
深信服面经总结
栈和队列的应用,
栈(stack)又名堆栈,它是一种运算受限的线性表,限定仅在表尾进行插入和删除操作的线性表
表尾这一端被称为栈顶,相反地另一端被称为栈底,向栈顶插入元素被称为进栈、入栈、压栈,从栈顶删除元素又称作出栈
所以其按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据,具有记忆作用
关于栈的简单实现,如下:
class Stack {
constructor() {
this.items = [];
}
/**
* 添加一个(或几个)新元素到栈顶
* @param {*} element 新元素
*/
push(element) {
this.items.push(element)
}
/**
* 移除栈顶的元素,同时返回被移除的元素
*/
pop() {
return this.items.pop()
}
/**
* 返回栈顶的元素,不对栈做任何修改(这个方法不会移除栈顶的元素,仅仅返回它)
*/
peek() {
return this.items[this.items.length - 1]
}
/**
* 如果栈里没有任何元素就返回true,否则返回false
*/
isEmpty() {
return this.items.length === 0
}
/**
* 移除栈里的所有元素
*/
clear() {
this.items = []
}
/**
* 返回栈里的元素个数。这个方法和数组的length属性很类似
*/
size() {
return this.items.length
}
}关于栈的操作主要的方法如下:
- push:入栈操作
- pop:出栈操作
队列
跟栈十分相似,队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作
进行插入操作的端称为队尾,进行删除操作的端称为队头,当队列中没有元素时,称为空队列
在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出
简单实现一个队列的方式,如下:
class Queue {
constructor() {
this.list = []
this.frontIndex = 0
this.tailIndex = 0
}
enqueue(item) {
this.list[this.tailIndex++] = item
}
unqueue() {
const item = this.list[this.frontIndex]
this.frontIndex++
return item
}
}上述这种入队和出队操作中,头尾指针只增加不减小,致使被删元素的空间永远无法重新利用
当队列中实际的元素个数远远小于向量空间的规模时,也可能由于尾指针已超越向量空间的上界而不能做入队操作,出该现象称为"假溢"
在实际使用队列时,为了使队列空间能重复使用,往往对队列的使用方法稍加改进:
无论插入或删除,一旦rear指针增1或front指针增1 时超出了所分配的队列空间,就让它指向这片连续空间的起始位置,这种队列也就是循环队列
下面实现一个循环队列,如下:
class Queue {
constructor(size) {
this.size = size; // 长度需要限制, 来达到空间的利用, 代表空间的长度
this.list = [];
this.font = 0; // 指向首元素
this.rear = 0; // 指向准备插入元素的位置
}
enQueue() {
if (this.isFull() == true) {
return false
}
this.rear = this.rear % this.k;
this._data[this.rear++] = value;
return true
}
deQueue() {
if(this.isEmpty()){
return false;
}
this.font++;
this.font = this.font % this.k;
return true;
}
isEmpty() {
return this.font == this.rear - 1;
}
isFull() {
return this.rear % this.k == this.font;
}
}
上述通过求余的形式代表首尾指针增1 时超出了所分配的队列空间
应用场景
栈
借助栈的先进后出的特性,可以简单实现一个逆序数处的功能,首先把所有元素依次入栈,然后把所有元素出栈并输出
包括编译器的在对输入的语法进行分析的时候,例如"()"、"{}"、"[]"这些成对出现的符号,借助栈的特性,凡是遇到括号的前半部分,即把这个元素入栈,凡是遇到括号的后半部分就比对栈顶元素是否该元素相匹配,如果匹配,则前半部分出栈,否则就是匹配出错
包括函数调用和递归的时候,每调用一个函数,底层都会进行入栈操作,出栈则返回函数的返回值
生活中的例子,可以把乒乓球盒比喻成一个堆栈,球一个一个放进去(入栈),最先放进去的要等其后面的全部拿出来后才能出来(出栈),这种就是典型的先进后出模型
队列
当我们需要按照一定的顺序来处理数据,而该数据的数据量在不断地变化的时候,则需要队列来帮助解题
队列的使用广泛应用在广度优先搜索种,例如层次遍历一个二叉树的节点值(后续将到)
生活中的例子,排队买票,排在队头的永远先处理,后面的必须等到前面的全部处理完毕再进行处理,这也是典型的先进先出模型
链表和数组的区别,
1、存储方式不同
