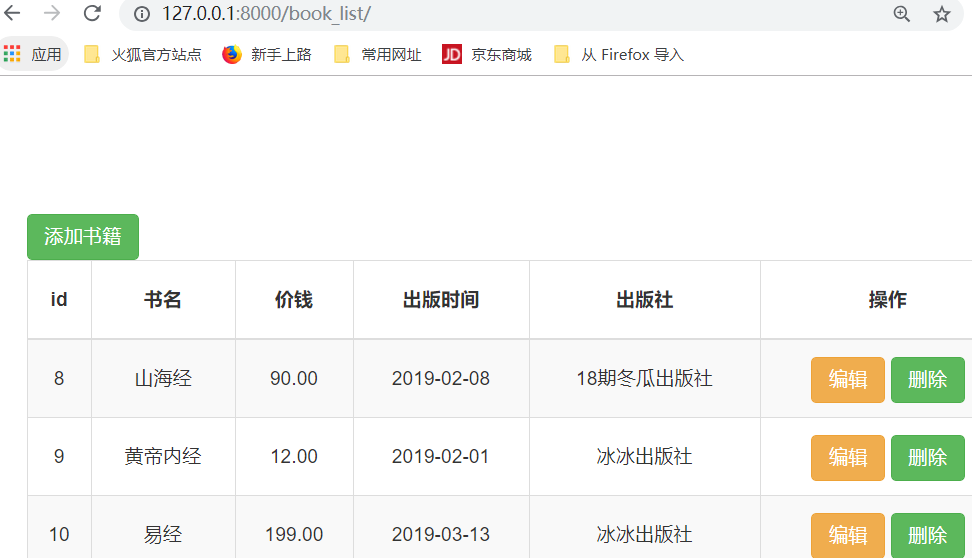
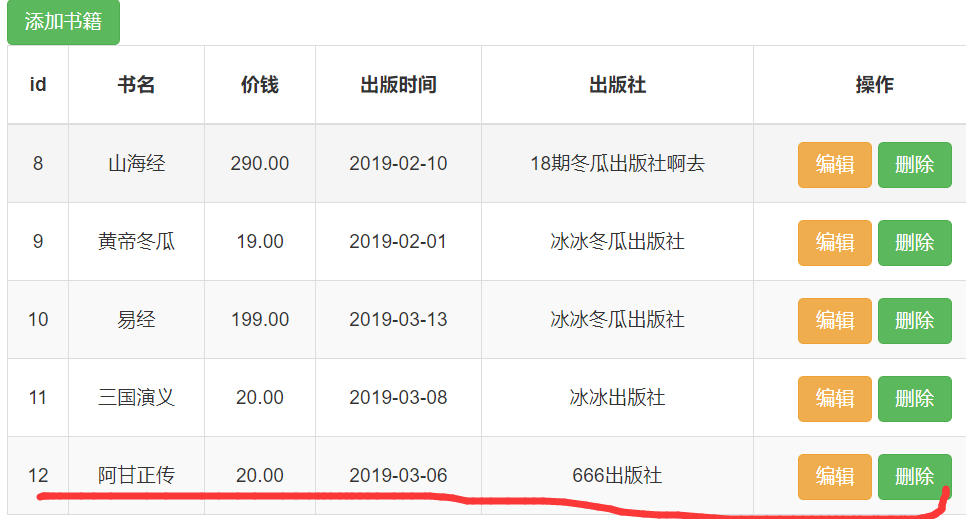
1.删除和编辑制图
首先,我们先添加几本书,
运行程序,
点击"添加书籍"
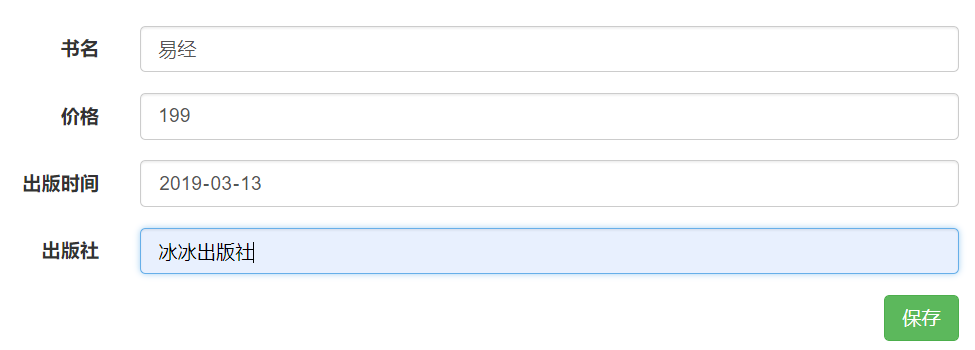
点击"保存"
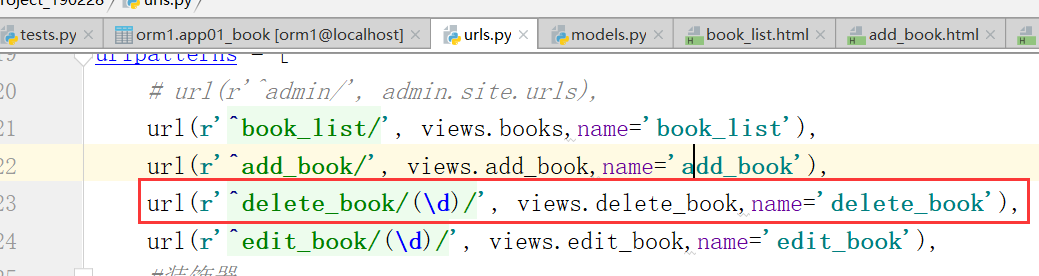
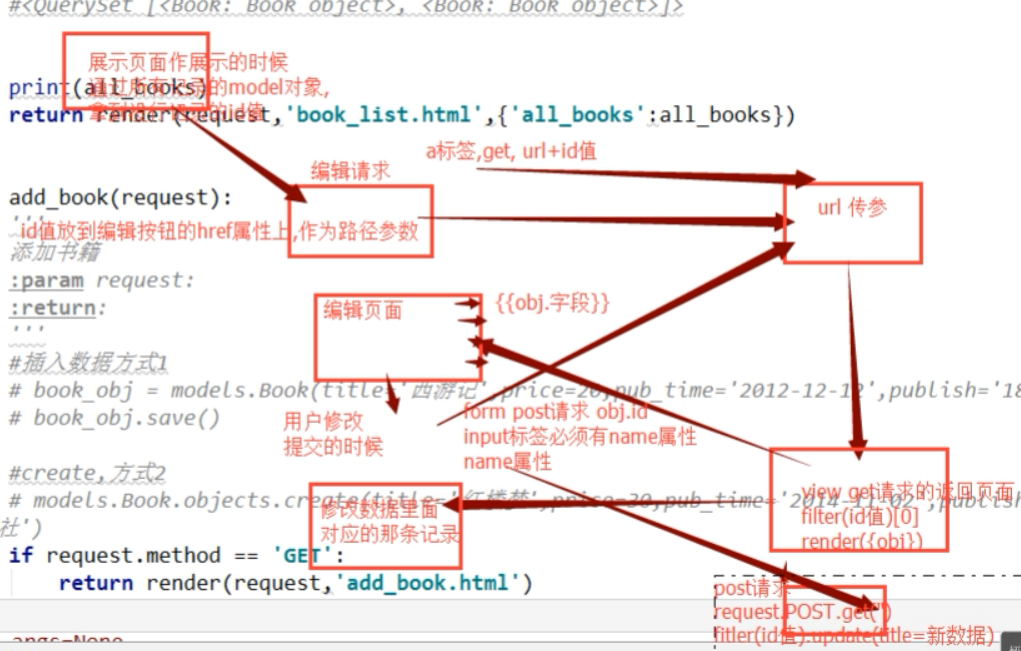
首先考虑,编辑和删除的这个过程应该干什么,第一步点击一下,向后端发送一个请求,点击删除,将后端数据库的内容删除,思考,点击删除怎么发送请求,思考,怎样就是这条数据,把这条数据删除???首先配置URL,前端和后端还没有写完.
删除这一页,要让用户,知道你已经删除了这一页
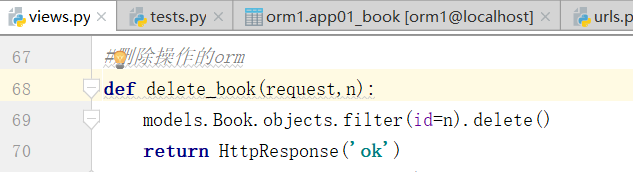
也就是让浏览器,再请求一次请求book_list

