
Spark_scala_Maven项目创建
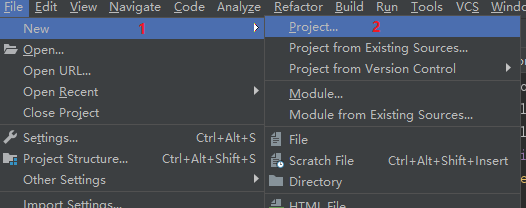
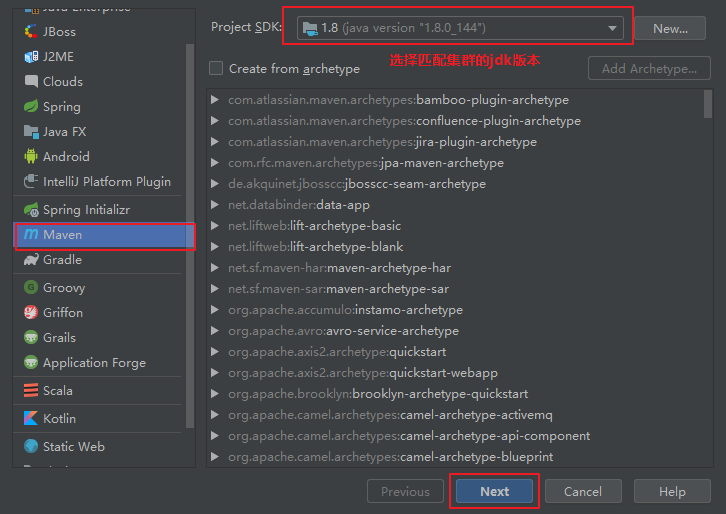
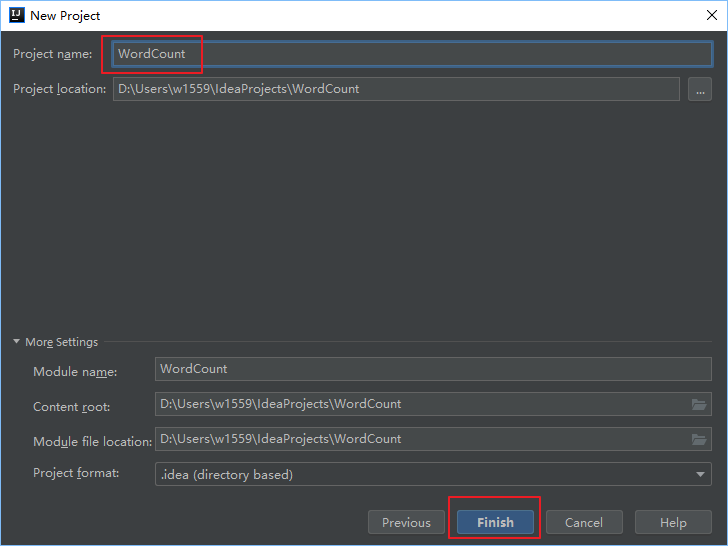
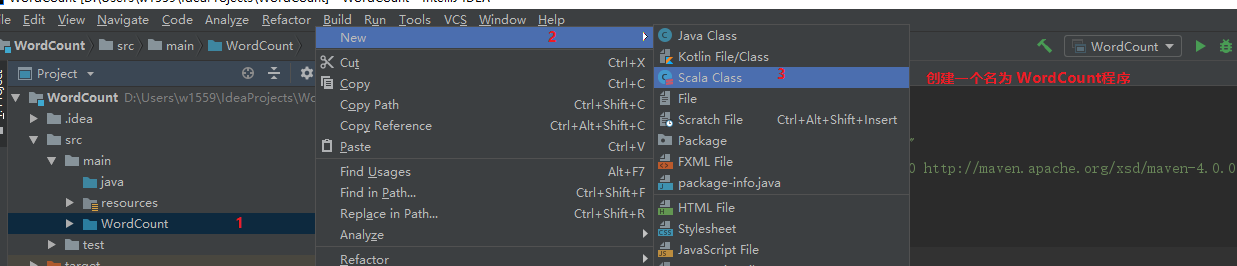
### IDEA创建WordCount Maven项目

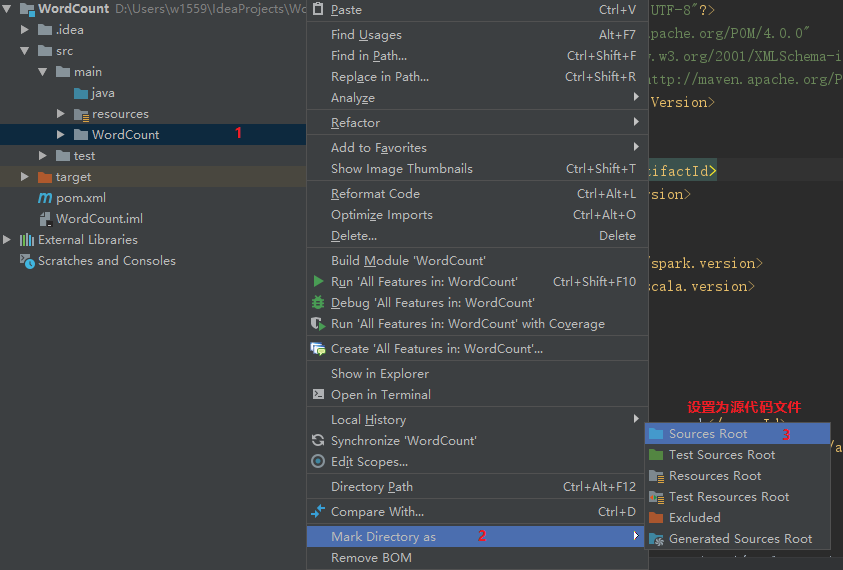