数组是连续存储,数组在创建时需要一个整块的空间。
链表是链式存储,链表在内存空间中不一定是连续的。
数组一般创建在栈区,链表一般创建在堆区,在增加节点时需要new或malloc新节点,相较于数组长度不固定,自由度高。
2、访问元素方式不同
数组可以通过下标随机访问,单向链表只能通过头结点从前向后访问链表中的元素。
3、增删效率不同
数组在插入或删除的时候需要移动链表中的其他元素,时间复杂的为O(n)。
链表在进行插入删除时,找到要插入或删除的位置后,增删时间复杂度为O(1)。
所以当线性表进行大量的插入和删除操作时建议使用链表,若主要对线性表进行查找操作,较少进行插入操作是建议使用数组。
最大堆和最小堆,
最大堆
所谓最大堆,就是数组中最大的元素位于树的根节点位置,父节点大于子节点,但是,左右子节点大小与左子树还是右子树无关
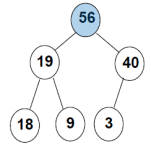
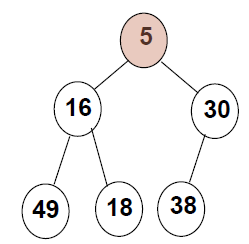
最小堆
所谓最小堆,就是数组中最小的元素在树的根节点,跟最大堆相反
反转链表的函数
https://zhuanlan.zhihu.com/p/499779834?utm_id=0
![]() 手撕String类
手撕String类
 手撕String类
手撕String类https://blog.csdn.net/shi_xiao_xuan/article/details/105586709
创建一个String类,class myString{
public:
成员函数:
构造函数:myString(const char *str = 0);
拷贝构造函数(深拷贝) myString(const mySting& str);
拷贝赋值函数(重载=) myString& operator=(const myString& str);
重载+ myString operator+(const myString & str) const;
重载+= myString operator+=(const myString& str);
重载== bool operator==(const myString& str) const;
重载[] char& operator[](int index);
非成员函数:
输入 friend istream& operator >> (istream &is, myString &str);
输出 friend ostream& operator<<(ostream &os,const myString &str);
析构函数 ~myString();
private:
char *m_data;
};
题目:实现一个队列
队列的应用场景为:一个生产者线程将int类型的数入列,一个消费者线程将int类型的数出列。
#include<iostream> #include<pthread.h> using namespace std; template <typename T, int SIZE=1024> class CircularQueue { public: T queue[SIZE]; int begin, end; CircularQueue():begin(0),end(0) { } ~CircularQueue(){} bool empty() { return begin == end; } bool full() { return (end + 1)%SIZE == begin; } void waitFull() { int st = 1; while (full()) { usleep(st); st = min(1000, st*2); } } void waitEmpty() { int st = 1; while (empty()) { usleep(st); st = min(1000, st*2); } } void push(const T& t) { waitFull(); queue[end] = t; end = (end + 1)%SIZE; } bool pop(T& t) { //waitEmpty(); if(empty()) return false; t = queue[begin]; begin = (begin + 1)%SIZE; return true; } /* T pop() { T t; return pop(t); } */ }; template <typename T, int SIZE = 1024> class LockedQueue { CircularQueue<T, SIZE+1> cq; pthread_mutex_t mutex; public: LockedQueue() { cq.begin = 0; cq.end = 0; pthread_mutex_init(&mutex, NULL); } ~LockedQueue() { pthread_mutex_destroy(&mutex); } void push(const T& t) { pthread_mutex_lock(&mutex); cq.push(t); pthread_mutex_unlock(&mutex); } bool pop(T& t) { pthread_mutex_lock(&mutex); bool bp = cq.pop(t); pthread_mutex_unlock(&mutex); if(!bp) return