spark 累加器
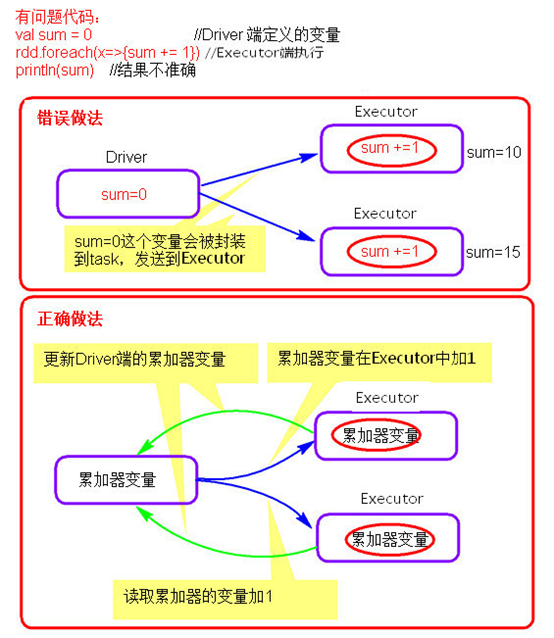
累加器原理图:
累加器创建:
sc.longaccumulator("") sc.longaccumulator
sc.collectionaccumulator() sc.collectionaccumulator
sc.doubleaccumulator() sc.doubleaccumulator
累加器累加:
l.add(1L)
累加器结果获取:
l.value
demo
long累加器
spark.sparkContext.setLogLevel("error")
val data=spark.sparkContext.parallelize(List(" "," "," "," "))
//var l=spark.sparkContext.longAccumulator
var l=spark.sparkContext.longAccumulator("test")
data.map(x=>{
l.add(3L)
x
}).count()
//count 函数仅仅用于触发执行
println(l.value)
data循环4次,每次加3,输出结果为12

Double累加器
collection累加器
重复累计问题:
val data=spark.sparkContext.parallelize(List(" "," "," "," ")) //var l=spark.sparkContext.longAccumulator var l=spark.sparkContext.longAccumulator("test") val res=data.map(x=>{ l.add(3L) x }) res.count() //count 函数仅仅用于触发执行 println(l.value) res.collect() println(l.value)

连续两次调用了action算子,所以这里累加器进行了两次重复的累加,也就是说,累加器实在遇到action算子的时候才进行累加操作的
正确写法在累加器结束后加入cache
spark.sparkContext.setLogLevel("error") val data=spark.sparkContext.parallelize(List(" "," "," "," ")) //var l=spark.sparkContext.longAccumulator var l=spark.sparkContext.longAccumulator("test") val res=data.map(x=>{ l.add(3L) x }).cache() res.count() //count 函数仅仅用于触发执行 println(l.value) res.collect() println(l.value)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号