创建WordCount源文件

words.text 内容
this is one line
this is two line
WordCount源码
说明参考: https://www.cnblogs.com/studyNotesSL/p/11367751.html
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// 本地 /words.txt 文件
val inputFile = "file:///words.txt"
// hdfs上 /words.txt 文件
// val inputFile = "hdfs://master:9000/words.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(",")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
// 停止sc,结束该任务
sc.stop()
}
}
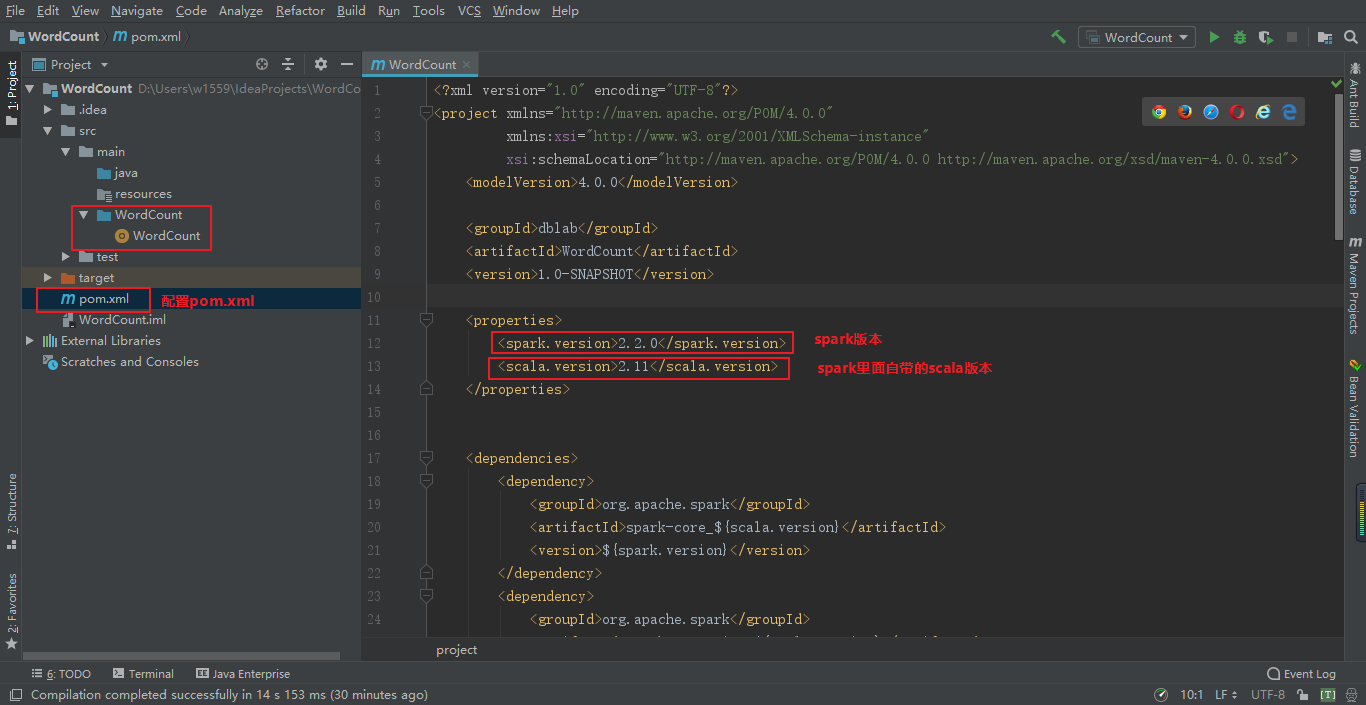
