解压和重命名文件
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
mkdir /opt/spark
mv spark-2.2.0-bin-hadoop2.7 /opt/spark/spark2.2
进入配置文件目录
cd /opt/spark/spark2.2/conf/
cp spark-env.sh.template spark-env.sh
编辑 spark-env.sh 在第二行空白处添加信息
vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop2.7/bin/hadoop classpath)

配置环境变量
vim /etc/profile
# Spark Config
export SPARK_HOME=/opt/spark/spark2.2
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:${SQOOP_HOME}/bin:${FLUME_HOME}/bin:${STORM_HOME}/bin:$PATH
复制MySQL驱动到spark的jars包里面
cp mysql-connector-java-5.1.41.jar /opt/spark/spark2.2/jars/
启动Hadoop
start-all.sh
运行spark自带的example
/opt/spark/spark2.2/bin/run-example SparkPi 2>&1 | grep "Pi is"

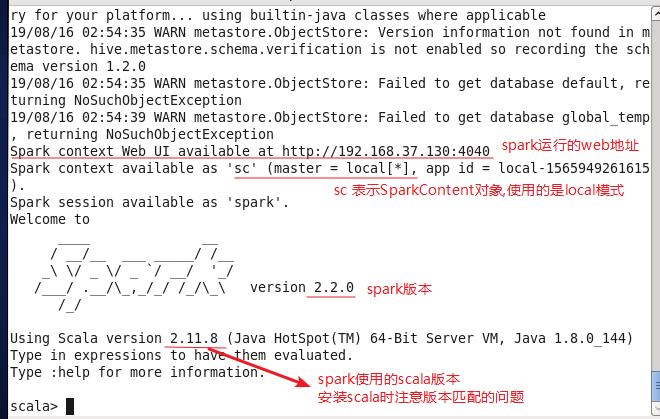
运行spark-shell
/opt/spark/spark2.2/bin/spark-shell


 浙公网安备 33010602011771号
浙公网安备 33010602011771号