selenium+python的网站爬虫
爬取网站听起来就是程序员的标配,之前一直没有时间学一下,最近有空学习一下顺便记录一下
爬取网站实际上就是利用计算机模拟人的操作来对网站的前端进行访问,而各大浏览器也给计算机提供了访问的接口,也就是浏览器驱动,计算机通过编写好的库访问浏览器驱动,就可以直接访问网页,但与人去访问不同的事,没有图形化的界面给计算机去进行点击的操作,选中输入框,输入文字,点击提交,这一系列操作的前提都是得先选中输入框,因此先了解计算机如何选中输入框的,以及如何定位到位置
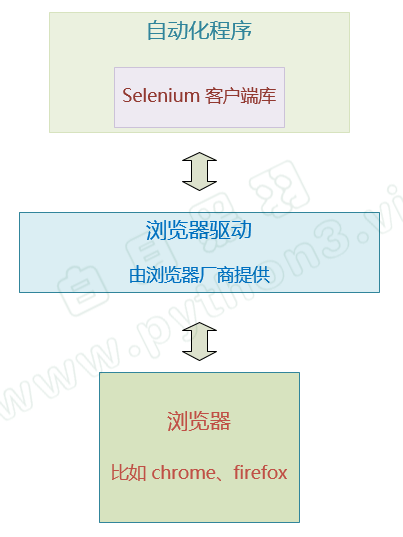
虽然呈现给用户的界面是图形化界面,但本质还是使用HTML、CSS和js来构建的,点击实际上也是触发了前端元素的事件,因此直接选择前端元素,和鼠标操作的目的是一样的
选择元素的两种方式:(1)使用元素的id、名称、类别进行直接选择,通过find_elements(By.ID,"ID")执行操作,与之相同的还有find_elements(By.CLASS_NAME,"class"),find_elements(By.TAG_NAME,"tagname")
#导入selenium
from selenium import webdriver
#导入对对应浏览器驱动的包,这里我使用的是微软的edge,不同的浏览器,驱动不同
from selenium.webdriver.edge.service import Service
#导入选择
from selenium.webdriver.common.by import By
#通过webdriver加载对应浏览器的驱动,这样需要加载全限定名,r表示后面的字符串不使用\转义,另一种方法是将路径加入到环境变量中,可以省去这一步
wb=webwebdriver.Edge(service=Service(r"D:\softwore in compile\Edge-driver\msedgedriver.exe"))
#让浏览器驱动加载一个页面,这个页面实际上就是一个html,如果这个html里还嵌套了一个html是无法访问的
wb.get("https://www.baidu.com/")
#选择了一个元素,并将之赋值给element
element=wb.find_elements(By.ID,"kw")
#此时可以对element做操作,由于使用的是wb.find_elements,因此返回的是一个元素数组,
element[0].send_key("黑色")#此时向输入框输入了黑色两个字,但没有点击
element=wb.find_element(By.ID,"su")
element.click()#这里定位到了”百度一下“的元素,并执行了点击操作
(2)通过CSS选择器
类似于By.id方法,使用了By.CSS_SELECTOR,"参数”,不需要在前面规定参数到底是id还是Tag名称还是类,使用id作为参数时在以"#id"传参,使用类名时以 ”.类名“ 作为传参
在选择的元素内,依旧可以执行选择元素的操作,但是如果选择的元素是一个iframe或者是另一个html,就无法执行选择操作了,因为元素选择这个操作是使用加载了网页的webDriver来实现的,而最开始的webDriver加载的网页已经确定了,也就是已经绑定了一个html,这个时候要加载内部的iframe或者html,是属于另一个页面,需要执行wd.switch_to.frame(frame_reference)
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。也可以填写frame 所对应的 WebElement 对象。
比如这里,就可以填写 iframe元素的id ‘frame1’ 或者 name属性值 ‘innerFrame’

 浙公网安备 33010602011771号
浙公网安备 33010602011771号