pom.xml源码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.2.0</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
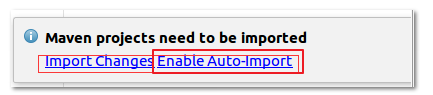
选择 Enables Auto-Import
打包spark程序
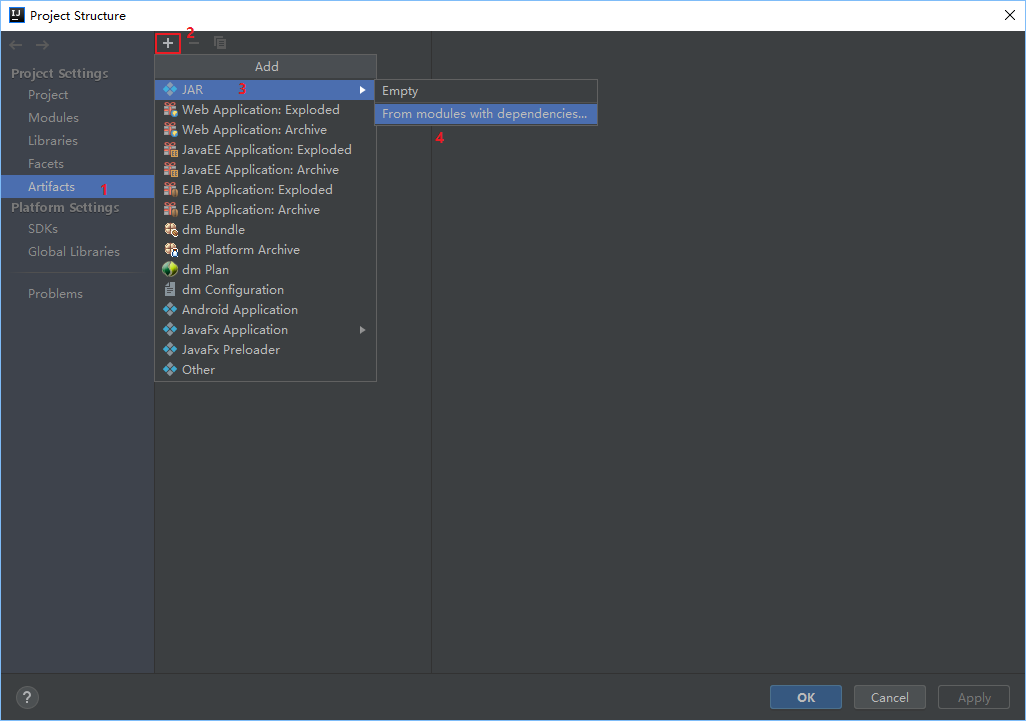

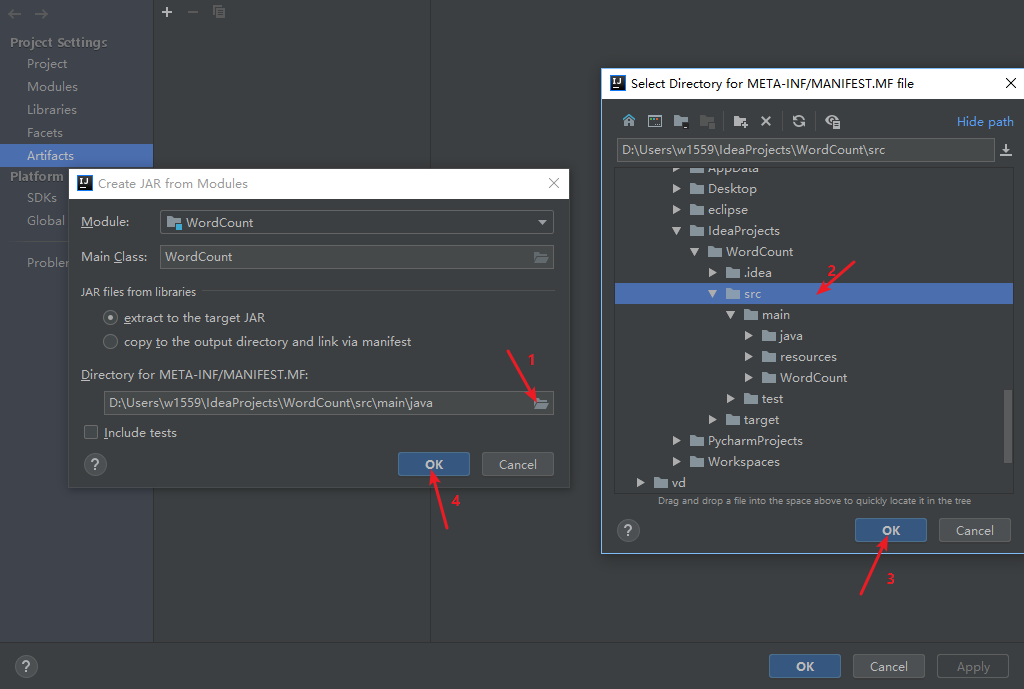
