Hadoop伪分布式配置
系统:Centos6.5
创建需要的文件夹
进入安装包文件夹
mkdir /opt/jdk
mkdir /opt/hadoop
安装jdk
解压缩jdk安装包
tar -zxvf jdk-8u144-linux-x64.tar.gz
移动文件夹jdk1.8.0_144到/opt/java下面,并改名为jdk1.8
mv jdk1.8.0_144/ /opt/jdk/jdk1.8
配置jdk的环境变量
vim /etc/profile
在末尾空白行添加如下信息
#Java Config
export JAVA_HOME=/opt/jdk/jdk1.8
export JRE_HOME=/opt/jdk/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
修改环境变量后都要刷新文件才能生效
source /etc/profile
测试是否配置成功
java -version

配置环境变量
#Java Config
export JAVA_HOME=/opt/jdk/jdk1.8
export JRE_HOME=/opt/jdk/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
# Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.7
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# PATH config
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
Hadoop2.7.3伪分布式配置
解压文件,并移动解压后的文件重名为 /opt/hadoop/hadoop2.7
配置环境变量,参考/etc/profile的 # Hadoop Config
到现在配置的为Hadoop的默认的 "Hadoop单机配置"
cd /opt/hadoop/hadoop2.7/etc/hadoop/
gedit hadoop-env.sh
修改如下信息:
export JAVA_HOME=/opt/jdk/jdk1.8