原来的删除按钮:
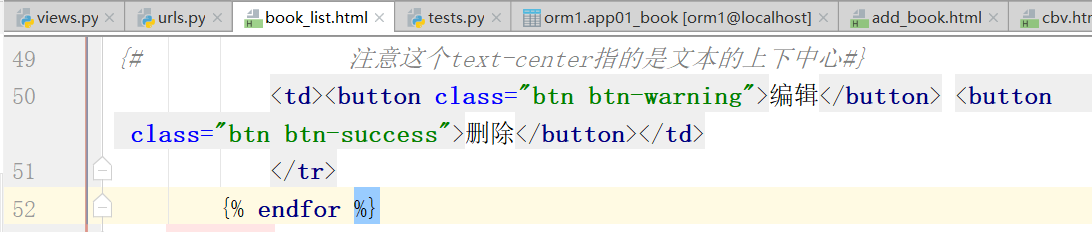
改成下面的删除按钮,button改成a,也就是一个连接(前端,找到后端的url路径,路径再找到函数处理列表,最后,再返回book_list)
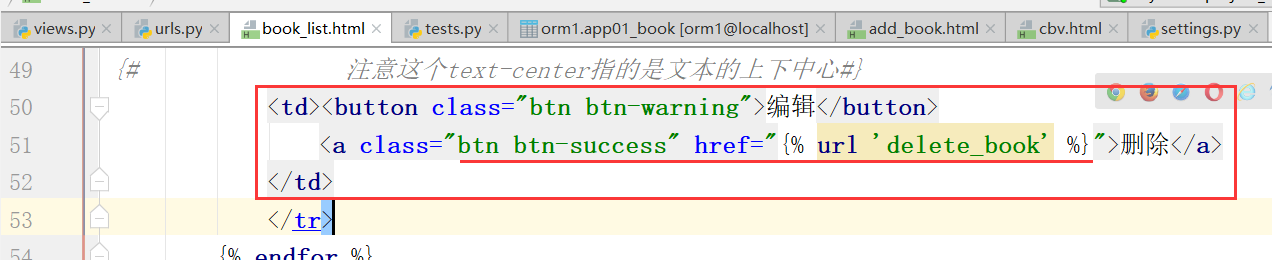
最后,还需要添加这本书的ID进行添加,

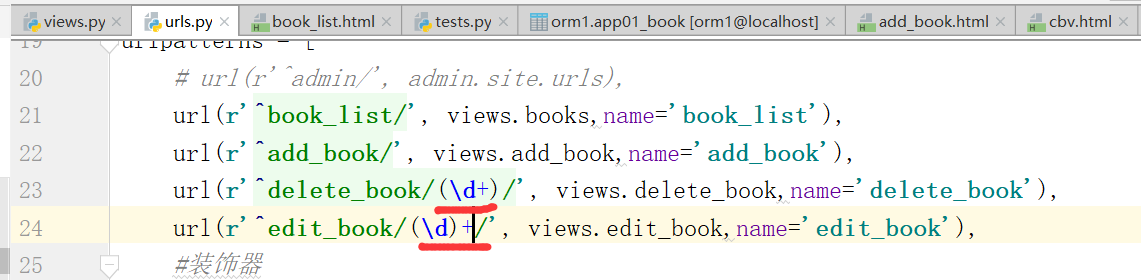
注意,这个url配置,需要加上数字,进行匹配,可能是多个数字
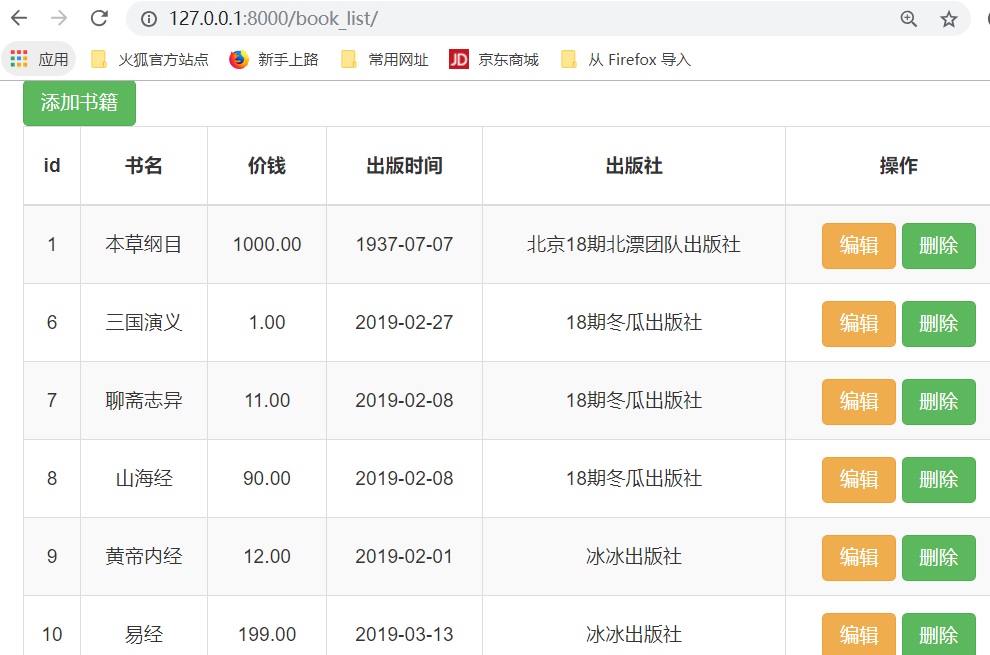
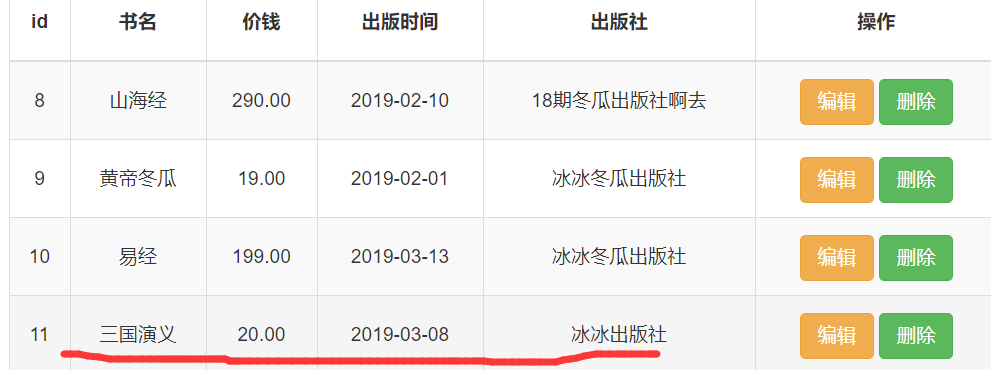
得到结果:

点击第一本书的,"删除",连续多次,得到下面的结果
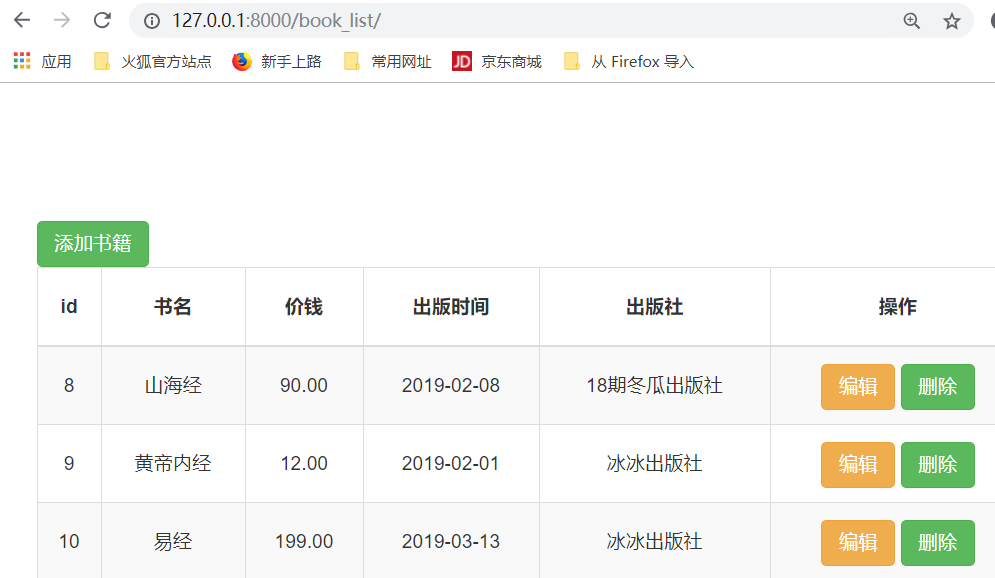
重定向,就是反复请求数据,得到最后一次刷新之后的结果
redirect就是发送给浏览器一个重定向的请求,浏览器拿到重定向的请求之后,调用location的方法,指定一个href,也就是自己指定的一个redirect,
返回指定的路径,拿到最新的数据,主动刷新页面
同样,编辑也是这样,(但是,后边这个one_book.id,虽然不是唯一的凡是,但是是最合适的,因为ID是唯一的自增的不重复的属性字段)


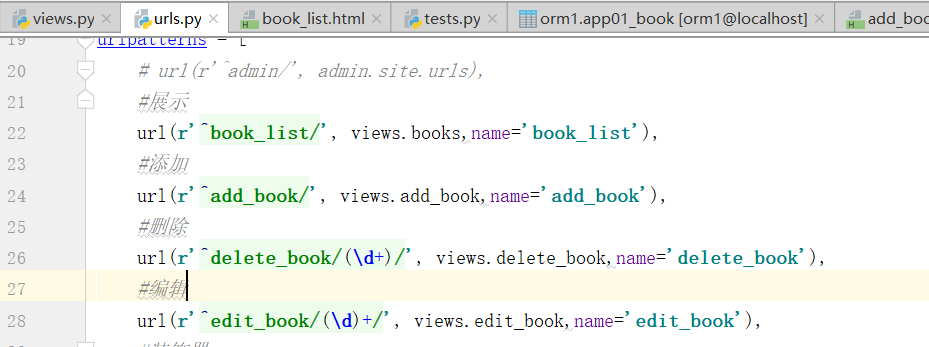
逻辑的写法
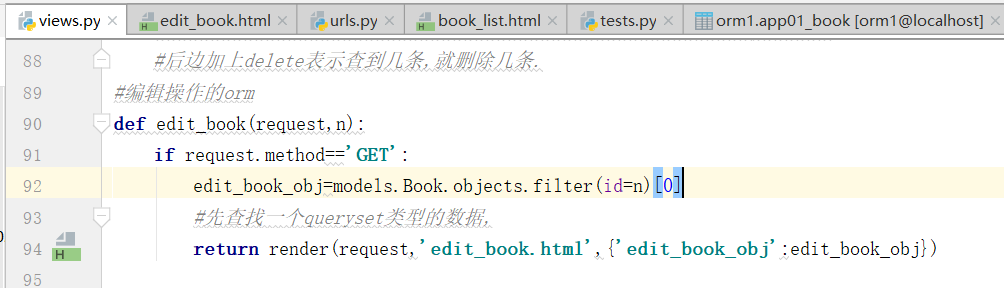
先写html页面,直接复制add_list复制,修改成edit页面

