
Spark-RDD
头代码
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
//屏蔽日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 配置spark配置对象
val conf = new SparkConf()
.setAppName("rdd Test")
.setMaster("local[*]") // 以本地模式运行spark, 提交到spark集群需要注释掉本行代码
// 创建操作spark的SparkContent对象
val sc = new SparkContext(conf)
RDD创建
// parallelize 将集合转换成RDD类型
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
// hdfs上的 /words.txt
val rdd = sc.textFile("hdfs://master:9000/words.txt")
val rdd = sc.textFile("/words.txt")
// 本地的 D:\\words.txt
val rdd = sc.textFile("file:///D:\\words.txt")
val rdd = sc.textFile("D:\\words.txt")
// 以行的方式遍历rdd的数据
rdd.foreach(println)
保存RDD数据
//保存数据到hdfs上
sc.parallelize(1 to 10).saveAsTextFile("hdfs://master:9000/sparkFile.txt")
// 保存到本地的 D:/sparkFile.txt
sc.parallelize(1 to 10).saveAsTextFile("file:///D:/sparkFile.txt")
sc.parallelize(1 to 10).saveAsTextFile("D:/sparkFile.txt")
RDD数据类型转换
val rdd = sc.parallelize(List((1, "a"), (1, "b"), (2, "c"), (2, "d")))
//将rdd转换为Map
println(rdd.collectAsMap())
Map(2 -> d, 1 -> b)
val rdd4 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
//根据value 来生成key
println(rdd4.keyBy(x => x.length).collect.foreach(print))
(3,dog)(4,wolf)(3,cat)(4,bear)
RDD逻辑操作方法
val rdd1 = sc.parallelize(Array(1, 2, 3, 4, 5))
val rdd2 = sc.parallelize(Array(3, 4, 5, 6, 7))
//并集
println(rdd1.union(rdd2).collect.foreach(print))
//交集
println(rdd1.intersection(rdd2).collect.foreach(print))
//差集
println(rdd1.subtract(rdd2).collect.foreach(print))
1234534567
435
12
去重
//去除里面的重复数据(无序)
sc.parallelize(List(1, 1, 2, 2, 3, 3)).distinct.foreach(println)
sc.parallelize(List("aa bb", "cc dd", "aa bb", "cc dd")).distinct().foreach(println)
1
3
2
cc dd
aa bb
分组
//输入数据为(K, V) 对, 返回的是 (K, Iterable); 通过key对数据分组
sc.parallelize(List("a", "a", "b", "c", "c", "d", "e", "f"))
.map((_, 1)) // 将每一个数据转化为 (data,1)的tuple
.groupByKey() // 对数据进行分组
.foreach(println) // 遍历输出
RDD合并的:
// 合并合并两个RDD后分组
rdd1.cogroup(rdd2)
rdd1.groupWith(rdd2)
(d,CompactBuffer(1))
(e,CompactBuffer(1))
(a,CompactBuffer(1, 1))
(b,CompactBuffer(1))
(f,CompactBuffer(1))
(c,CompactBuffer(1, 1))
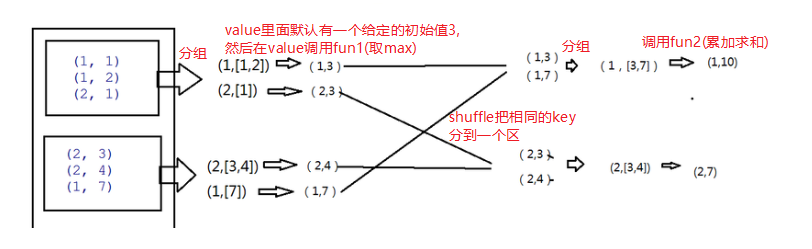
//aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中使用了一个中立的初始值
def fun1(a: Int, b: Int): Int = {
// 打印过程中 a b 的值
println("fun1: " + a + " " + b)
max(a, b)
}
def fun2(a: Int, b: Int): Int = {
// 打印过程中 a b 的值
println("fun2: " + a + " " + b)
a + b
}
sc.parallelize(List((1, 1), (1, 2), (2, 1), (2, 3), (2, 4), (1, 7)), 2)
.aggregateByKey(3)(fun1, fun2)
.foreach(print)
fun1: 3 1
fun1: 3 2
fun1: 3 1
fun1: 3 3
fun1: 3 4
fun1: 3 7
fun2: 3 4
(2,7)
fun2: 3 7
(1,10)
累积运算(reduce)
val wordMap = sc.parallelize(List("a", "a", "b", "c", "c", "d", "e", "f")).map((_, 1))
// 遍历map后的数据
println(wordMap.foreach(print))
//数据经过key分组后对value迭代对象应用函数
wordMap.reduceByKey(_ + _).foreach(println)
(a,1)(a,1)(b,1)(c,1)(c,1)(d,1)(e,1)(f,1)
(d,1)
(e,1)
(a,2)
(b,1)
(f,1)
(c,2)
//累加求和 (((1+2)+3)+4)+...