false; return true; } /* T pop() { T t; pop(t); return t; }*/ }; void *product_function(void *arg) { LockedQueue<int, 1024>* flq = (LockedQueue<int, 1024>*)arg; int i = 0; while(i < 10) { i ++; flq->push(i); cout << "product: " << i << endl; sleep(1); } } void *consume_function(void *arg) { LockedQueue<int, 1024>* flq = (LockedQueue<int, 1024>*)arg; while(1) { int a = 0; sleep(2); if(flq->pop(a)) cout << "consume: " << a << endl; else cout << "queue empty!" << endl; if(a >= 10) break; } } int main() { //test productor, consumor pthread_t thread1, thread2; LockedQueue<int, 1024> lq; pthread_create(&thread1, NULL, product_function, &lq); pthread_create(&thread2, NULL, consume_function, &lq); pthread_join(thread1, NULL); pthread_join(thread2, NULL); return 0; }
介绍项目的应用场景
和工业界应用的区别
学过什么数据结构和算法,刷过多少力扣题。
实现 strcpy。看我写的慢给我打断了,问我是不是没写过。答曰是,把思路给它讲了下,并说明拷贝时可能出现的覆盖问题。
平时编程写的多吗?出了道题目。Vim 上实现单词反转 "This is a girl"->"girl a is This",要求不能用 C++的一些接口,比 如 pop、push等,最好用纯 C 写,限时10分钟。what? 用 C++ vector 和 string 写了个 10 行左右的逻辑判断, 以为他说 的 pop、push 禁用是指不能用栈数据结构。实际他想让我写的是原地反转吧(也就是先整体反转,再逐单词反转)。
指针和引用的区别
tcp3次握手过程
怎么处理内存泄漏
原文件到可执行文件的过程
了不了解数据库(不了解)
事务相关(不了解)
求最长不重复子串的长度
深拷贝,浅拷贝区别
写一个深拷贝的例子
进程间通信方式
介绍重载重写
讲讲vector的增删操作和扩容
迭代器为什么可以遍历任何类型的数据
手撕:一串数字中找到最长的递增子序列
场景:100本书,A、B分别拿,一次可以拿1-5本,如何确保是A最后一个拿的
两个链表相交的判断方法 至少三种
暴力
简单的一个想法,对链表 A 中的每一个结点,我们都遍历一次链表 B 查找是否存在重复结点,第一个查找到的即第一个公共结点
class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { for (ListNode *p = headA; p != nullptr; p = p->next) { for (ListNode *q = headB; q != nullptr; q = q->next) { if (p == q) return p; } } return nullptr; } };
时间复杂度:O(n^2)
空间复杂度:O(1)
哈希表
对暴力解法的一个优化方案是:先将其中一个链表存到哈希表中,此时再遍历另外一个链表查找重复结点只需 &amp;amp;lt;span class="katex"&amp;amp;gt;&amp;amp;lt;span class="katex-mathml"&amp;amp;gt;O(1)
class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { unordered_set<ListNode *> s; for (ListNode *p = headA; p != nullptr; p = p->next) { s.emplace(p); } for (ListNode *p = headB; p != nullptr; p = p->next) { if (s.find(p) != s.end()) return p; } return nullptr; } };
时间复杂度:&amp;amp;lt;span class="katex"&amp;amp;gt;&amp;amp;lt;span class="katex-mathml"&amp;amp;gt;O(n)
空间复杂度:&amp;amp;lt;span class="katex"&amp;amp;gt;&amp;amp;lt;span class="katex-mathml"&amp;amp;gt;O(n)
栈
两个链表从公共结点开始后面都是一样的,若是我们顺着链表从后向前查找,很容易就能查找到链表的公共结点(第一个不相同的结点的下一个结点即所求)
那么如何从后向前查找呢?不难想到要使用栈
