
1 B*TREE索引
1.1 什么是B*TREE索引
B*TREE索引是oracle数据库中最常见的索引。可以根据索引键值快速定位到表里的某一行数据或者根据索引键范围定位多行数据。
1.2 B*TREE索引结构
B*TREE索引的构造类似于二叉树,最底层的块称作叶块,叶块由索引键以及rowid组成。叶块之上的块称为分支块,检索数据时就是通过分支块到达叶块的。
例如,我们想在索引中找到值42,就要从树顶开始,找到左分支的一个块(分支块)。 然后我们在这个分支块当中,发现需要继续去找范围为“42...50”的(叶)块,而这个叶块就会带领我们找到表中值为42的那一行或几行数据。
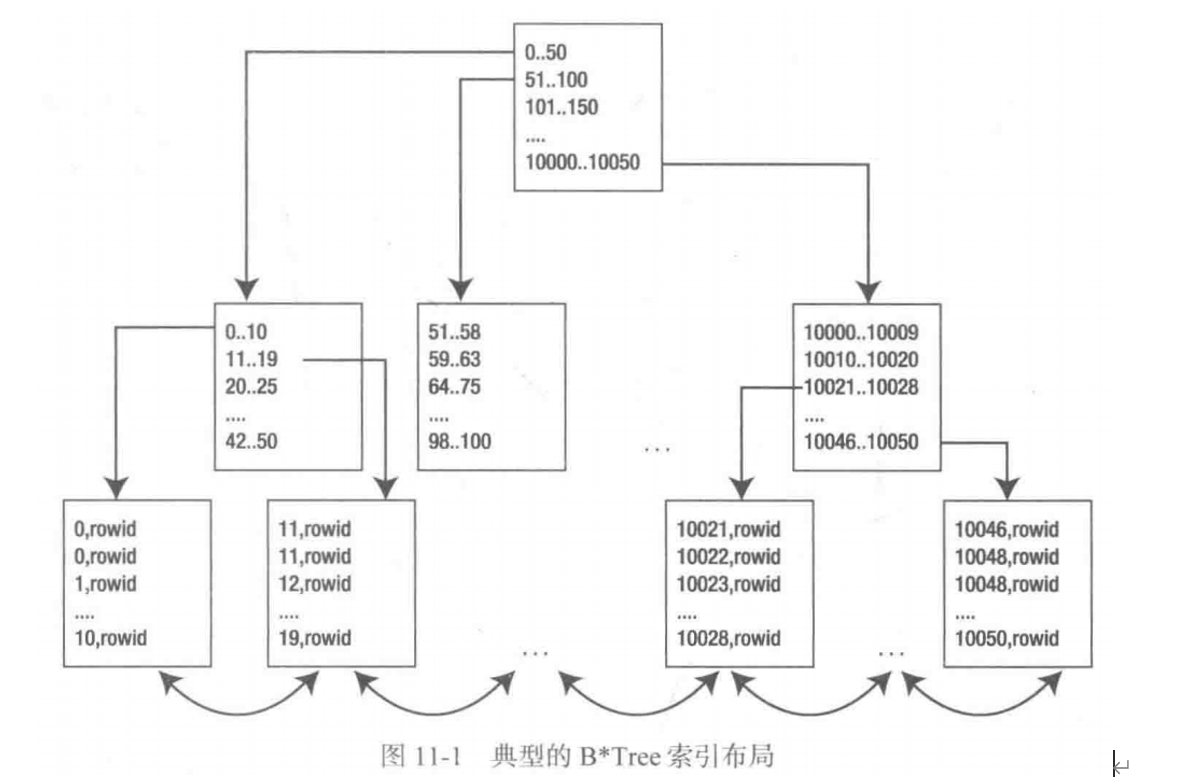
叶块这一层是一个双向链结构,这意味着范围搜索时,不需要从树根重新扫描,只需要向左或向右进行扫描。
1.3 B*TREE索引的唯一性和高度
BTREE索引的索引条目都是唯一的。如果索引键存储重复值,就会追加rowid到索引键后面,使索引条目唯一。在唯一性的索引中,数据库不会追加rowid到索引键上。
索引的高度是指从根块到叶块所需遍历的块。大多数BTREE索引的高度都是2或者3,即使几百万行的索引也是如此。这意味只需要2到3次I/O,我们就能找对应的叶块。
1.4 什么情况下应该使用B*TREE索引
- 访问表里一小部分数据,就用BTREE索引。这一小部分数据的行数占总表的行数不应该超过20%。例如访问一个学生表学号为1的数据,学生表有10万条数据。学号为1的这一条数据就占很小的比例。所以,我们应该在学号这个字段上建BTREE索引。
为什么不应该在访问占表大比例的数据上建B*TREE索引。例如表里有1000条数据以及100个块。如果我们要访问表里的200条数据,通过索引,我们就要扫描200次块。但是我们不使用索引,使用全表扫描的方式,才扫描100次块,比通过索引查找数据更高效。 - 要访问大量数据时,不需要访问表,可以直接通过索引就能得到时,就使用B*TREE索引。例如一个学生表的主键是学号(主键会自动建索引),我们需要统计学生表的学号的数量
select count(学号) from 学生表;
这时,数据库不会去扫描表里的数据统计数量,而是直接扫描学号的索引统计数据量。
2 位图索引
B*TREE索引的索引条目和表里的行是一对一的关系。但是位图索引一个索引条目会指向表里的多行数据。位图索引适合在表里高度重复的列建立。高度重复指相对于表里的总行数而言,索引字段只有少数几个不同的值。例如一个学生表,有10万数据,字段性别只有男女两个不同的值,性别字段就适合建位图索引。
位图索引适合建立在只读的数据中。在OLTP数据库中建立位图索引会导致以下并发问题。因为位图索引一个索引条目指向表里多行数据,如果修改索引列的数据,这个索引条目指向的多行数据会同时被锁定。
3 基于函数的索引
3.1 什么是基于函数的索引
我们可以使用基于函数的索引,对表里某些列的计算结果进行索引,这样查询时可以直接使用函数索引的结构。例如我们对学生表的学生名称建立了转换为大写的索引。
create index stu_upper_idx on student(upper(sname));
当我们查询select * from student where upper(sname)='JACK'时,数据库就无需将sname转换为大写,再对数据进行搜索,而是直接使用stu_upper_idx索引的数据进行搜索。再根据索引存储的ROWID找到对应的行数据。
3.2 只对部分行进行索引
对应B*TREE索引而言,对于索引列全为null的行是不会建立索引条目的。例如有如下索引
Create index I on t(a,b);