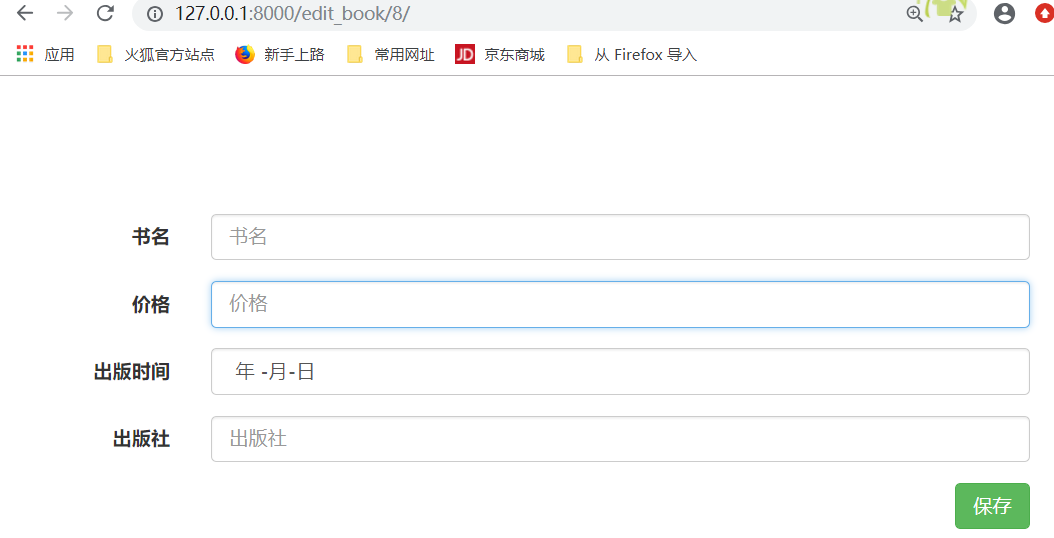
运行: 得到如下结果,点击编辑

点击编辑,得到如下结果:
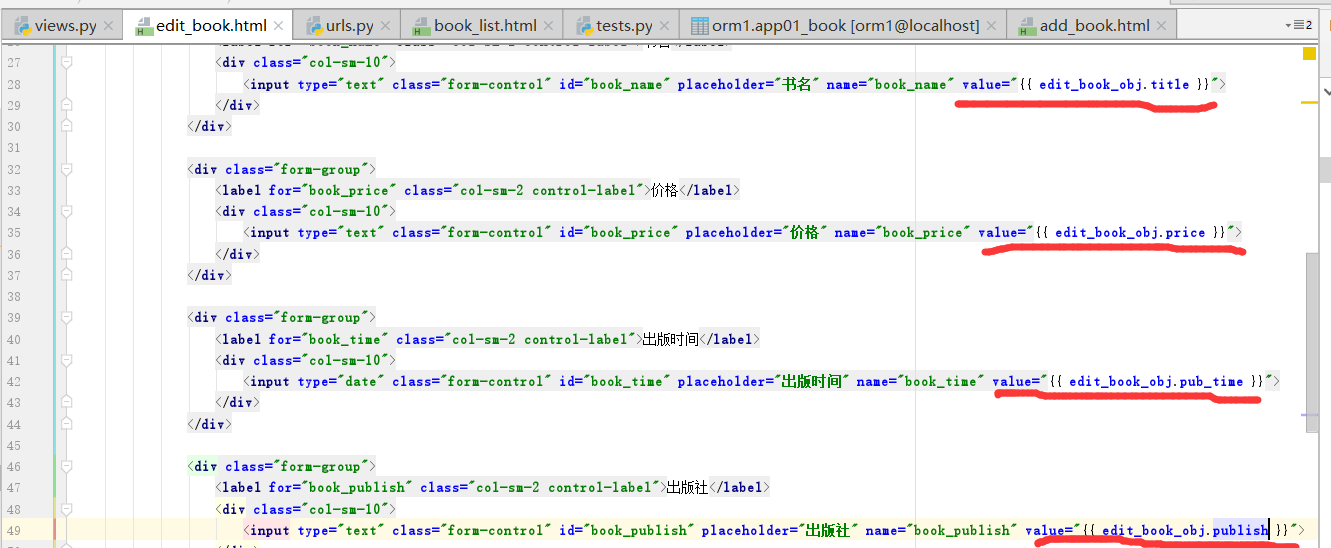
如何把默认值,放到指定的位置,在编辑页面,依次在input标签中添加,默认属性
运行:
点击编辑,
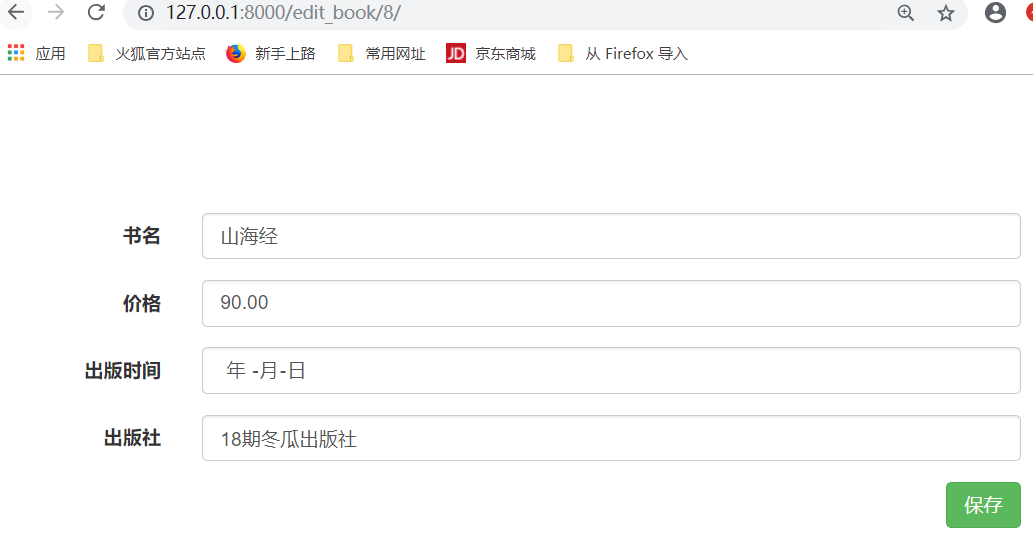
发现日期没有默认值,日期这个地方需要过滤器进行处理,才能过滤出来

