
spark zip && zipPartitions && zipWithIndex && zipWithUniqueId
zip transformation算子,将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的每个分区元素个数必须相同。
spark.sparkContext.setLogLevel("error")
spark.sparkContext.setLogLevel("error") val kzc=spark.sparkContext.parallelize(1.to(10),2) val bd=spark.sparkContext.parallelize(List("a","b","c","d","e","f","g","h","i","j"),2) kzc.zip(bd).collect().foreach(println(_))
zipPartitions
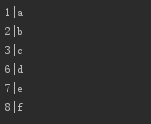
spark.sparkContext.setLogLevel("error") val kzc=spark.sparkContext.parallelize(1.to(10),2) val bd=spark.sparkContext.parallelize(List("a","b","c","d","e","f"),2) val res=kzc.zipPartitions(bd){ (iterator1,iterator2)=>{ val result=new scala.collection.mutable.ListBuffer[String]() while(iterator1.hasNext && iterator2.hasNext){ result.append(iterator1.next()+"|"+iterator2.next()) } result.iterator } } res.collect().foreach(println(_))
zipWithIndex 该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对。
spark.sparkContext.setLogLevel("error") val kzc=spark.sparkContext.parallelize(1.to(10),2) val bd=spark.sparkContext.parallelize(List("a","b","c","d","e","f"),2) bd.zipWithIndex().collect().foreach(println(_))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号