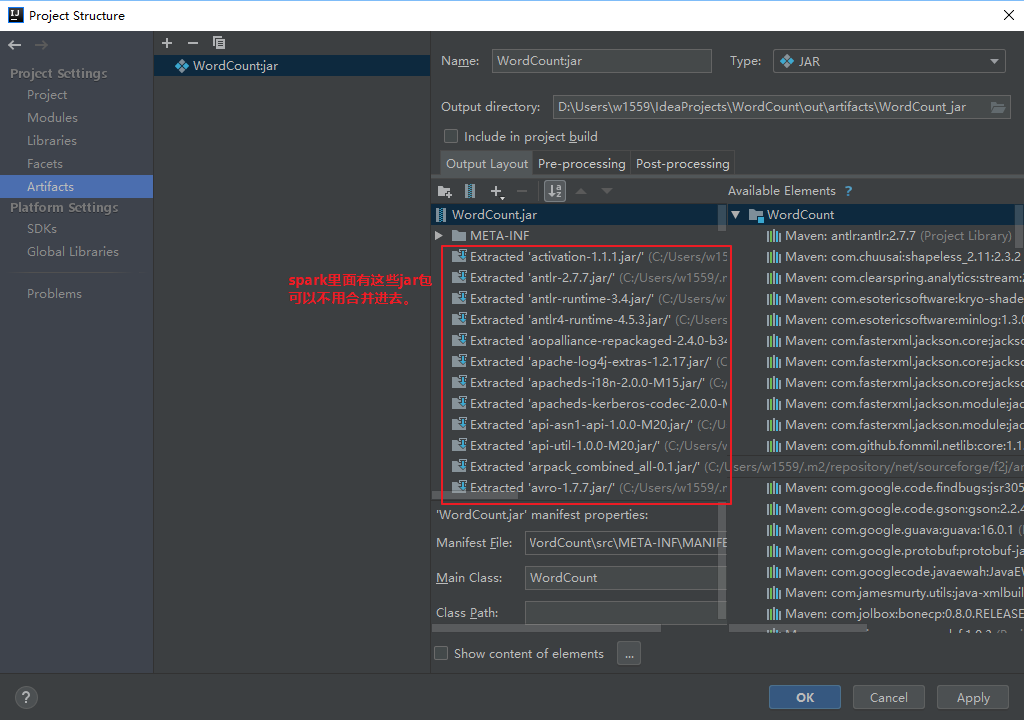
删除多余jar包只留下如下图的文件(Ctrl+A全选,Ctrl+鼠标左键选择需要留下的文件)
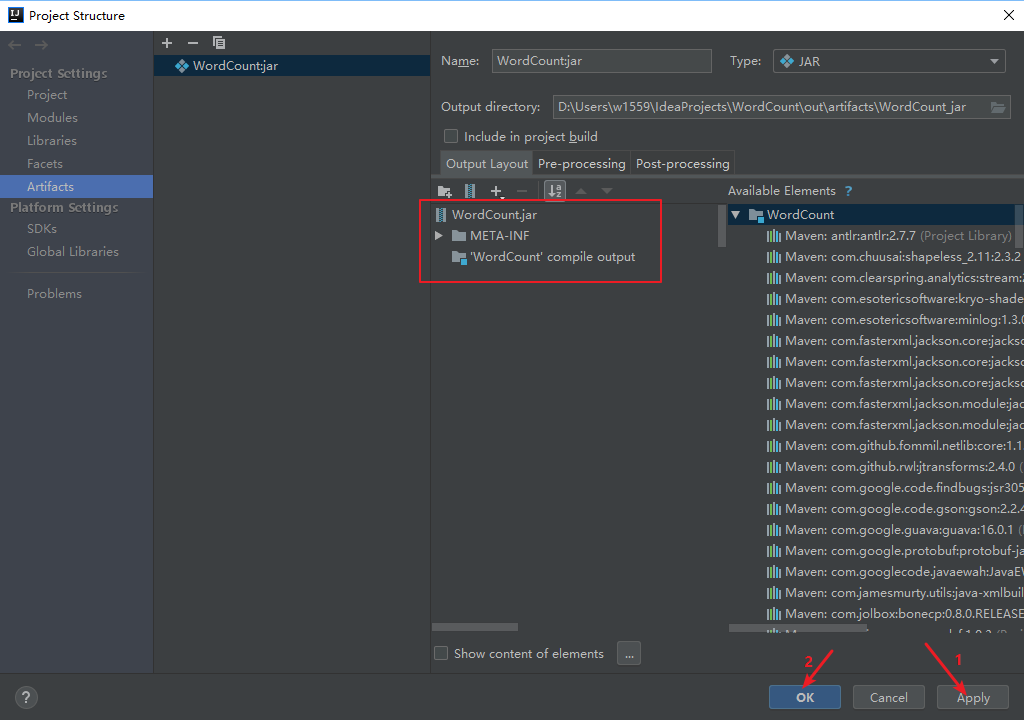
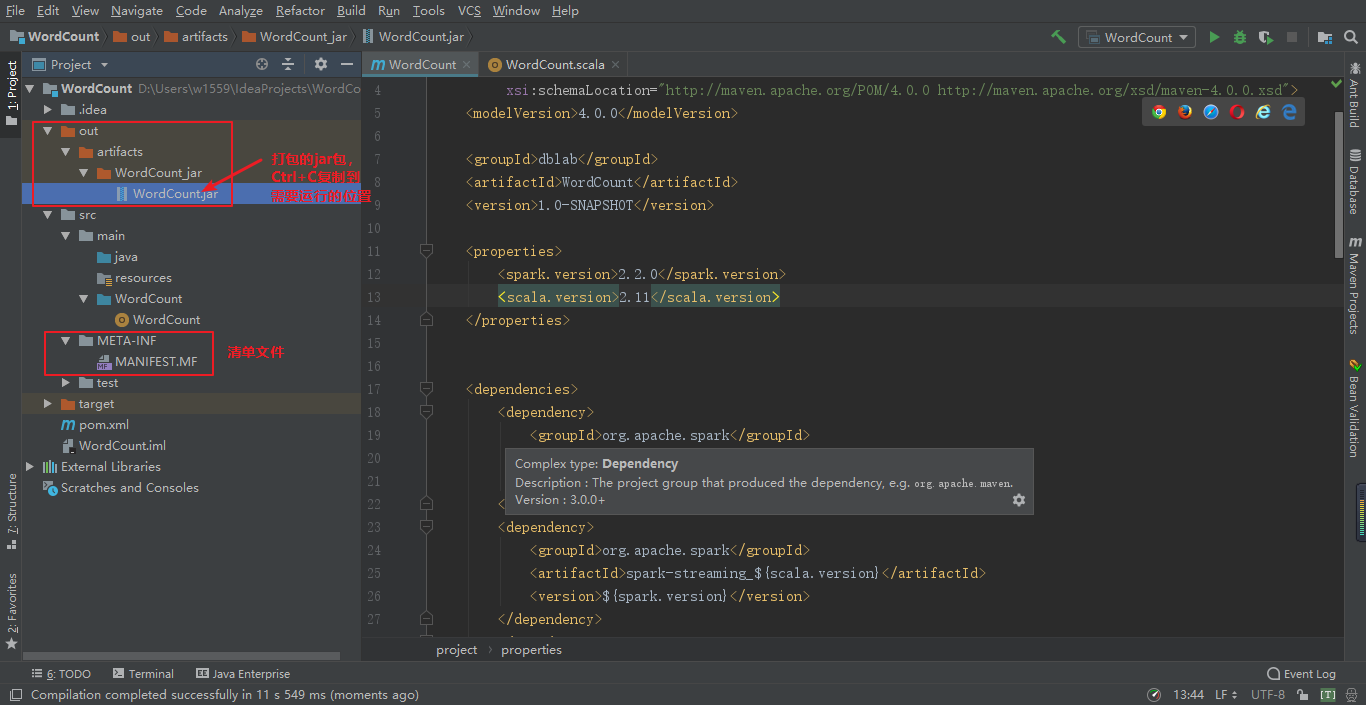
以本地文件运行
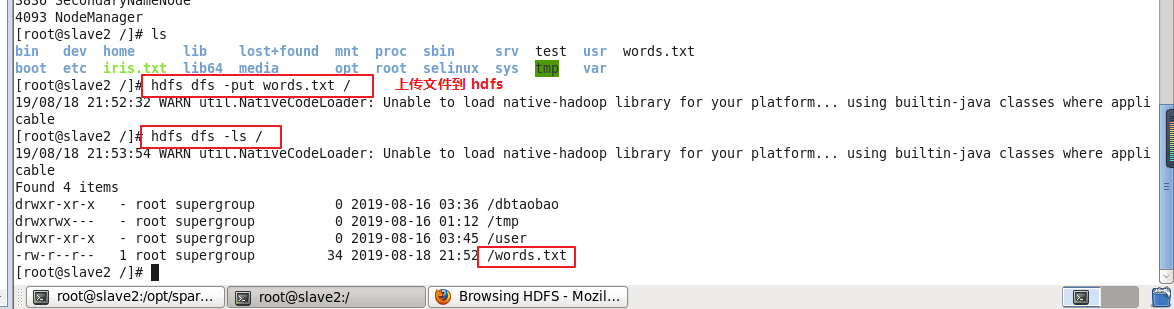
上传数据文件words.txt文件到Linux的 / 目录

运行提交运行spark程序
