kafka总结
kafka总结
kafka是一个分布式、分区的、多副本的、发布-订阅模式,基于zookeeper协调的分布式日志系统(也可以当做MQ系统)。
主要应用场景是:日志收集系统和消息系统。
kafka角色划分及角色用途。
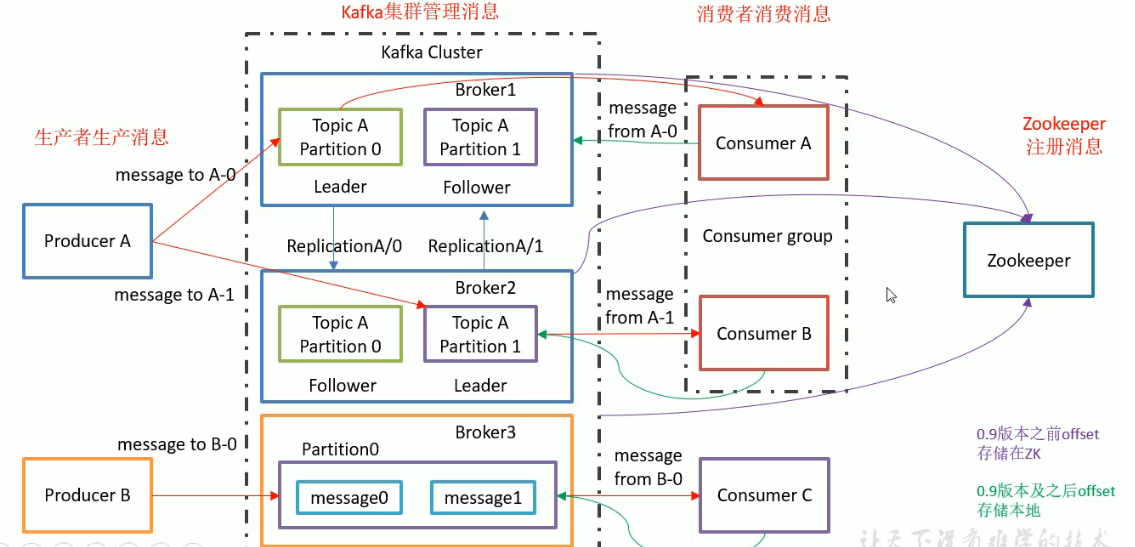
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。 同一消费者组消费者不会重复消费同一消息。
kafka存储到磁盘中文件内容如图:

Kafka中partitions数据一致性:
Kafka中Producer发送消息到Broker,Broker有三种返回方式,分别为noack、leader commit成功就ack、leader和follower同时commit成功才返回ack。第三种方式是数据强一致性。
leader==>负责读写,follower 负责同步,只负责备份。当leader宕机,follower选举出一个leader。保证高可用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号