println(sc.parallelize(1 to 10).reduce(_+_))
55
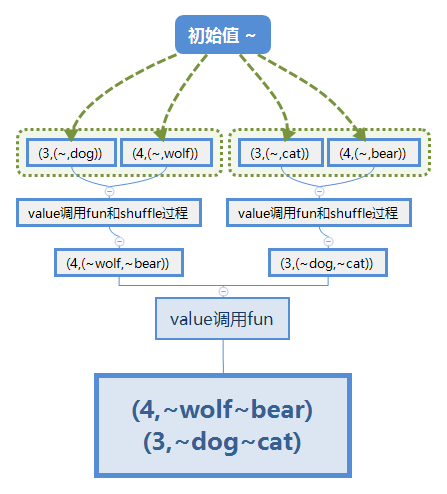
val rdd3 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
//foldByKey先对每一个元素添加一个初始值调用fun, 结果再经过类似于reduceByKey调用fun得到分组计算的结果
rdd3.map(x => (x.length, x))
.foldByKey("~")((x,y) => {println("fun",x,y); x + y})
.collect
.foreach(println)
(fun,~,dog)
(fun,~,wolf)
(fun,~,cat)
(fun,~,bear)
(fun,~wolf,~bear)
(fun,~dog,~cat)
(4,~wolf~bear)
(3,~dog~cat)
筛选RDD元素
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("c", 3), ("a", 4), ("b", 5), ("d", 6)))
//筛选在 ["a","b"] 之间的key
println(rdd1.filterByRange("a", "b").collect.foreach(print))
(a,1)(b,2)(a,4)(b,5)
拆分RDD的Map
val rdd2 = sc.parallelize(List(("fruit", "apple,banana,pear"), ("animal", "pig,cat,dog,tiger")))
// 通过key和拆分后的value组合,生成多个新的元组
rdd2.flatMapValues(_.split(",")).collect.foreach(println)
(fruit,apple)
(fruit,banana)
(fruit,pear)
(animal,pig)
(animal,cat)
(animal,dog)
(animal,tiger)
统计个数
// 统计元素个数
println(sc.parallelize(1 to 10).count())
// 统计相同key的个数
sc.parallelize(List((1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3)))
.countByKey()
.foreach(print)
10
(1,3)(2,3)
选取元素
//取第一个
println(sc.parallelize(1 to 10).first())
//取前3个
println(sc.parallelize(1 to 10).take(3).foreach(print))
//随机取n个数据; 不可重复取,大于总数的话只取总数的数量
println(sc.parallelize(1 to 5).takeSample(false, 7).foreach(print))
//随机取n个数据; 可重复取,大于总数的话只取总数的数量
println(sc.parallelize(1 to 5).takeSample(true, 7).foreach(print))
//随机取n个并且排好序, 不可重复选取
println(sc.parallelize(1 to 10).takeOrdered(12).foreach(print))
1
123
42153
2233554
12345678910
排序
sc.parallelize(List(1, 2, 5, 7, 3, 0)).map((_, "v"))
.sortByKey(false) //对key进行排序, true升序 false降序
.foreach(print)
sc.parallelize(List(1, 2, 5, 7, 3, 0)).map(( "v",_))
.sortBy(_._2,false) //对value进行排序
.foreach(print)
(7,v)(5,v)(3,v)(2,v)(1,v)(0,v)
(v,7)(v,5)(v,3)(v,2)(v,1)(v,0)
RDD合并
// 将两个rdd的key相同的合并value为其全部值的tuple
val rdd1 = sc.parallelize(List("a"-> 1,"b" -> 2,"c" -> 3))
// tuple里面只有两个元素的可以和Map合并
val rdd2 = sc.parallelize(List(("a", (4,1)), ("b", 5), ("c", 6), ("d", 7)))
// 合并 rdd1,rdd2; valuer以rdd1的第1个元素排序
rdd1.join(rdd2).foreach(println)