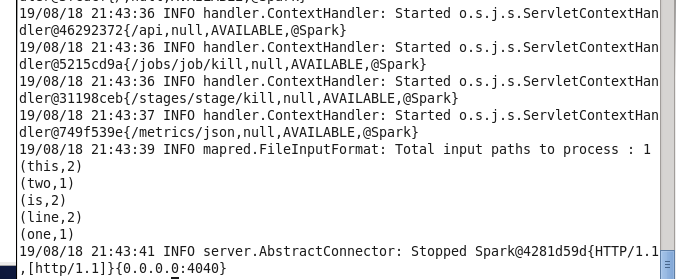
以local模式运行
/opt/spark/spark2.2/bin/spark-submit --class WordCount /mnt/hgfs/环境搭建/onf/WordCount.jar
以伪分布式方式读取hdfs文件运行
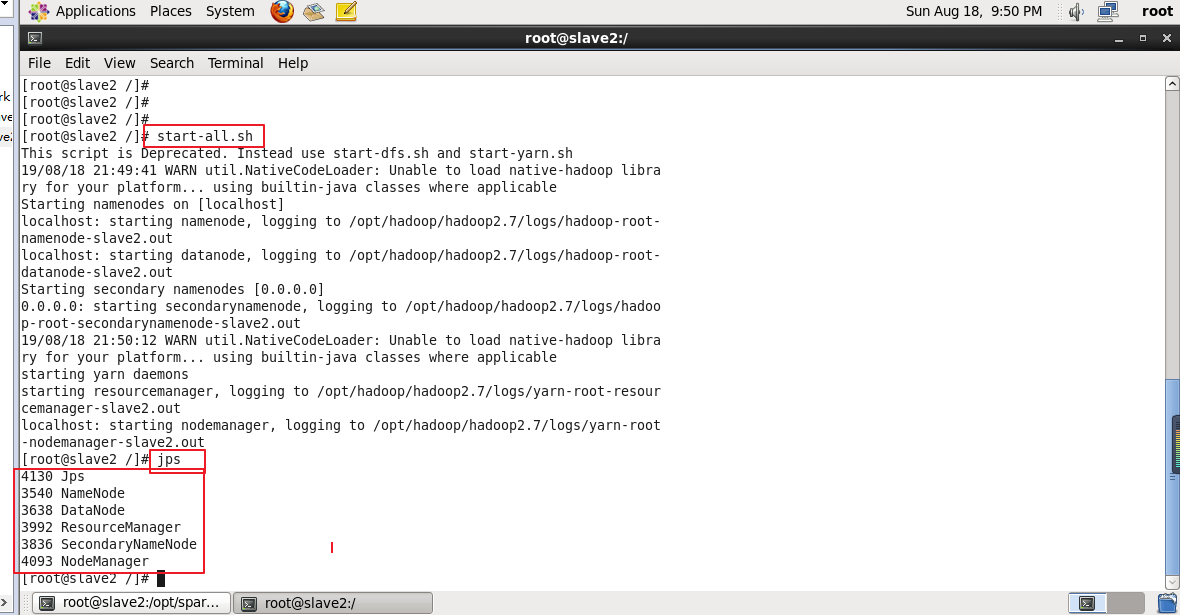
启动Hadoop
上传文件
启动spark
进入SPARK HOME
cd /opt/spark/spark2.2/
