linkis重编译适配cdh
感谢各位webank大佬的指导!希望社区发展更快更好!
1、系统环境:
redhat7、cdh5.15.1、spark2.3.0、开启了sentry、没有开启kerberos
2、获取源码
在linkis的github上有一个linkis-cdh5.6的分支
https://github.com/WeBankFinTech/Linkis/release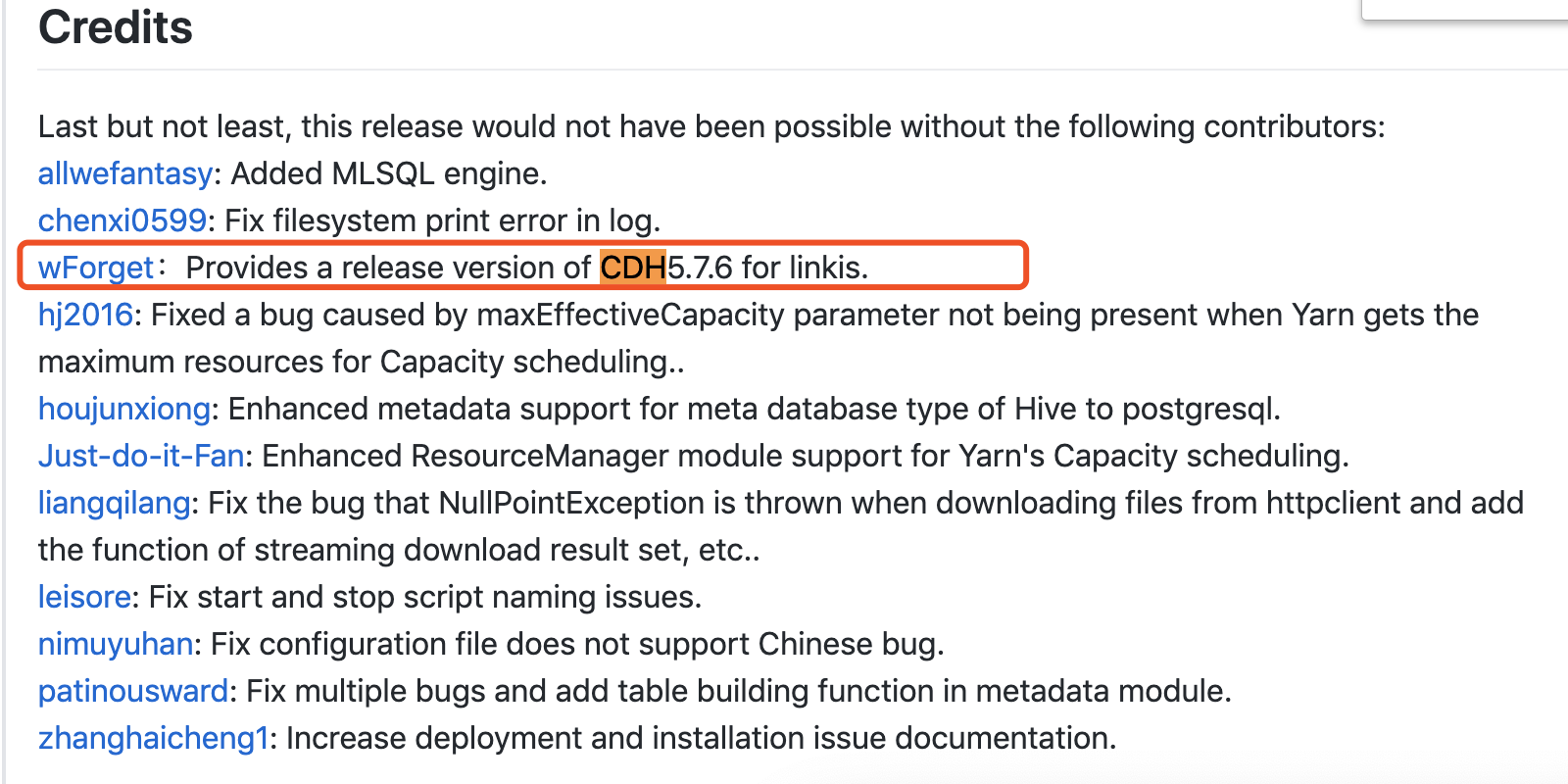
点击进入这位大佬wForget的github,https://github.com/wForget/Linkis,下载源码(怀疑这位大佬改过源码,所以为了方便,直接下载这位大佬的,我的是cdh5.15)
3、修改元数据板块(我的cdh集群采用了sentry做hive权限控制,源码采用的是hive自带的权限控制(只通过jdbc),不修改无法展示hive元数据)
3、主要修改读取元数据的部分(如果你用sentry控制hive权限,可以拷贝覆盖)


<?xml version="1.0" encoding="UTF-8" ?> <!-- ~ Copyright 2019 WeBank ~ ~ Licensed under the Apache License, Version 2.0 (the "License"); ~ you may not use this file except in compliance with the License. ~ You may obtain a copy of the License at ~ ~ http://www.apache.org/licenses/LICENSE-2.0 ~ ~ Unless required by applicable law or agreed to in writing, software ~ distributed under the License is distributed on an "AS IS" BASIS, ~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. ~ See the License for the specific language governing permissions and ~ limitations under the License. --> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="com.webank.wedatasphere.linkis.metadata.hive.dao.HiveMetaDao"> <select id="getLocationByDbAndTable" resultType="java.lang.String" parameterType="map"> select LOCATION from SDS where SD_ID in ( select SD_ID from `TBLS` where TBL_NAME = #{tableName,jdbcType=VARCHAR} and DB_ID in (select DB_ID from `DBS` where NAME = #{dbName,jdbcType=VARCHAR}) ) </select> <select id="getDbsByUser" resultType="java.lang.String" parameterType="java.lang.String"> <!