刷新一下,就出现"出版时间"了

可以进行编辑,保存之后,跳转到book_list页面,
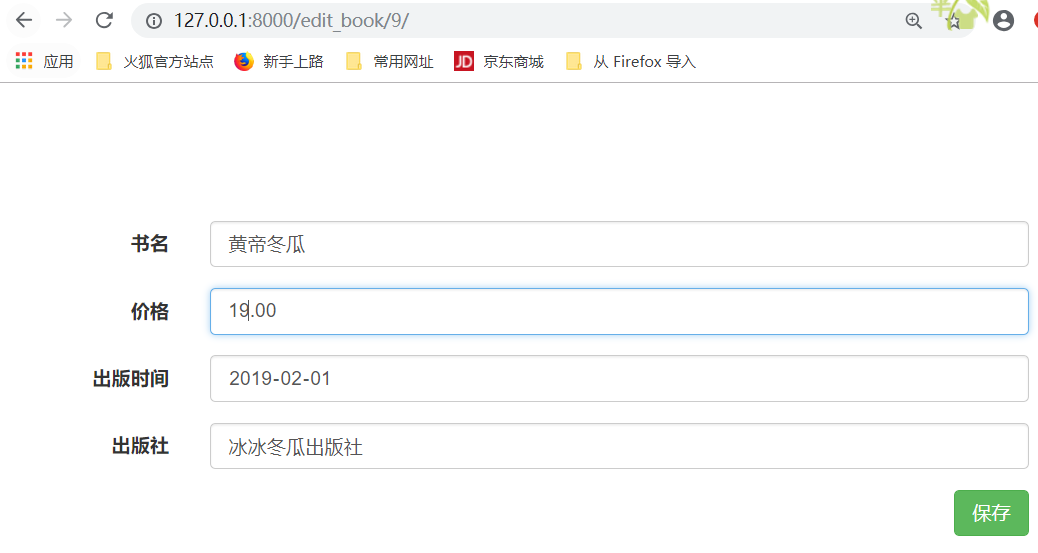
点击"保存",

此时,已经完成了修改.
2.编辑按钮的流程分析(这个地方还需要多推敲几遍)
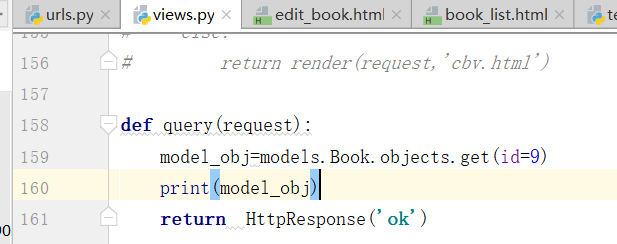
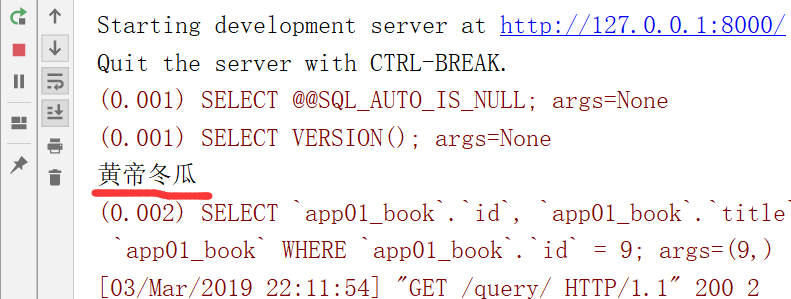
3.
13条查询的api,每条都是重点
<1> all(): 查询所有结果,结果是queryset类型 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象,结果也是queryset类型 Book.objects.filter(title='linux',price=100) #里面的多个条件用逗号分开,并且这几个条件必须都成立,是and的关系,or关系的我们后面再学,直接在这里写是搞不定or的 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,不是queryset类型,是行记录对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。捕获异常try。 Book.objects.get(id=1) <4> exclude(**kwargs): 排除的意思,它包含了与所给筛选条件不匹配的对象,没有不等于的操作昂,用这个exclude,返回值是queryset类型 Book.objects.exclude(id=6),返回id不等于6的所有的对象,或者在queryset基础上调用,Book.objects.all().exclude(id=6) <5> order_by(*field): queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值还是queryset类型 models.Book.objects.all().order_by('price','id') #直接写price,默认是按照price升序排列,按照字段降序排列,就写个负号就行了order_by('-price'),order_by('price','id')是多条件排序,按照price进行升序,price相同的数据,按照id进行升序 <6> reverse(): queryset类型的数据来调用,对查询结果反向排序,返回值还是queryset类型 <7> count(): queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量。 <8> first(): queryset类型的数据来调用,返回第一条记录 Book.objects.all()[0] = Book.objects.all().first(),得到的都是model对象,不是queryset <9> last(): queryset类型的数据来调用,返回最后一条记录 <10> exists(): queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False 空的queryset类型数据也有布尔值True和False,但是一般不用它来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits 例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT (1) AS `a` FROM `app01_book` LIMIT 1,就是通过limit 1,取一条来看看是不是有数据 <11> values(*field): 用的比较多,queryset类型的数据来调用,返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列,只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的。 <12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <13> distinct(): values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录






刚才,+写在括号外边
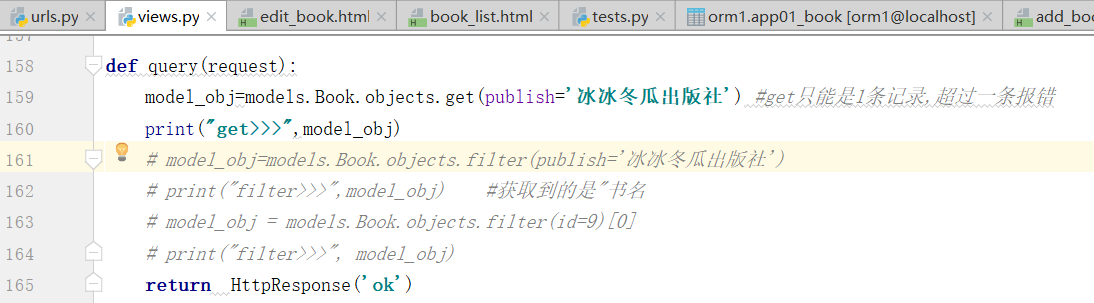
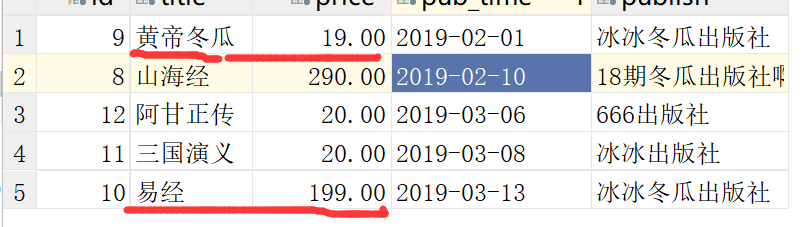
将易经的出版社,改成,冰冰冬瓜出版社

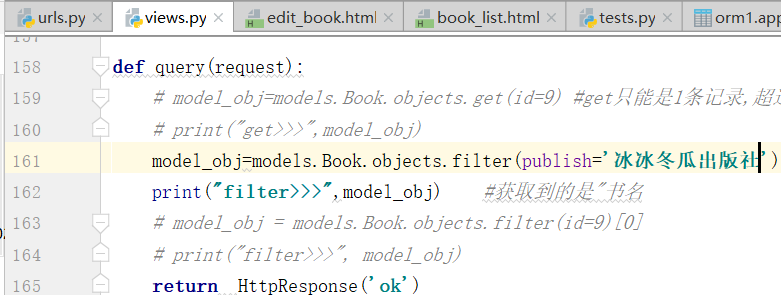
得到两条记录

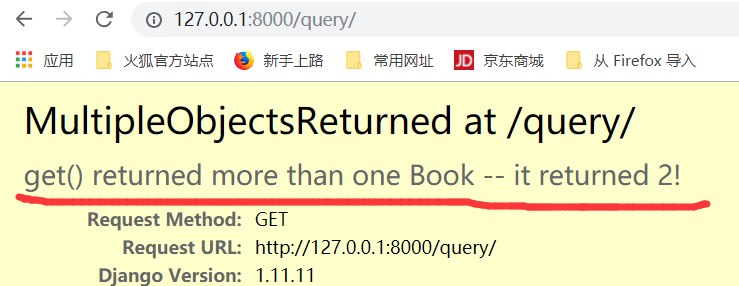
不能找的东西超过两个
get在找不到的情况下,会显示什么样呢?

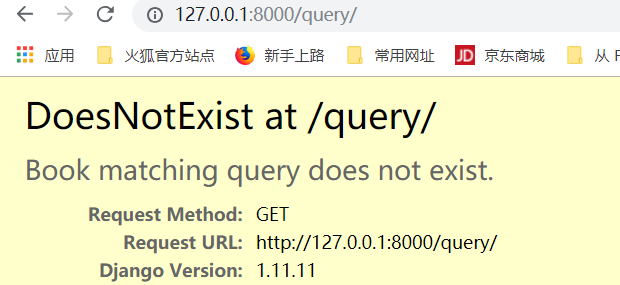

返回的是空,并且不报错,这个筛选器更加强大一些
!是否可以得到内容?
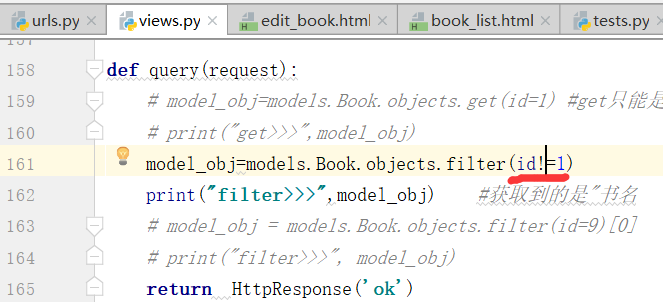
结果:布尔值是不可以迭代的 ,filter是循环多个条件的
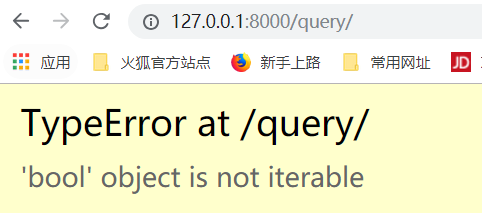
exclude,取反查询