gedit core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/hadoop2.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://本机IP:9000</value>
</property>
</configuration>
gedit hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop2.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hadoop2.7/tmp/dfs/data</value>
</property>
</configuration>
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
cd /opt/hadoop/hadoop2.7/
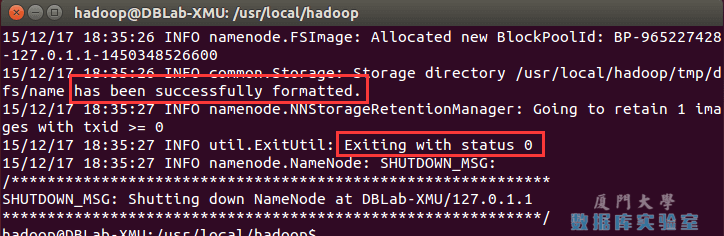
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
启动hdfs
/opt/hadoop/hadoop2.7/sbin/start-dfs.sh
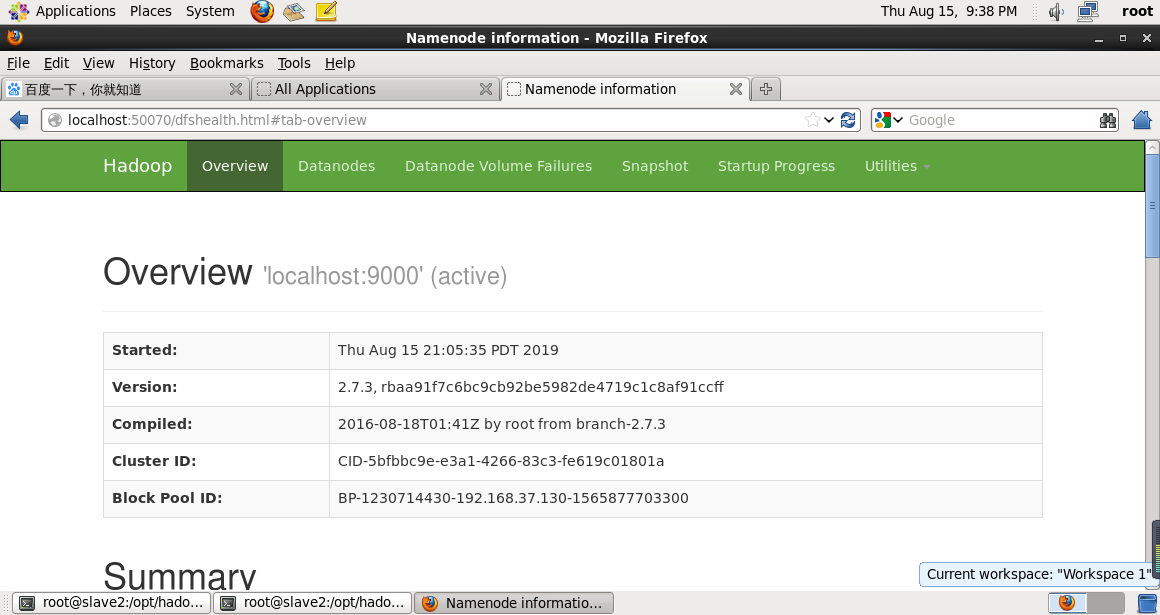
查看启动情况
http://localhost:50070
yarn配置
cd /opt/hadoop/hadoop2.7/etc/hadoop/
mv mapred-site.xml.template mapred-site.xml
gedit mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
gedit yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动hdfs
/opt/hadoop/hadoop2.7/sbin/start-dfs.sh
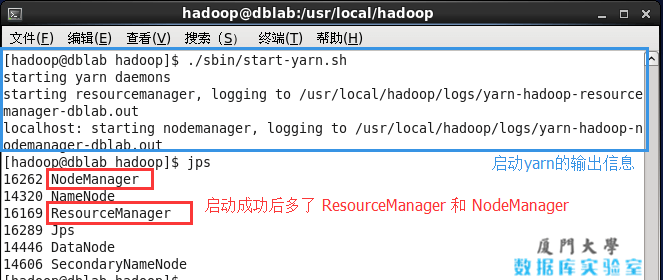
启动yarn
/opt/hadoop/hadoop2.7/sbin/start-yarn.sh
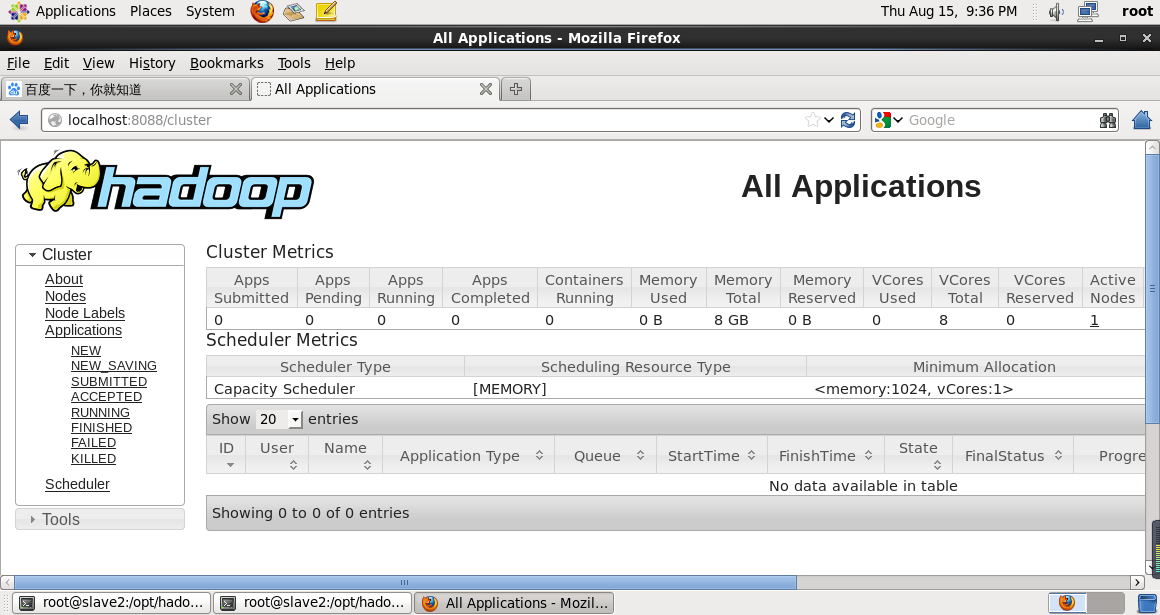
查看启动情况
http://localhost:8088/cluster

 浙公网安备 33010602011771号
浙公网安备 33010602011771号