--select NAME from( select t2.NAME as NAME from DB_PRIVS t1, DBS t2 where (lcase(t1.PRINCIPAL_NAME) = #{userName,jdbcType=VARCHAR} OR t1.PRINCIPAL_NAME IN (SELECT ROLE FROM(SELECT r.ROLE_NAME AS ROLE, u.PRINCIPAL_NAME AS USER FROM ROLES r LEFT JOIN (SELECT * FROM ROLE_MAP WHERE PRINCIPAL_TYPE = 'USER') u ON r.ROLE_ID = u.ROLE_ID)AS T where T.USER = #{userName,jdbcType=VARCHAR})) and lcase(t1.DB_PRIV) in ('select','all') and t1.DB_ID =t2.DB_ID union all select t3.NAME as NAME from TBL_PRIVS t1, TBLS t2 , DBS t3 where t1.TBL_ID=t2.TBL_ID and lcase(t1.TBL_PRIV) in ('select','all') and ( lcase(t1.PRINCIPAL_NAME) = #{userName,jdbcType=VARCHAR} or lcase(t1.PRINCIPAL_NAME) in (SELECT ROLE FROM(SELECT r.ROLE_NAME AS ROLE, u.PRINCIPAL_NAME AS USER FROM ROLES r LEFT JOIN (SELECT * FROM ROLE_MAP WHERE PRINCIPAL_TYPE = 'USER') u ON r.ROLE_ID = u.ROLE_ID)AS T where T.USER = #{userName,jdbcType=VARCHAR})) and t2.DB_ID=t3.DB_ID) a GROUP BY NAME order by NAME--> select name from DBS </select> <select id="getTablesByDbNameAndUser" resultType="map" parameterType="map"> <!--select t2.TBL_NAME as NAME, t2.TBL_TYPE as TYPE, t2.CREATE_TIME as CREATE_TIME, t2.LAST_ACCESS_TIME as LAST_ACCESS_TIME, t2.OWNER as OWNER from DB_PRIVS t1,TBLS t2, DBS t3 where t1.DB_ID =t3.DB_ID and t2.DB_ID=t3.DB_ID and lcase(t1.DB_PRIV) in ('select','all') and lcase(t1.PRINCIPAL_NAME) = #{userName,jdbcType=VARCHAR} and t3.NAME = #{dbName,jdbcType=VARCHAR} union select t2.TBL_NAME as NAME, t2.TBL_TYPE as TYPE, t2.CREATE_TIME as CREATE_TIME, t2.LAST_ACCESS_TIME