//以rdd1为主来合并rdd2; valuer以rdd1为主的第1个元素排序
rdd1.leftOuterJoin(rdd2).foreach(println)
//以rdd2为主来合并rdd1; valuer以rdd2为主的第1个元素排序
rdd1.rightOuterJoin(rdd2).foreach(println)
(a,(1,(4,1)))
(b,(2,5))
(c,(3,6))
(a,(1,Some((4,1))))
(b,(2,Some(5)))
(c,(3,Some(6)))
(d,(None,7))
(a,(Some(1),(4,1)))
(b,(Some(2),5))
(c,(Some(3),6))
// 合并后进行分组
rdd1.cogroup(rdd2).foreach(println)
// 等同于cogroup
rdd1.groupWith(rdd2).foreach(println)
val rdd3 = sc.parallelize(Array(1, 2, 3))
val rdd4 = sc.parallelize(Array((4,5), (6,7)))
//求两个RDD数据集间的笛卡尔积,两个RDD的数据分别组合
rdd3.cartesian(rdd4).foreach(print)
(d,(CompactBuffer(),CompactBuffer(7)))
(a,(CompactBuffer(1),CompactBuffer((4,1))))
(b,(CompactBuffer(2),CompactBuffer(5)))
(c,(CompactBuffer(3),CompactBuffer(0)))
(d,(CompactBuffer(),CompactBuffer(7)))
(a,(CompactBuffer(1),CompactBuffer((4,1))))
(b,(CompactBuffer(2),CompactBuffer(5)))
(c,(CompactBuffer(3),CompactBuffer(0)))
(1,(4,5))(1,(6,7))(2,(4,5))(2,(6,7))(3,(4,5))(3,(6,7))
RDD分区
// 注意: 有分区操作不能屏蔽日志不然看不到效果; 分区数决定保存文件时生成的文件个数
//将开始的4个分区降为指定的3个分区
sc.parallelize(1 to 10,4) // 使用4个分区
.coalesce(3) // 修改为3个分区
.foreach(print)
//同coalesce 只不是shuffle = true,意味着可能会导致大量的网络开销。
sc.parallelize(1 to 10, 3)
.repartition(2)
.foreach(print)
//repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。
sc.parallelize(
List((2, 3), (1, 3), (1, 2), (5, 4), (1, 4), (2, 4)), 5)
.repartitionAndSortWithinPartitions(new HashPartitioner(4)
).foreach(print)
12 345 678910
134679 25810
(1,3)(1,2)(1,4)(5,4) (2,3)(2,4)
分区运算
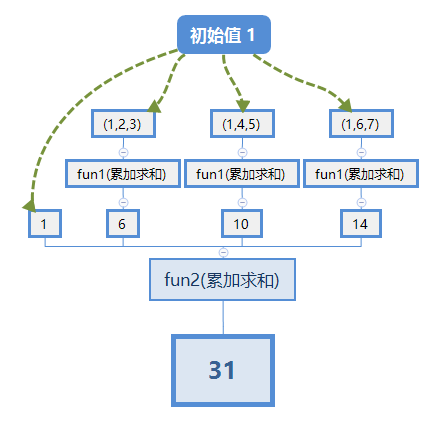
val rdd = sc.parallelize(Array( 2, 3, 4,5,6,7), 3)
// +0
println(rdd.aggregate(0)(_ + _, _ + _))
// 每一个分区里加一个元素 1 调用fun1 -> 各分区得到的结果和初始值调用fun2 -> 结果
println(rdd.aggregate(1)((x,y) => {println("fun1",x,y); x + y},(x,y) => {println("fun2",x,y); x + y}))
// 过程同上结果应大 (分区数+1) * 默认值
println(rdd.aggregate(1)(_ + _, _ + _))
27
(fun1,1,2)
(fun1,3,3)
(fun2,1,6)
(fun1,1,4)
(fun1,5,5)
(fun2,7,10)
(fun1,1,6)
(fun1,7,7)
(fun2,17,14)
31
31
val rdd2 = sc.parallelize(List(1, 2, 3, 4, 5), 3)
//对每一个分区进行操作
println(rdd2.mapPartitions(_.map(_ * 10)).collect.foreach(print))
10 20 30 40 50

 浙公网安备 33010602011771号
浙公网安备 33010602011771号