下面是连续操作,也叫链接查询



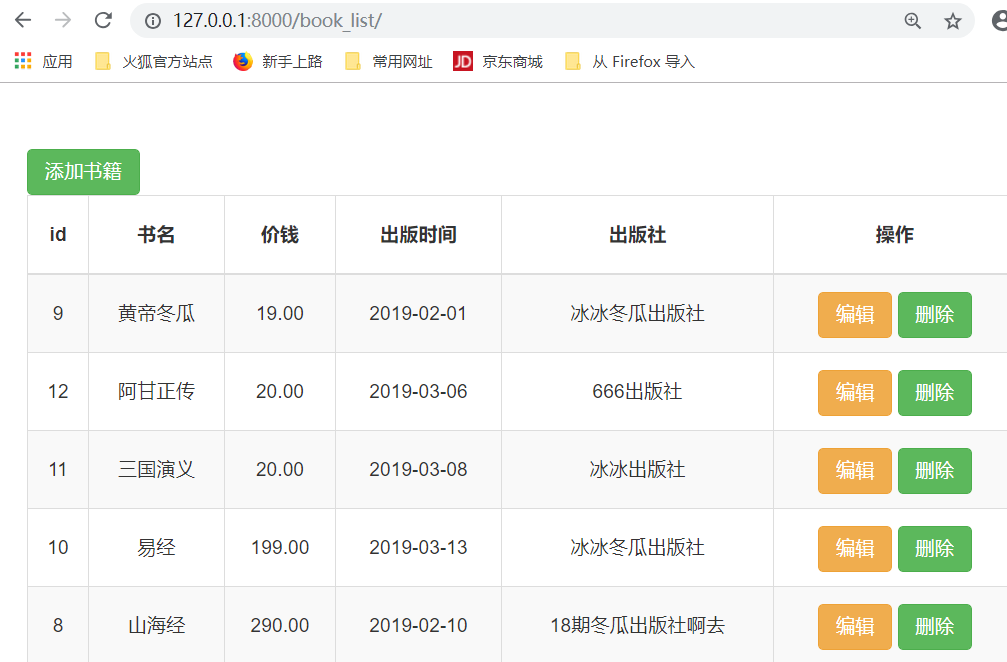
按照价格排序的结果:
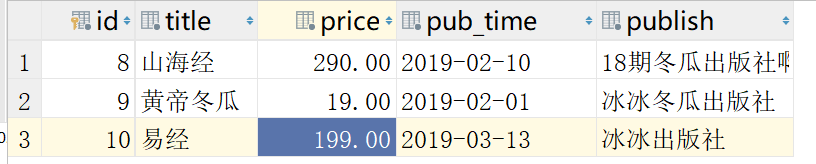
加上负号,表示倒序排列


价钱相同的再排序,第一个相同,按照第二个条件排序
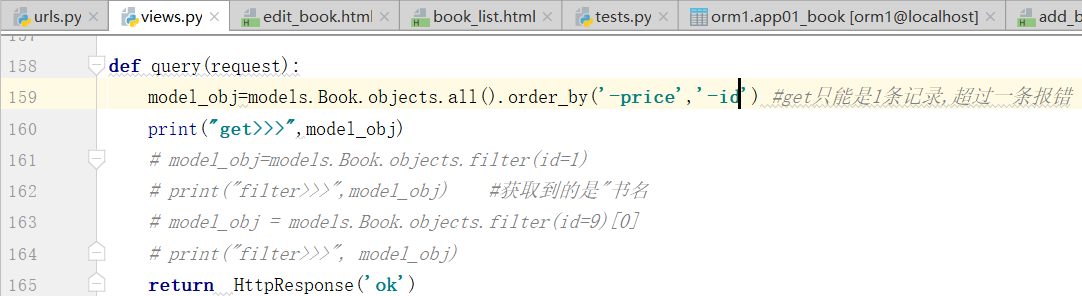
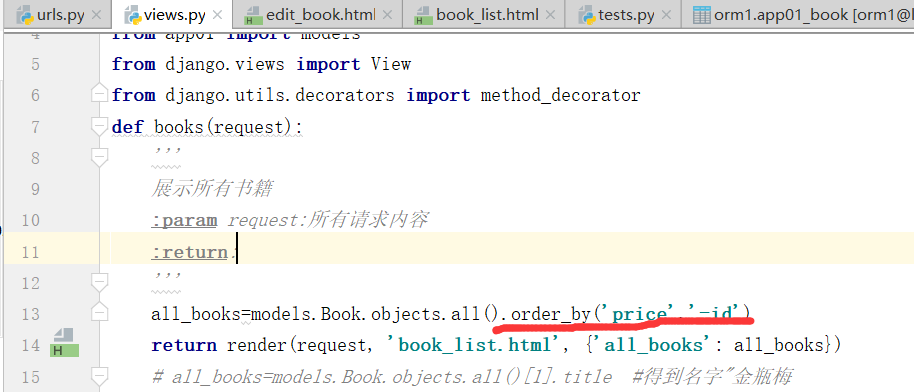
先按照价格排序,再按照id的倒序排序.


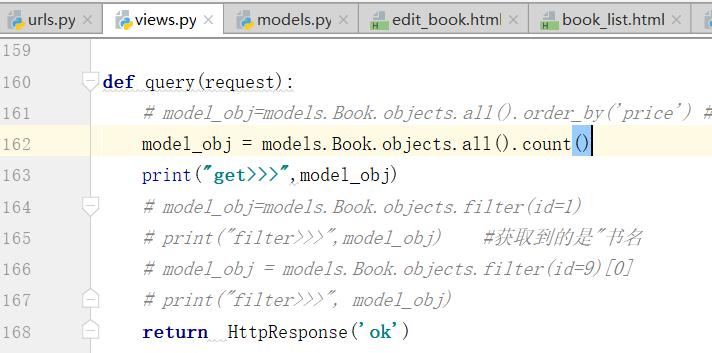
查看总共有多少个对象


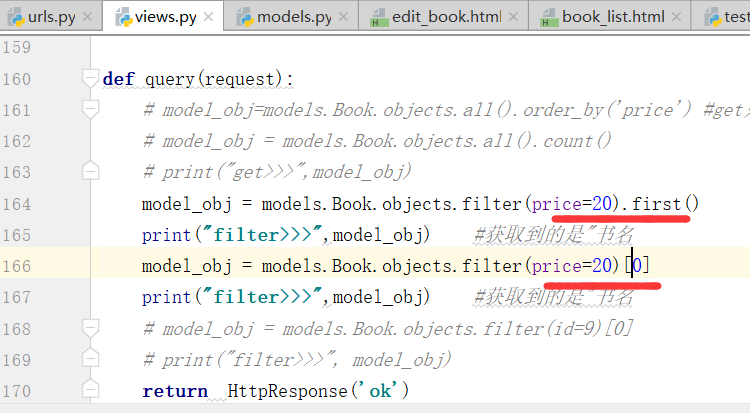
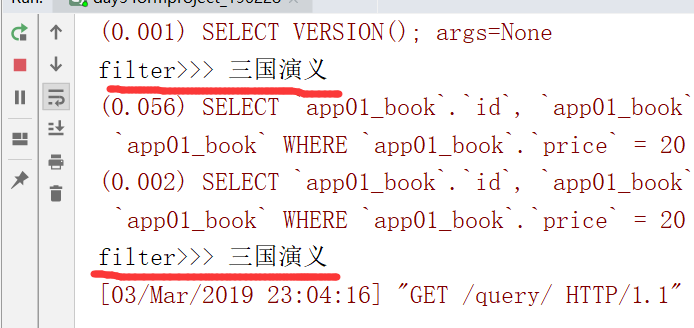