as LAST_ACCESS_TIME, t2.OWNER as OWNER from DB_PRIVS t1,TBLS t2, DBS t3 where t1.DB_ID =t3.DB_ID and t2.DB_ID=t3.DB_ID and lcase(t1.DB_PRIV) in ('select','all') and lcase(t1.PRINCIPAL_NAME) in (select ROLE_NAME from ROLES where ROLE_ID in (select ROLE_ID from ROLE_MAP where PRINCIPAL_NAME = #{userName,jdbcType=VARCHAR})) and t3.NAME = #{dbName,jdbcType=VARCHAR} union select t2.TBL_NAME as NAME, t2.TBL_TYPE as TYPE, t2.CREATE_TIME as CREATE_TIME, t2.LAST_ACCESS_TIME as LAST_ACCESS_TIME, t2.OWNER as OWNER from TBL_PRIVS t1, TBLS t2 , DBS t3 where t1.TBL_ID=t2.TBL_ID and t2.DB_ID=t3.DB_ID and lcase(t1.TBL_PRIV) in ('select','all') and t1.PRINCIPAL_NAME = #{userName,jdbcType=VARCHAR} and t3.NAME = #{dbName,jdbcType=VARCHAR} union select t2.TBL_NAME as NAME, t2.TBL_TYPE as TYPE, t2.CREATE_TIME as CREATE_TIME, t2.LAST_ACCESS_TIME as LAST_ACCESS_TIME, t2.OWNER as OWNER from TBL_PRIVS t1, TBLS t2 , DBS t3 where t1.TBL_ID=t2.TBL_ID and t2.DB_ID=t3.DB_ID and lcase(t1.TBL_PRIV) in ('select','all') and t1.PRINCIPAL_NAME in (select ROLE_NAME from ROLES where ROLE_ID in (select ROLE_ID from ROLE_MAP where PRINCIPAL_NAME = #{userName,jdbcType=VARCHAR})) and t3.NAME = #{dbName,jdbcType=VARCHAR} order by NAME;--> select t2.TBL_NAME as NAME, t2.TBL_TYPE as TYPE, t2.CREATE_TIME as CREATE_TIME, t2.LAST_ACCESS_TIME as LAST_ACCESS_TIME, t2.OWNER as OWNER from TBLS t2 , DBS t3 where t2.DB_ID=t3.DB_ID and t3.NAME = #{dbName,jdbcType=VARCHAR} </select> <select id="getPartitionSize" resultType="java.lang.Long" parameterType="map"> select