启动spark
./sbin/start-all.sh
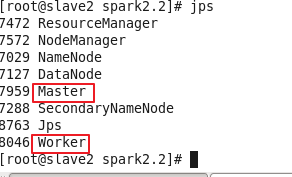
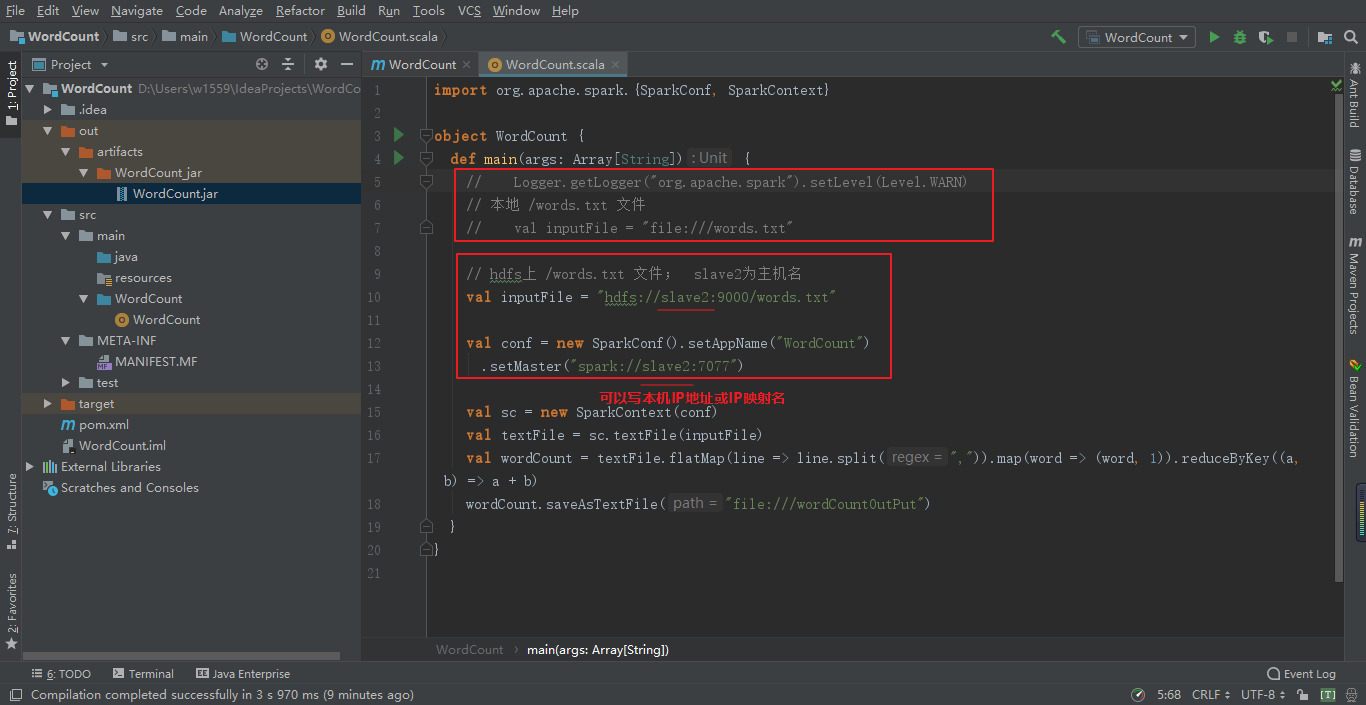
修改WordCount代码
重写打包代码
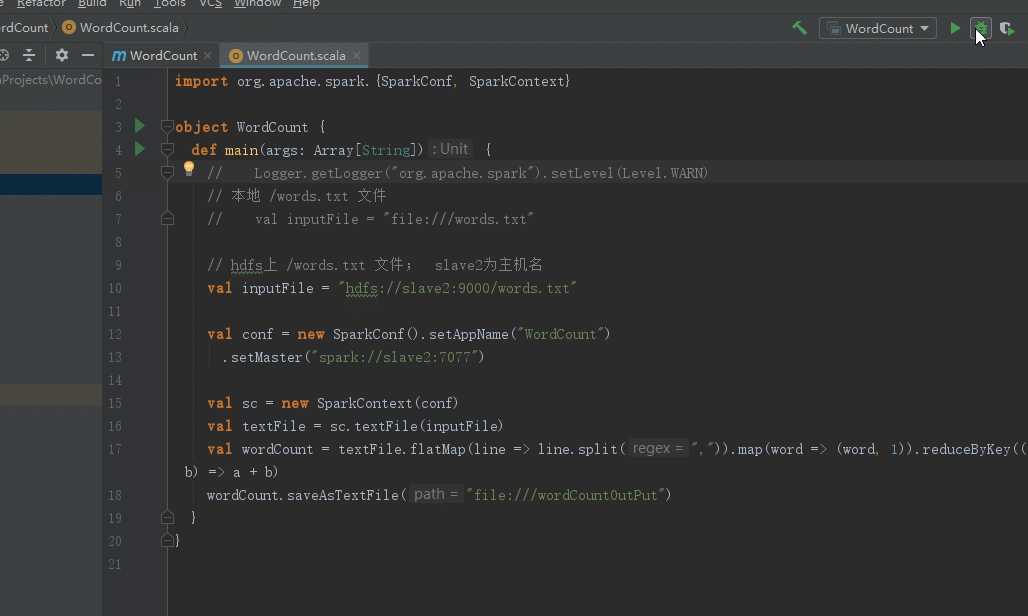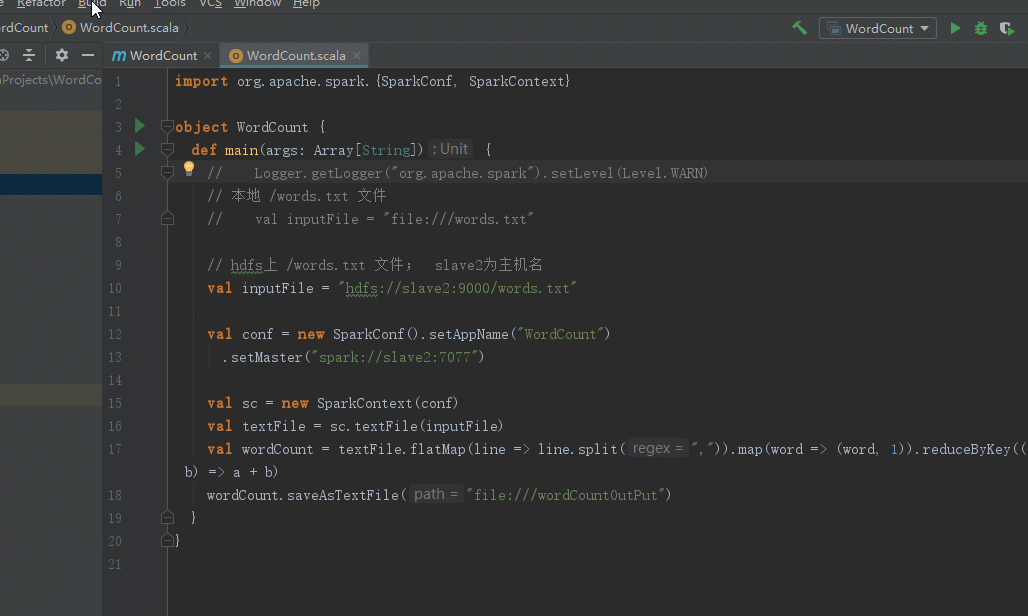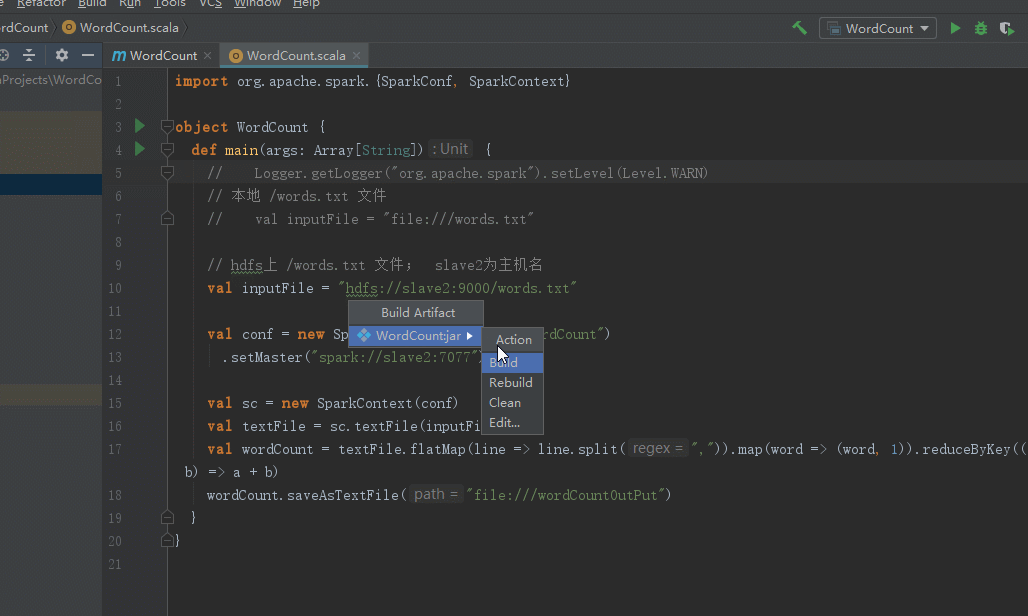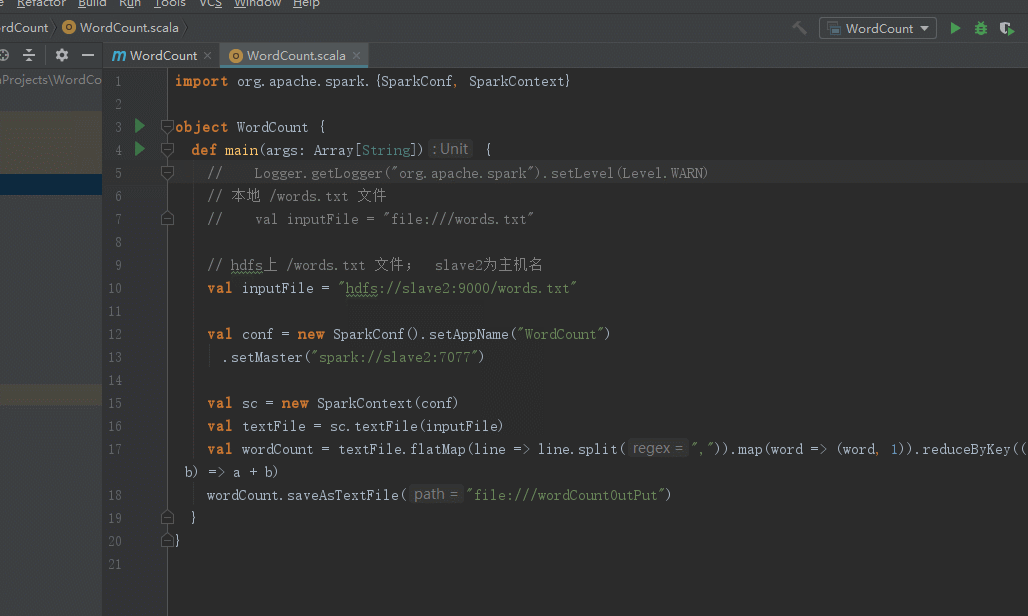
运行程序
/opt/spark/spark2.2/bin/spark-submit --master spark://slave2:7077 --class WordCount /mnt/hgfs/环境搭建/conf/WordCount.jar
查看结果
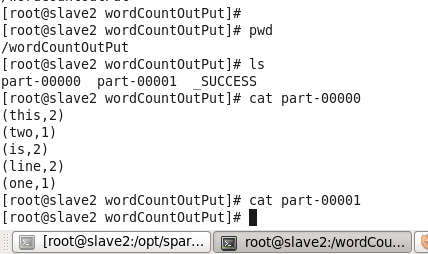
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号