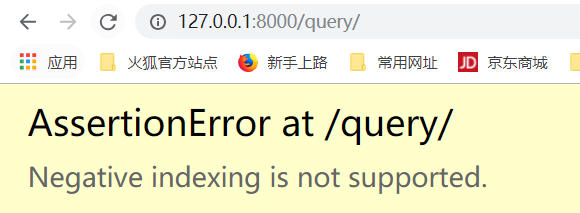
注意,这个地方不支持写-1
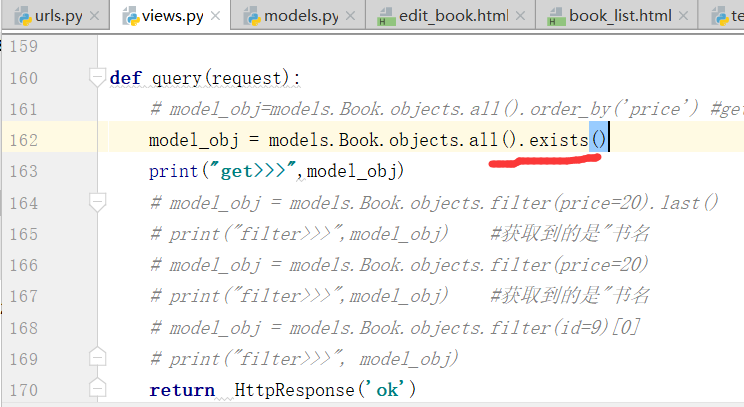
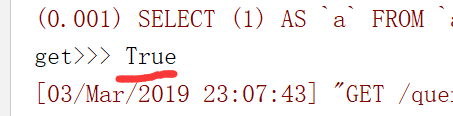
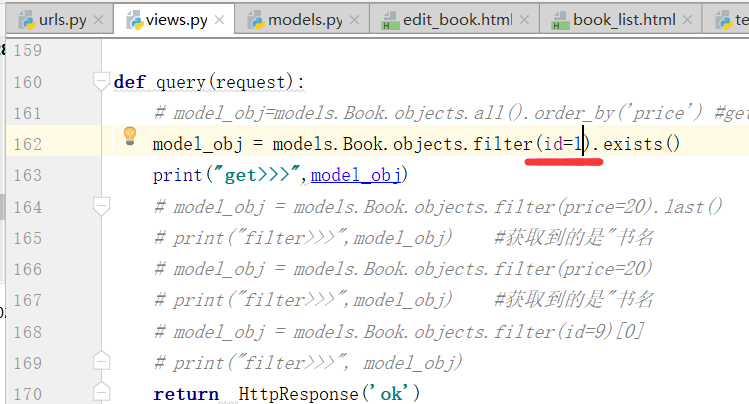
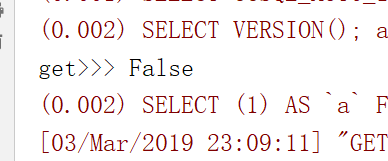
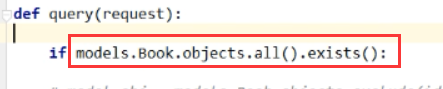
取其中一条进行判断,提高效率,在这个地方如果只写all()的话,效率会比较低
![]()
计数用count也是可以的.



values()整个过程类似下图:

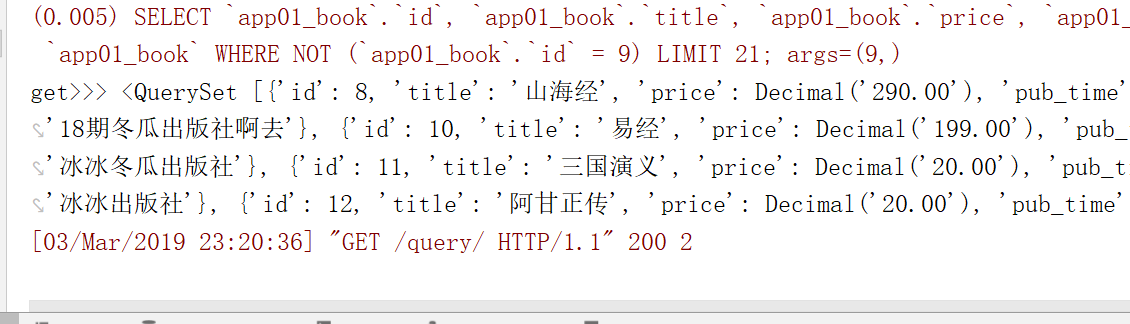
排除id=9的方法
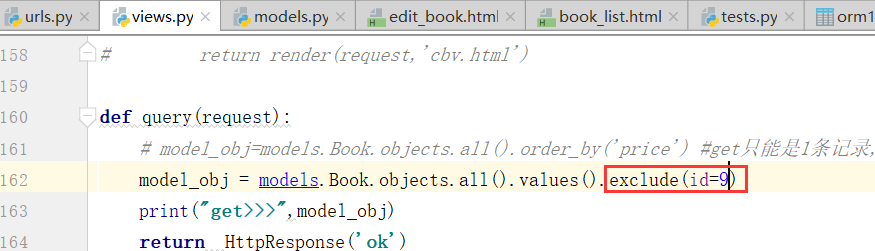
结果已经没有9了
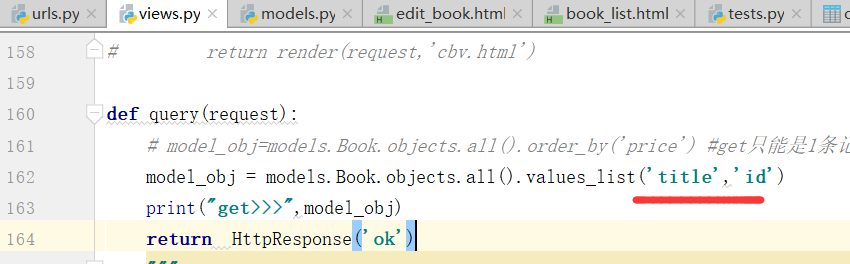
values_list()

最终,里边的数据,变成了元组
参数的妙用,values,也和下图一样
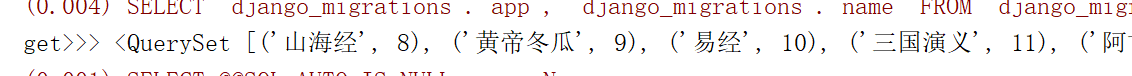
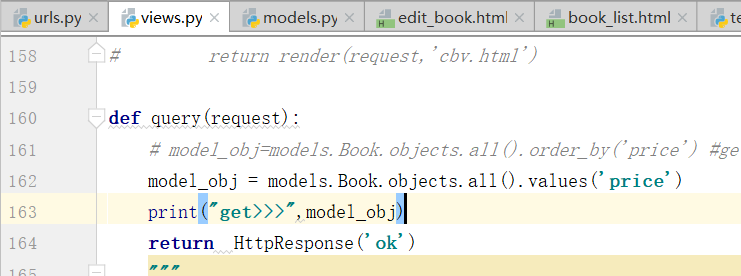