PARAM_VALUE from PARTITION_PARAMS where PARAM_KEY = 'totalSize' and PART_ID in ( select PART_ID from PARTITIONS where PART_NAME = #{partitionName,jdbcType=VARCHAR} and TBL_ID in( select TBL_ID from `TBLS` where TBL_NAME = #{tableName,jdbcType=VARCHAR} and DB_ID in (select DB_ID from `DBS` where NAME = #{dbName,jdbcType=VARCHAR}) ) ); </select> <select id="getPartitions" resultType="java.lang.String" parameterType="map"> select PART_NAME from PARTITIONS where TBL_ID in( select TBL_ID from `TBLS` where TBL_NAME = #{tableName,jdbcType=VARCHAR} and DB_ID in (select DB_ID from `DBS` where NAME = #{dbName,jdbcType=VARCHAR}) ); </select> <select id="getColumns" resultType="map" parameterType="map"> SELECT COMMENT, COLUMN_NAME, TYPE_NAME FROM COLUMNS_V2 where CD_ID in( select CD_ID from SDS where SD_ID in ( select SD_ID from `TBLS` where TBL_NAME = #{tableName,jdbcType=VARCHAR} and DB_ID in (select DB_ID from `DBS` where NAME = #{dbName,jdbcType=VARCHAR}) ) ) order by INTEGER_IDX asc; </select> <select id="getPartitionKeys" resultType="map" parameterType="map"> select PKEY_COMMENT, PKEY_NAME, PKEY_TYPE from PARTITION_KEYS where TBL_ID in( select TBL_ID from `TBLS` where TBL_NAME = #{tableName,jdbcType=VARCHAR} and DB_ID in (select DB_ID from `DBS` where NAME = #{dbName,jdbcType=VARCHAR}) ); </select> <select id="getTableComment" resultType="String"> SELECT tp.PARAM_VALUE FROM `DBS` d LEFT JOIN `TBLS` t ON d.DB_ID = t.DB_ID LEFT JOIN `TABLE_PARAMS` tp ON t.TBL_ID = tp.TBL_ID WHERE tp.PARAM_KEY = 'comment' AND d.`NAME` = #{DbName} AND t.TBL_NAME = #{tableName} </select> </mapper>