class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { stack<ListNode *> s1, s2; for (ListNode *p = headA; p != nullptr; p = p->next) { s1.push(p); } for (ListNode *p = headB; p != nullptr; p = p->next) { s2.push(p); } ListNode *ans = nullptr; for ( ; !s1.empty() && !s2.empty() && s1.top() == s2.top(); s1.pop(), s2.pop()) ans = s1.top(); return ans; } };
时间复杂度:O(n)
空间复杂度:O(n)
计算长度
前面的几个方法或是时间,或是空间,不满足题目要求的 O(n)O(n)O(n) 时间复杂度,且仅用 O(1)O(1)O(1) 内存
前面栈的解法中提到,从后向前很容易查找,那么能不能从前向后呢?若是两链表等长,那自然是可以的,指针同步后移,当遇到公共结点时两指针就会相遇,但若链表不等长那就不行了,两个指针可能会指向不同的公共结点,也就无法确定一个结点是否是公共结点。
由此,我们可以想到,能不能把两个链表变成等长的链表呢?显然若两链表不等长,那么长的链表的前 n 个结点(n 是长链表比短链表多的结点数)显然不可能是公共结点。而剩余部分两链表是等长的,自然就可以按照顺序同步后移的方法查找公共结点。
不过,为确定两链表长度差,得先遍历两链表确定长度
class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { int size1 = 1, size2 = 1; ListNode *p, *q; if (!headA || !headB)return NULL; /* 计算链表长度 */ for (p = headA; p->next != NULL; p = p->next, size1++); for (p = headB; p->next != NULL; p = p->next, size2++); /* 长链表先走,但不确定AB谁长,所以要写两个循环,但实际上有至少一个循环不会执行 */ p = headA; q = headB; for (int i = 0; i < size1 - size2; i++, p = p->next); for (int i = 0; i < size2 - size1; i++, q = q->next); for (; p && q && p != q; p = p->next, q = q->next); return p; } };
时间复杂度:O(n)
空间复杂度:O(1)
走过彼此的路
除了计算链表长度外,我们还可以利用 两链表长度和相等 的性质来使得两个遍历指针同步
具体做法是:先遍历其中一个链表,当到底末端后跳到另一链表,最后若两链表没有公共结点,那么两个链表指针都会走过 s1+s2个结点,同时到达两链表末尾
若有公共结点,由于最后会同时走到两链表终点,所以倒退回去,两个指针一定会在第一个公共结点处相遇
当然,若两链表等长,那确实不会跳到另一链表,不过链表等长本身指针就是同步的,同样也能找到公共结点
class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { ListNode *p, *q; for (p = headA, q = headB; p != q; ){ if (p != NULL) p = p->next; else p = headB; if (q != NULL) q = q->next; else q = headA; } return p; } };
时间复杂度:O(n)
空间复杂度:O(1)
手撕代码:链表反转;寻找字符串中出现次数最多的字符
读没读过Nginx的源码,你这个网络模型和别的有没有对比?
讲讲b+树和b树的区别
带头结点的单链表实现栈
做题: 合并两个有序链表
手撕扑克牌洗牌
判断一个链表是否有环
大数加法
边缘自治
进程间通信方式
写一个函数,每次返回不同的字符串。不会,后来查了下应该是用str_buffle,之前没遇到过。
现在有这两行代码 int a[2]={0,1};a[-1];
编译报不报错? 不报错的话,跑起来会怎么样,要不让它cash怎么做,或者说保证一定不出问题怎么做?
一个Int64的数,如何求取该数二进制中1的个数,不用移位行不行?有没有更快的办法?打表的话占用内存太多了,怎么优化?
回到一开始的问题,int*p=a;p+=8;p[-1];会怎么样?什么结果?
八股问了浏览器输入网址后发生了什么,由于计网不会,没答出来,然后问了http协议,也没有答出来😂,太tm菜了
最后手撕了两道题,一道是括号匹配问题,一道是验证ip地址是否正确。
问到进程如何访问内存,又没答出来,然后问JAVA虚拟机,我说虚拟机实现了跨平台,虚拟机里有解释器,各个平台都有实现不同的解释器,解释器将字节码文件转为机器码交给操作系统执行,然后问c,c++等语言能不能也一次编译,在各平台执行,我说不能,c在各个平台的代码层面就会有差异,编译后只能在当前平台使用,不知道答的对不对。
智力题:4L和6L杯子接3L水、25个人赛跑选出最快的三个人
智力题:种四棵树 要求任意两棵之间距离相等 没有任何限制条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号