ScrapySpider的使用
### 设置控制台打印的Log等级
# setings文件
# 设置只打印warning以上等级的日志信息
LOG_LEVEL = 'WARNING'
在在爬虫主文件写爬取代码,使用scrapy.Request请求。
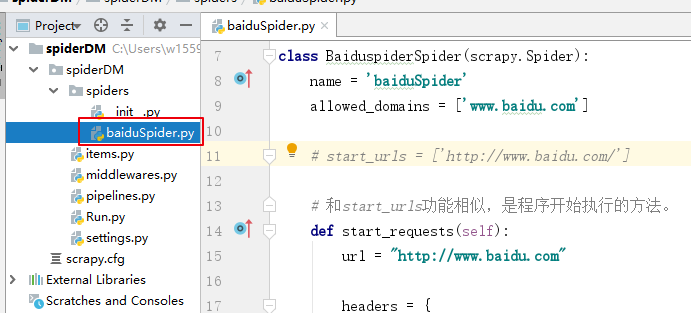
# baiduSpider.py文件
import scrapy
from spiderDM.items import SpiderdmItem
class BaiduspiderSpider(scrapy.Spider):
name = 'baiduSpider'
allowed_domains = ['www.baidu.com']
# start_urls = ['http://www.baidu.com/']
# 和start_urls功能相似,是程序开始执行的方法。
def start_requests(self):
url = "http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
cookies = {
"cookie": "_zap=14ce0193-6056-4233-a292-697015b7845f"
}
item = {"data": "information"}
yield scrapy.Request(
url=url, # 请求的URL
method="GET", # 请求的方式,默认GET
headers=headers, # 请求头携带信息
meta=item, # 需要携带给回调函数的数据
dont_filter=False, # 是否筛选这个URL,默认False
callback=self.parse # 设置回调函数(下一个执行的函数)
)
def parse(self, response):
# 创建item对象
item = SpiderdmItem()
# 获取meta里的数据;注意:获取的是浅度拷贝(复制数据的引用地址),注意后面操作对值的覆盖。深度复制:deepcopy
item["data"] = response.meta["data"]
print(item["data"])
# 发送数据给管道
# yield item
运行爬虫结果

使用scrapy.FormRequest请求。
# baiduSpider.py文件
import scrapy
from spiderDM.items import SpiderdmItem
class BaiduspiderSpider(scrapy.Spider):
name = 'baiduSpider'
allowed_domains = ['www.baidu.com']
# start_urls = ['http://www.baidu.com/']
# 和start_urls功能相似,是程序开始执行的方法。
def start_requests(self):
url = "http://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
cookies = {
"cookie": "_zap=14ce0193-6056-4233-a292-697015b7845f"
}
item = {"data": "information"}
yield scrapy.FormRequest(
url=url, # 请求的URL
headers=headers, # 请求头
formdata=dict( # 请求网页时发送的数据
userName="make",
passWord="make"
),
meta=item, # 携带给回调函数的数据
callback=self.parse, # 回调函数
)
def parse(self, response):
# 创建item对象
item = SpiderdmItem()
# 获取meta里的数据
item["data"] = response.meta["data"]
print(item["data"])
# 发送数据给管道
# yield item
运行结果相同。
两种请求方式的应用场景
scrapy.Request:主要应用GET网页数据时应用。
scrapy.FormRequest:主要应用发送POST来获取数据和登录时应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号