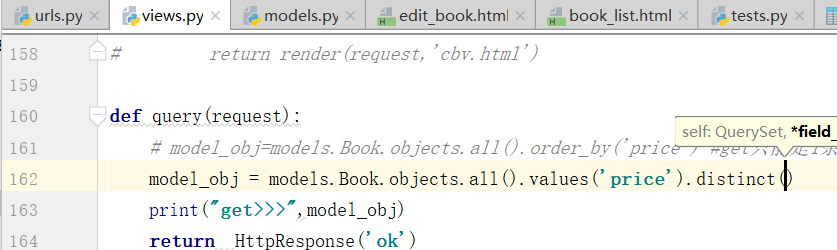

mysql的写法
select distinct name from xxx;
select distinct name title from xxx;
4.单表查询的其他方法
模糊查询:
_:一个字符
%:所有
like
正则
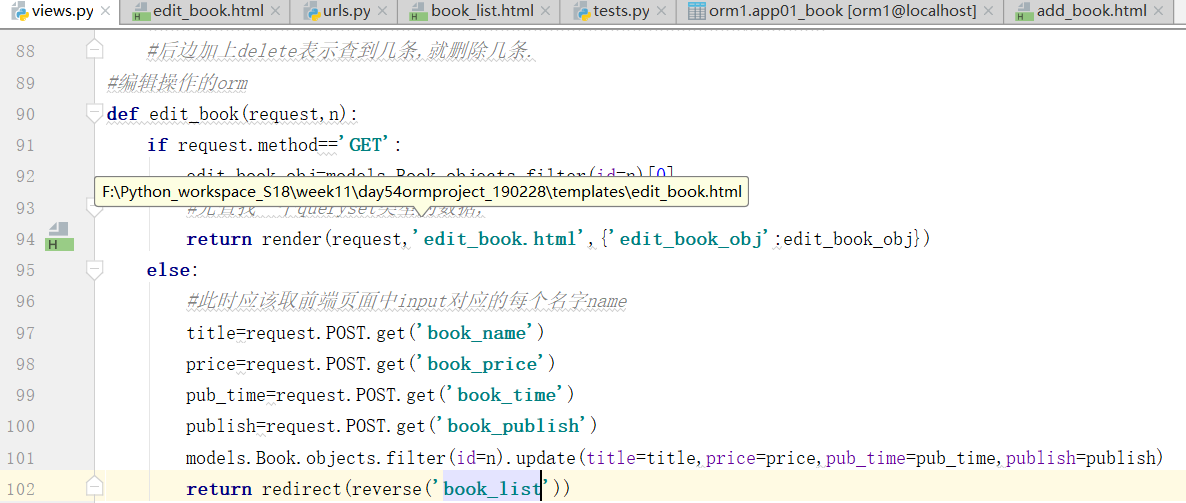
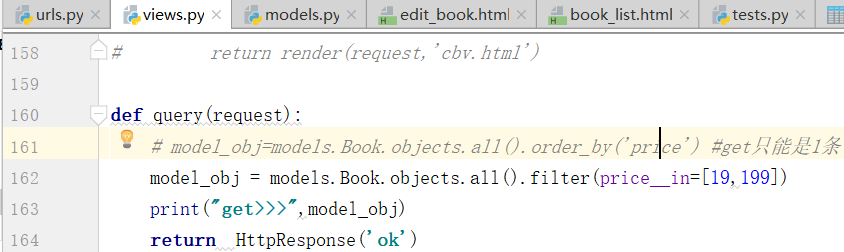
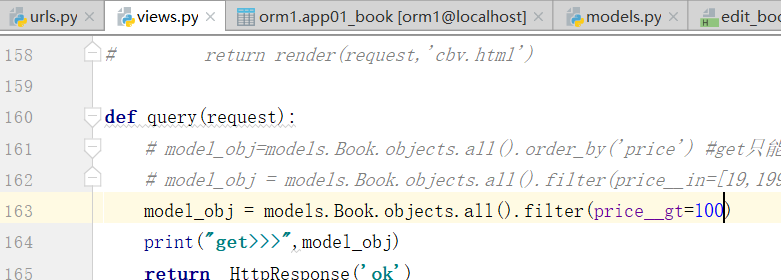
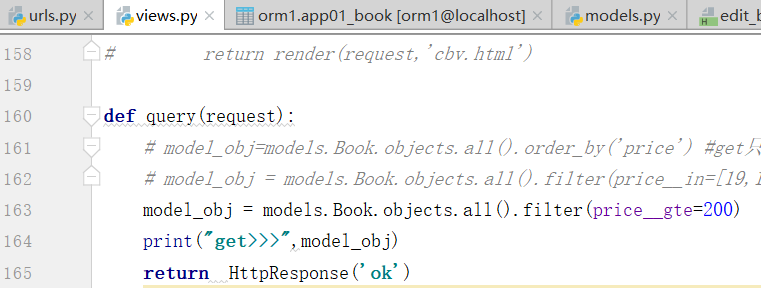
Book.objects.filter(price__in=[100,200,300]) #price值等于这三个里面的任意一个的对象 Book.objects.filter(price__gt=100) #大于,大于等于是price__gte=100,别写price>100,这种参数不支持 Book.objects.filter(price__lt=100) Book.objects.filter(price__range=[100,200]) #sql的between and,大于等于100,小于等于200 Book.objects.filter(title__contains="python") #title值中包含python的 Book.objects.filter(title__icontains="python") #不区分大小写 Book.objects.filter(title__startswith="py") #以什么开头,istartswith 不区分大小写 Book.objects.filter(pub_date__year=2012)
面试的SQL语句:多表查询,&&左右连接等等.



因为失去问题,
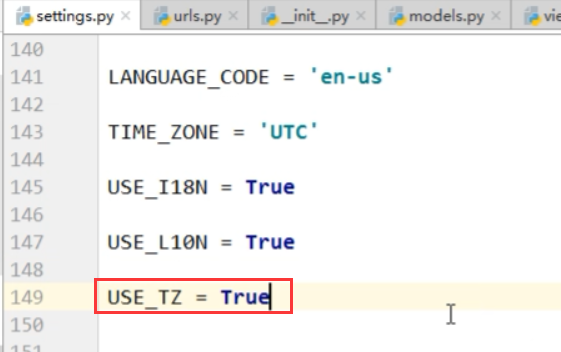
修改下面的属性,变成本地的时间
本地时间localtime和UTC相差8个小时.
注意:
删除的时候get和filter两种方法都能用
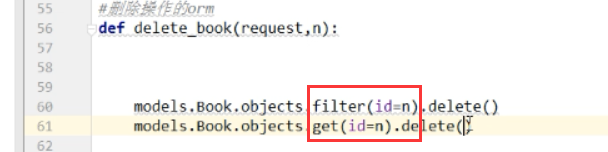
而update更新,必须是queryset(也就是filter),也就是update无法调用models,而必须是queryset类型才能调用更新,不能用get方法


 浙公网安备 33010602011771号
浙公网安备 33010602011771号