如果一行数据的a,b都是null,那索引I中就不会有这一行的索引条目。我们可以基于这个原理,对部分行进行索引。例如学生表有字段是否退学(is_dropout)。我们需要查询已退学的学生,我们就可以建如下索引
Create index id_drop on student(case when is_dropout='是' then '是' end);
那id_drop这个索引,只会建立is_dropout='是'的索引,不会建立is_dropout为其他值的索引。
3.3 实现有选择的唯一性
我们有这么一个需求,学生表中字段是否退学(is_dropout),如果为'否',则学生姓名(s_name)不允许重复。则我们可以建如下唯一性索引
Create unique index id_student_name On student ( case when is_dropout= '否' then s_name end );
4 索引常见的问题
4.1 可以在null建立索引吗?
BTREE索引不会存储索引键都是null的索引条目。而位图和聚簇索引则会存储。如果的确有'select * from t where name is null'这样查询某个字段为空的需求,而且null值的数量占表总数量很低,则可以使用索引键上追加一个常量,给索引键的null值建立bTREE索引。
CREATE INDEX id_name ON t (name, '1');
- 为什么重要字段不建议使用null
[1] B*TREE索引不存储索引键都是null值数据,影响查询效率。
[2] 不对null值处理后再参加聚合函数计算,容易造成聚合函数的统计产生错误的结果。
例如统计数据,要先加1再合计。写sum(length+1),有条数据时空,则统计结果会少1。因为null+1还是null。应该写成sum(nvl(length,0)+1)
[3] NOT IN后面的子查询中,如果子查询有null值,则会让查询查不出结果。
例如查询 where id not in(select id2 from student),如果id2有空值,则不会查出任何数据
4.2 为什么优化器没有使用建立的索引
- 索引建立在访问表里大部分数据的字段上。例如,'select * from student where sex='男''。男性别数量占表里数量一半左右。即使在sex建立索引,数据库优化器判断通过索引搜索数据的效率还不如全表扫描,数据库就会直接通过全表扫描搜索数据。
- 索引列存在空值,但是查询需要访问索引列为空的数据。类似于'SELECT COUNT(1) FROM T'的查询。因为索引键全为空的数据不会建B*TREE索引条目,使用索引统计会导致统计错误。所以数据库不会使用索引统计数据量,而是选择全表扫描。要让统计全表数据量使用索引,可以在建立not null约束的字段上建立索引。
- 表上的统计信息并不是最新的。所以可以尝试收集一下表上的统计信息,再次查询数据。
- 索引处于不可用状态。查询索引状态,如果是'UNUSABLE',则需要重建索引。

- 谓词没有使用索引的最左列。例如查询 'SELECT * FROM T where y=1'。但是是在T(X,Y)上建立的索引。那优化器就很可能不会用到索引,因为谓词中没有用到X列。
- 使用函数对索引列进行了转化。例如查询 'SELECT * FROM T where upper(y)='A''。即使在y列建立索引,也不会使用到索引。应该建立基于upper(y)函数的索引。
- 查询值类型和字段类型不一致。例如 'SELECT * FROM T where a=1'。a字段时varchar2类型,查询的值是数字。这样也使用不到索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号