4、修改pom.xml
4.1修改版本部分(将hive和hadoop版本指向cdh5.15.1)

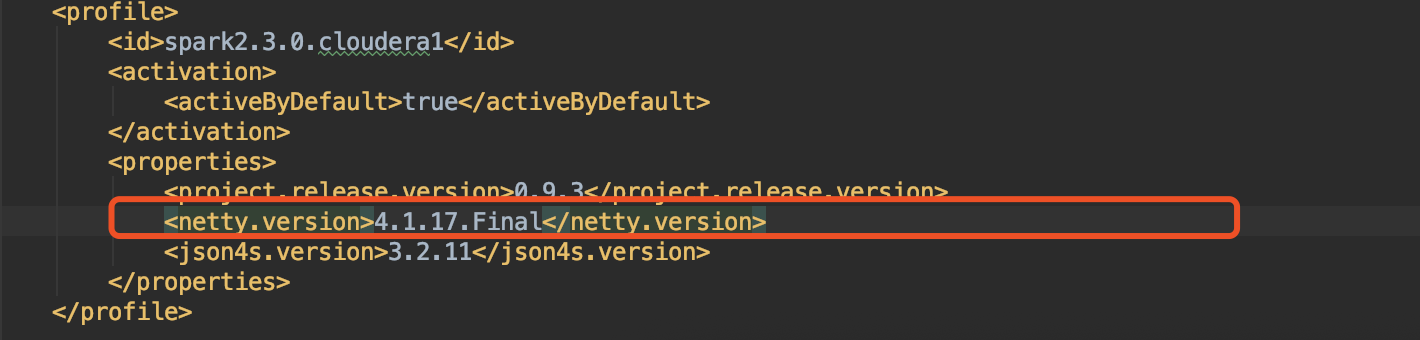
4.2修改netty版本(我的是spark2.3.0,如果不修改,会有兼容性问题,在执行spark引擎时报错)
5、配置多maven源,科 学 上网
首先保证编译主机可以访问外网,然后给maven配置多maven源,修改settings.xml里面<profiles></profiles>和<activeProfiles></activeProfiles>模块,添加cloudera官网提供的maven源
<profiles> <profile> <id>boundlessgeo</id> <repositories> <repository> <id>boundlessgeo</id> <url>https://repo.boundlessgeo.com/main/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> </snapshots> </repository> </repositories> </profile> <profile> <id>aliyun</id> <repositories> <repository> <id>aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> </snapshots> </repository> </repositories> </profile> <profile> <id>maven-central</id> <repositories> <repository> <id>maven-central</id> <url>http://central.maven.org/maven2/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> </snapshots> </repository> </repositories> </profile> <profile> <id>cloudera</id> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> </snapshots> </repository> </repositories> </profile> </profiles> <activeProfiles> <activeProfile>boundlessgeo</activeProfile> <activeProfile>aliyun</activeProfile> <activeProfile>maven-central</activeProfile> <activeProfile>cloudera</activeProfile> </activeProfiles>
6、编译,安装
mvn -clean install
mvn package
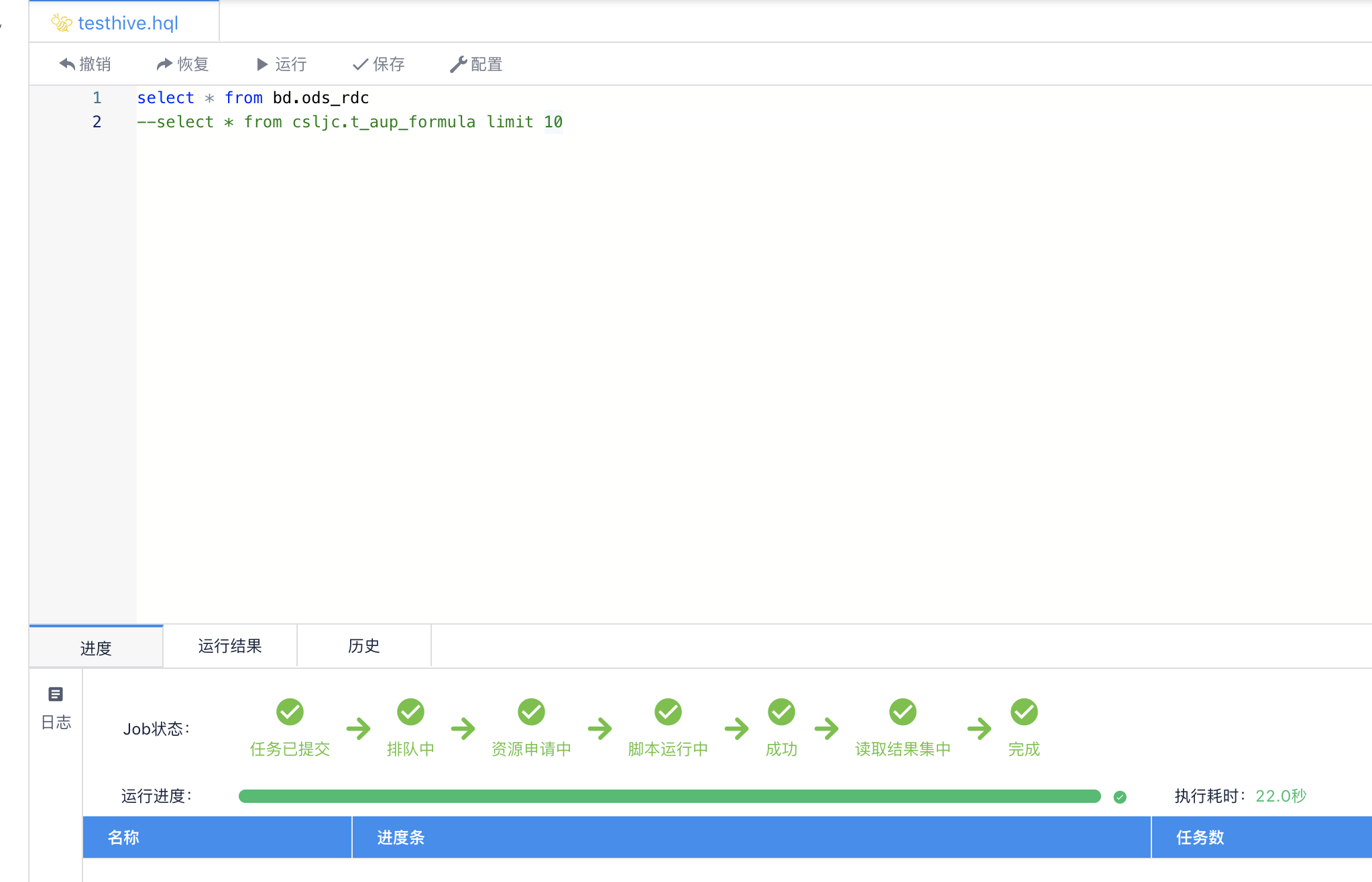
7、体验(hive sql 、spark sql都可以用,权限也能满足需求,scala也可以用,不过没有开启kerberos,不安全)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号